









 文章介绍了SpanBERT,一种改进的预训练模型,通过新的SpanMask方案和加入SBO训练目标提升性能,尤其是在抽取式问答任务上。实验表明,移除NSP任务并采用连续句子训练效果更佳。训练细节包括动态masking和优化器参数调整。
文章介绍了SpanBERT,一种改进的预训练模型,通过新的SpanMask方案和加入SBO训练目标提升性能,尤其是在抽取式问答任务上。实验表明,移除NSP任务并采用连续句子训练效果更佳。训练细节包括动态masking和优化器参数调整。
SpanBERT: Improving Pre-training by Representing and Predicting Spans
核心点
- 提出了更好的 Span Mask 方案,也再次展示了随机遮盖连续一段字要比随机遮盖掉分散字好;
- 通过加入 Span Boundary Objective (SBO) 训练目标,增强了 BERT 的性能,特别在一些与 Span 相关的任务,如抽取式问答;
- 用实验获得了和 XLNet 类似的结果,发现不加入 Next Sentence Prediction (NSP) 任务,直接用连续一长句训练效果更好。
整体结构
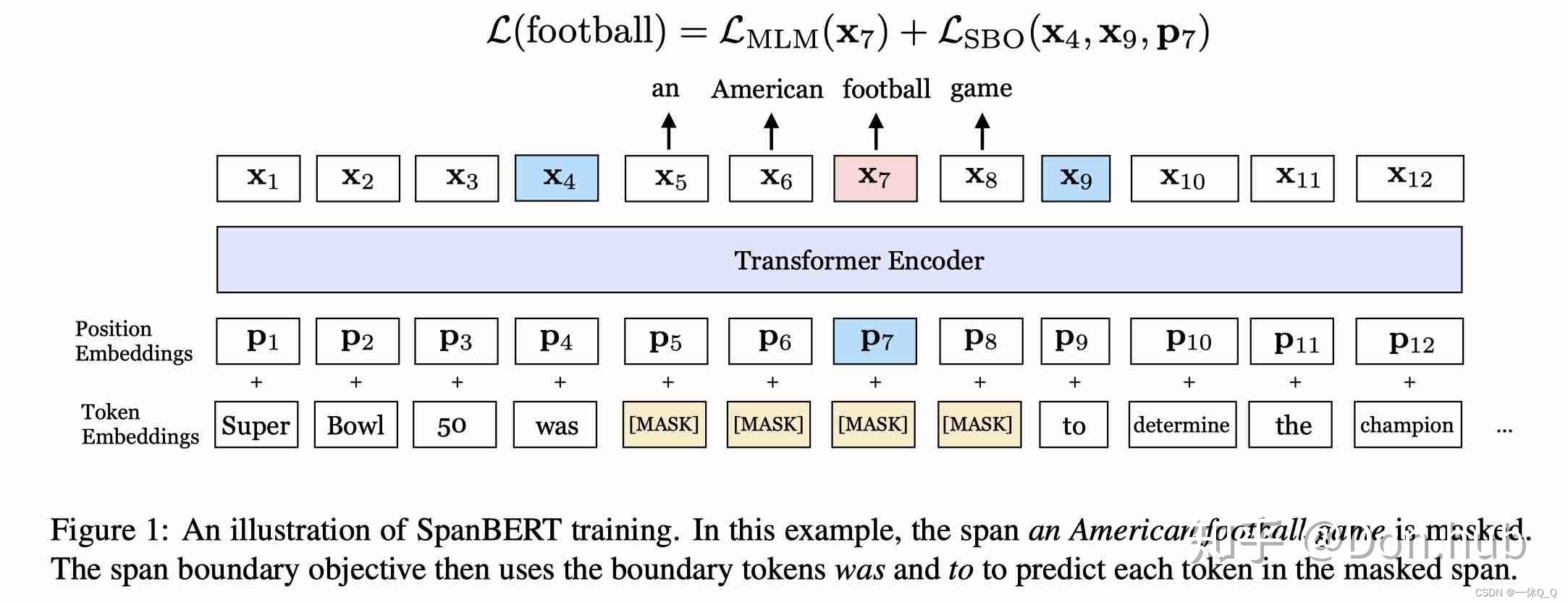
1.Span Masking,SM。根据集合分布,随机选择一段span的长度,之后根据均匀分布随机选择这一段的起始位置,然后按照长度进行遮盖。使用几何分布取p=0.2,最大长度为10,通过采样,平均遮盖长度为3.8个词的长度。
2.SBO span boundary objective ,希望被遮盖span边界的词向量,能学习到span的内容。再训练时,取span前后边界的两个词,用这两个词向量加上span中被遮盖词的位置向量,预测原词。
将词向量和位置向量拼接起来,加两层全连接。使用Gelu函数,并使用正则化。

最后预测span中原值时计算新损失,即SBO目标的损失。将该损失与BERT的MLM损失加起来,一起训练模型。
3.NSP ,Next Sentence Prediction任务,SPanBert没有用NSP,使用Single-Sequence Traing。不加入NSP任务判断是否两句是上下句,直接用一句来训练。
训练细节
- 训练时用了 Dynamic Masking 而不是像 BERT 在预处理时做 Mask;
- 取消 BERT 中随机采样短句的策略;
- 还有对 Adam 优化器中一些参数改变。

















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









