




UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbf in position 0: invalid start byte
在使用jupyter notebook下,操作csv文件的时候报错

上面为代码,下面为报错内容
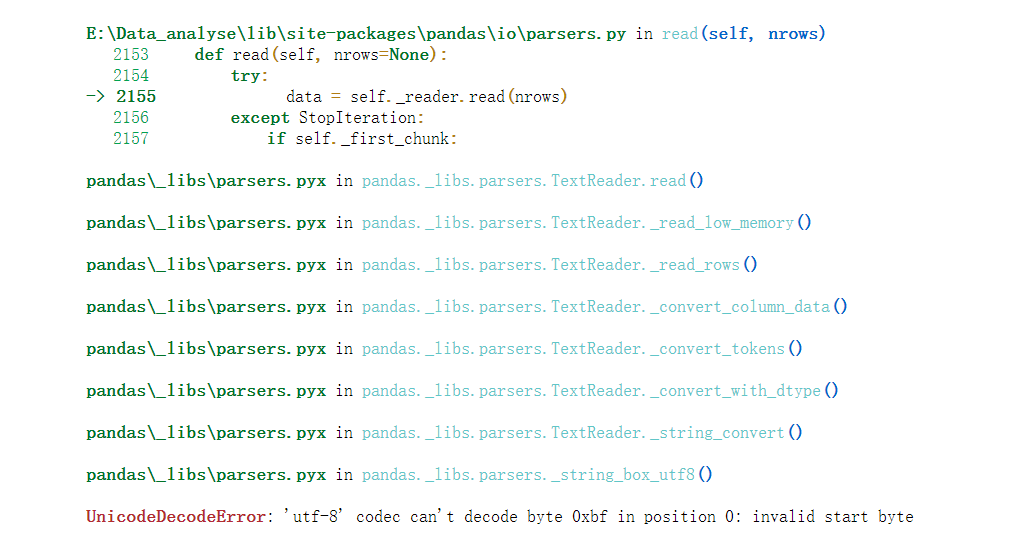
第一时间意识到是编码问题
赶紧加上encoding=‘utf-8’

额…仍然报错。
然后改成encoding=‘gbk’,歪打正着报错解决。
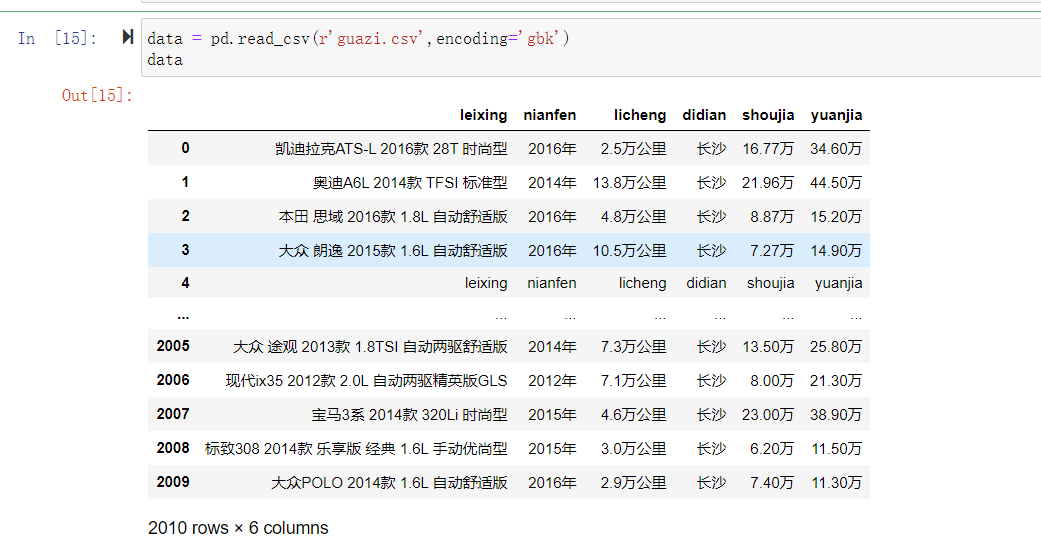
大家可参考一下。
 在Jupyter Notebook中处理CSV文件时遇到UnicodeDecodeError,尝试用'utf-8'和'gbk'编码进行解码。尽管'utf-8'无法解决问题,但切换到'gbk'编码成功解决了报错。这个经验分享对于遇到类似中文编码问题的开发者可能有所帮助。
在Jupyter Notebook中处理CSV文件时遇到UnicodeDecodeError,尝试用'utf-8'和'gbk'编码进行解码。尽管'utf-8'无法解决问题,但切换到'gbk'编码成功解决了报错。这个经验分享对于遇到类似中文编码问题的开发者可能有所帮助。
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xbf in position 0: invalid start byte
在使用jupyter notebook下,操作csv文件的时候报错
上面为代码,下面为报错内容
第一时间意识到是编码问题
赶紧加上encoding=‘utf-8’
额…仍然报错。
然后改成encoding=‘gbk’,歪打正着报错解决。
大家可参考一下。
 1万+
1万+
7611
1824
2万+
2100
6万+
2万+
6410
1万+
1万+
7611
1824
2万+
2100
6万+
2万+
6410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























