



目录
前言
AI 技术演进突飞猛进,多模型协同调用与动态调配已成为 AI 项目的标配。但这种策略背后,隐藏着不容忽视的工程瓶颈:开发团队需为 OpenAI、DeepSeek、Claude、Qwen 等不同平台逐一完成账户注册、API 密钥申请、SDK 适配与接口调试。这不仅推高了项目的集成与长期维护成本,更让开发者在模型切换、效果比对与压力测试中耗费大量精力,严重制约研发效率。打造一套统一化、标准化且具备高扩展性的模型调度中间层,已成为突破 AI 应用开发效能瓶颈的核心诉求。
GMI Cloud 推理引擎凭借前瞻性架构设计,给出了直击痛点的解决方案。平台构建了全场景兼容 OpenAI 规范的统一 API 入口,真正实现 “一个接入端点贯通近百款主流模型”,开发者仅需一套认证凭证与代码规范,就能无缝调用文本、图像、视频等多模态领域的顶尖模型。经过两周的深度集成测试与高并发压力验证,其表现堪称惊艳:基础设施层面,依托 H200 高性能芯片的澎湃算力,已聚合 36 款主流大语言模型(含 DeepSeek、GPT 系列、Qwen、Kimi 等)与 31 款前沿视频生成模型(如 Sora 2、Veo 3.1、Kling V2.5);接口体验上,模型切换仅需修改单个参数,大幅提升研发敏捷性;成本控制方面,细粒度 Token 级计费模式,为项目资源优化与成本管控提供了前所未有的精准度。
一、GMI Cloud 核心能力概览
GMI Cloud 凭借高可靠技术架构与雄厚的 GPU 供应链实力,为企业级 AI 应用筑牢安全高效的算力根基。依托自研的 Cluster Engine 与 Inference Engine 双核心引擎,平台实现了从算力原子化调度(支持 0.1 GPU 粒度动态分配)到业务级智能计算服务的全链路跃迁,核心能力集中体现在以下维度:
高性能 GPU 硬件矩阵
在硬件资源层面,平台整合了 H200、B200 等新一代高性能 GPU 芯片。这些芯片覆盖从大规模模型推理、视频生成到超大型模型预训练、科学计算的全场景需求,为不同类型的 AI 任务提供精准匹配的算力支撑。
| 芯片型号 | 峰值算力 | 关键优势 | 典型应用场景 |
|---|---|---|---|
| H200 | 15.8 TFLOPS | 推理能效提升约 40% | 大规模模型推理、视频生成 |
| B200 | 20.1 PFLOPS | 训练吞吐量显著优化 | 大模型预训练、科学计算 |
全球模型统一接入平台
作为通用人工智能(AGI)基础设施的核心推动者,GMI Cloud 搭建了兼容 ONNX、TensorRT 等 7 种行业标准协议的高性能推理平台。截至 2024 年第三季度,平台已集成 Veo 3.1、Sora 2、Wan 2.5、Kimi K2 Thinking、DeepSeek V3.2、GLM-4.6、GPT OSS 及 Qwen 3 等 97 个主流模型,为企业提供行业领先的模型服务响应效率。
可量化的落地价值
在典型业务场景中,该平台已成功助力某自动驾驶企业将模型推理延迟从 150ms 优化至 23ms,端到端推理效率提升超 80%,显著降低了企业 AI 应用的落地门槛与推理成本。
二、注册体验GMI Cloud
GMI Cloud注册登录
打开 GMI 注册 ,首页右上角点击注册Sign in按钮;完成注册/登录.
领取兑换体验额度
新注册用户即赠优惠码,可兑换免费体验额度:
点击右上角的 $ 0 ,接着会出现 Have a voucher? Redeem it here. 这段字,点击Redeem it here,接着输入兑换码 ACC2025BJ 进行兑换,余额就会变成 $ 2.00。
三、GMI Cloud优势
模型资源丰富多元,一站式覆盖全场景创作需求
本平台聚合海量前沿 AI 模型资源,用户无需在多平台间切换,仅需一个界面即可便捷调用、对比各类顶尖模型,大幅提升创意工作的效率与体验。平台将模型划分为 LLM(大语言模型)、Video(视频生成)、Image(图像生成)、Audio(音频)、3D 五大类别分组,使用逻辑更清晰。
- 大语言模型(LLM):共提供 36 款主流与前沿模型,覆盖维度极为全面。既包含 DeepSeek、Qwen、GLM 等国产头部模型,也纳入 GPT、Claude、Gemini 等国外知名系列,更同步集成 Kimi-K2-Thinking 等最新迭代模型。每款模型均清晰标注上下文长度、函数调用等功能支持及价格信息,用户无需跨平台检索即可高效完成模型对比与选型,极大降低决策成本。
- 视频生成模型:集成 31 款模型,除 Sora 2、Veo 3.1 等国际主流模型外,还涵盖 Kling V2.5、Wan 2.5、Minimax-Hailuo 2.3 等优质国产模型,并明确标注文生视频、图生视频等支持类型,便于用户直观筛选适配场景。
- 图像生成模型:虽数量相对精简,但质量表现出众。Flux 系列、Seedream 系列、Seededit 系列完整覆盖从图像从零生成到编辑优化的全流程场景,可充分满足多样化创作需求。
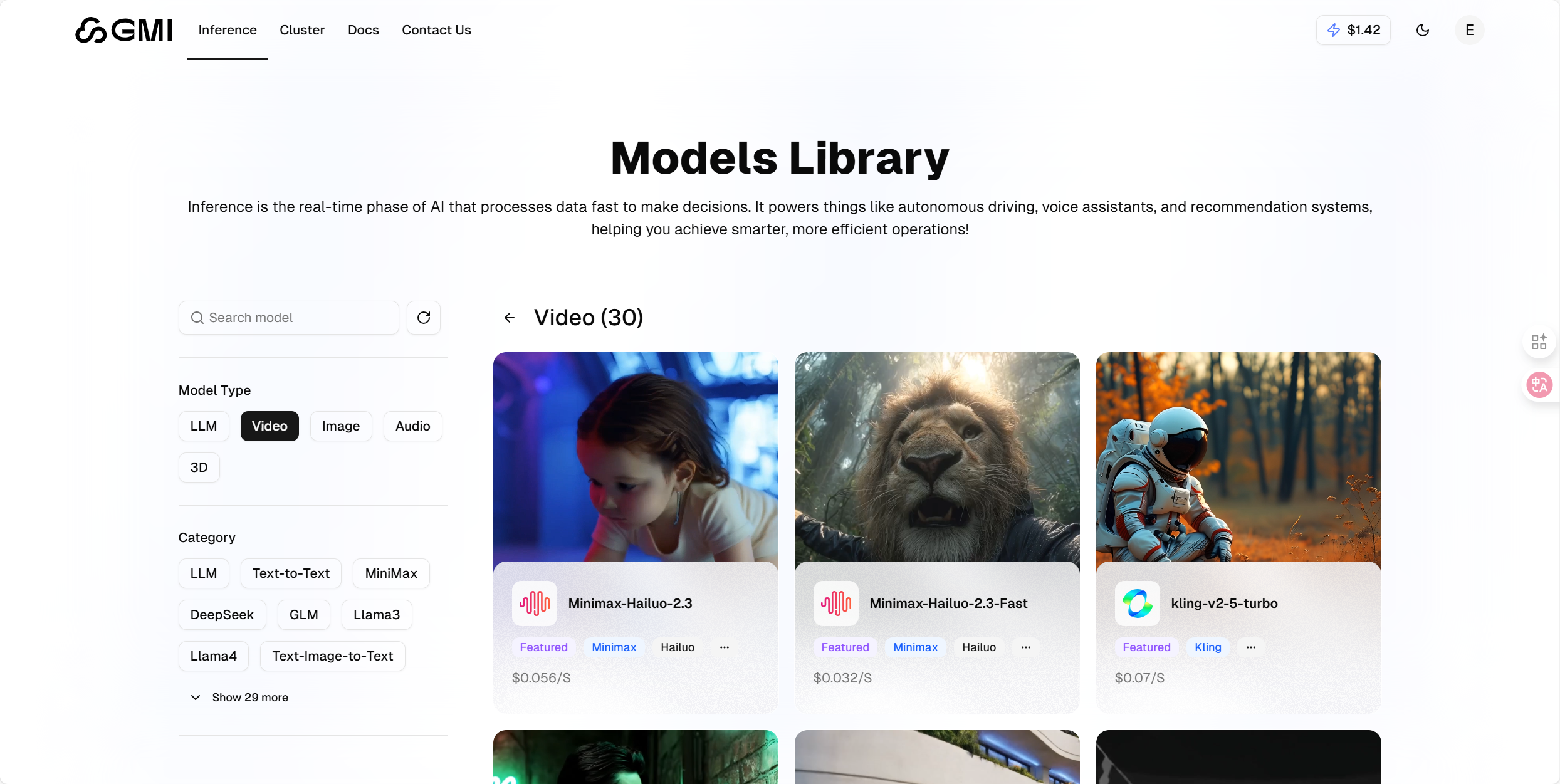
视频生成模型
- 模型阵容丰富多元:累计集成 32 款优质视频生成模型,既囊括 Sora 2、Veo 3.1 等国际主流模型,也收录 Kling V2.5、Wan 2.5、Minimax-Hailuo 2.3 等实力出众的国产模型,覆盖不同技术路线与性能层级。
- 功能定位清晰直观:覆盖文生视频、图生视频及复合功能等多样化生成场景,界面按功能维度分类规整,助力用户快速锁定适配模型,降低操作成本。
图像生成模型
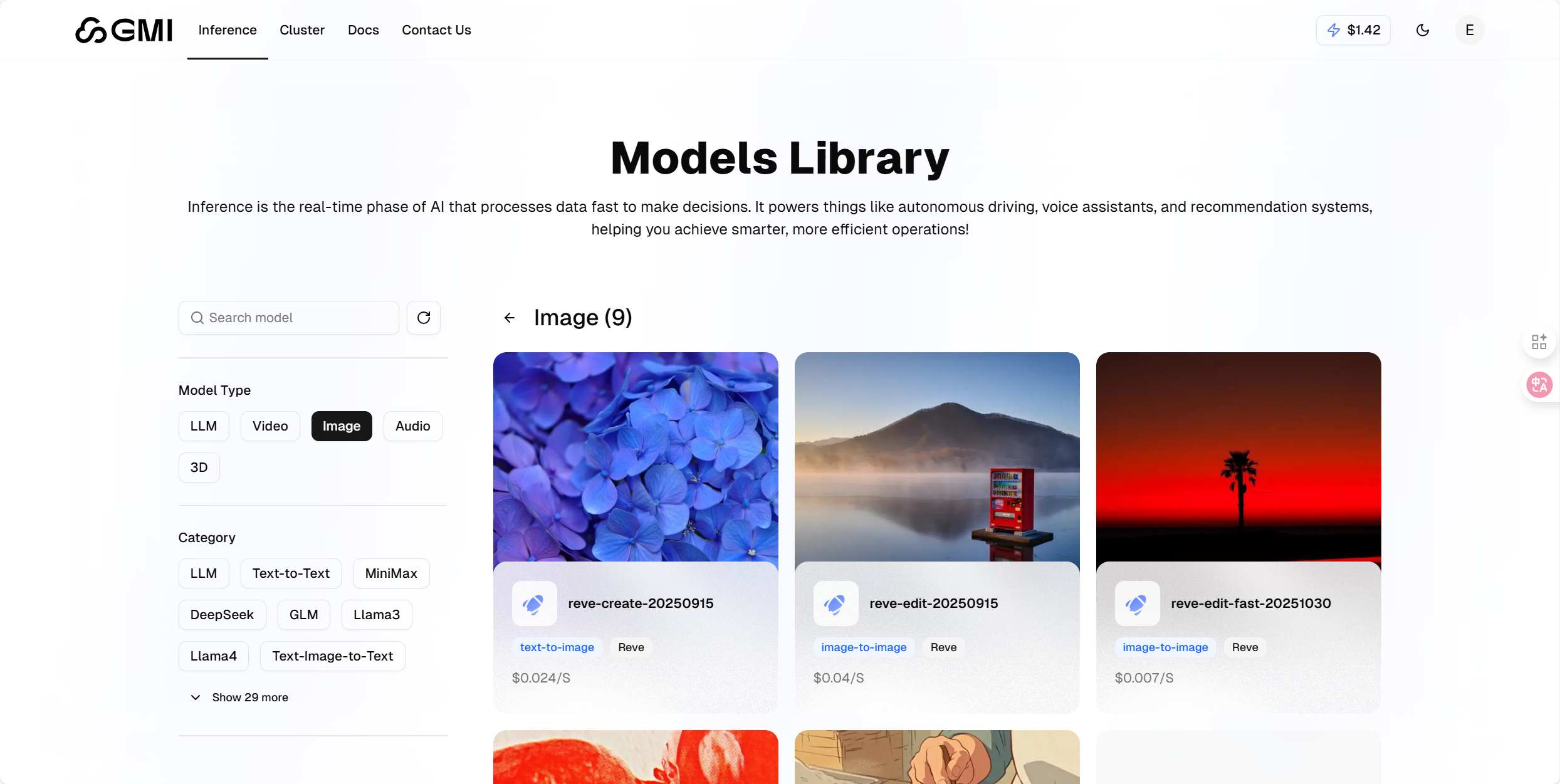
- 精选优质模型矩阵:数量虽相对精简,但均为行业优质水准,囊括 Flux 系列、Seedream 系列、Seededit 系列等口碑模型。
- 功能覆盖全面:完整覆盖图像从零生成、专业编辑优化等全链路创作场景,充分适配不同创意需求。
技术领先,一站式赋能高效开发
-
底层算力强劲,集成体验拉满平台依托 H100/H200 高性能芯片搭建底层算力架构,聚合近百款前沿 AI 模型,全面覆盖视频生成、大语言交互、图像创作等核心场景。更关键的是,所有模型均接入统一 API 体系,开发者无需重复完成平台注册、密钥申请或接口适配工作,大幅提升研发效率与代码复用率,同时显著降低长期维护成本。
-
前沿模型同步快,技术迭代不脱节平台的模型更新速度极具优势 —— 诸如 Minimax Hailuo 2.3、Kimi-K2-Thinking 等新晋热门模型,往往在官方发布后数日内便完成平台集成上线。这让技术驱动型项目能第一时间用上行业最新能力,无需为等待模型适配耗费额外时间。
-
成本精细化管控,预算管理无忧采用 Token 级精准计费模式,后台可实时查看每一次模型调用的详细消耗明细,清晰掌握成本去向。同时支持自定义预算预警设置,能及时触发超额提醒,帮助团队实现成本可控,有效规避意外超支风险。
-
团队实力过硬,服务稳定可靠平台由 Google X AI 领域专家与硅谷核心团队联合打造,且作为 NVIDIA 全球六大参考平台云合作伙伴,可优先获取 GPU 算力资源支持。搭配全球分布式数据中心架构,API 平均响应速度稳定在 1–3 秒,视频生成任务耗时仅需 1–3 分钟,其服务稳定性与性能表现完全满足企业级项目需求。
四、在线使用模型
生成 Keys 秘钥
点击步骤1,然后点击步骤2的API Keys:
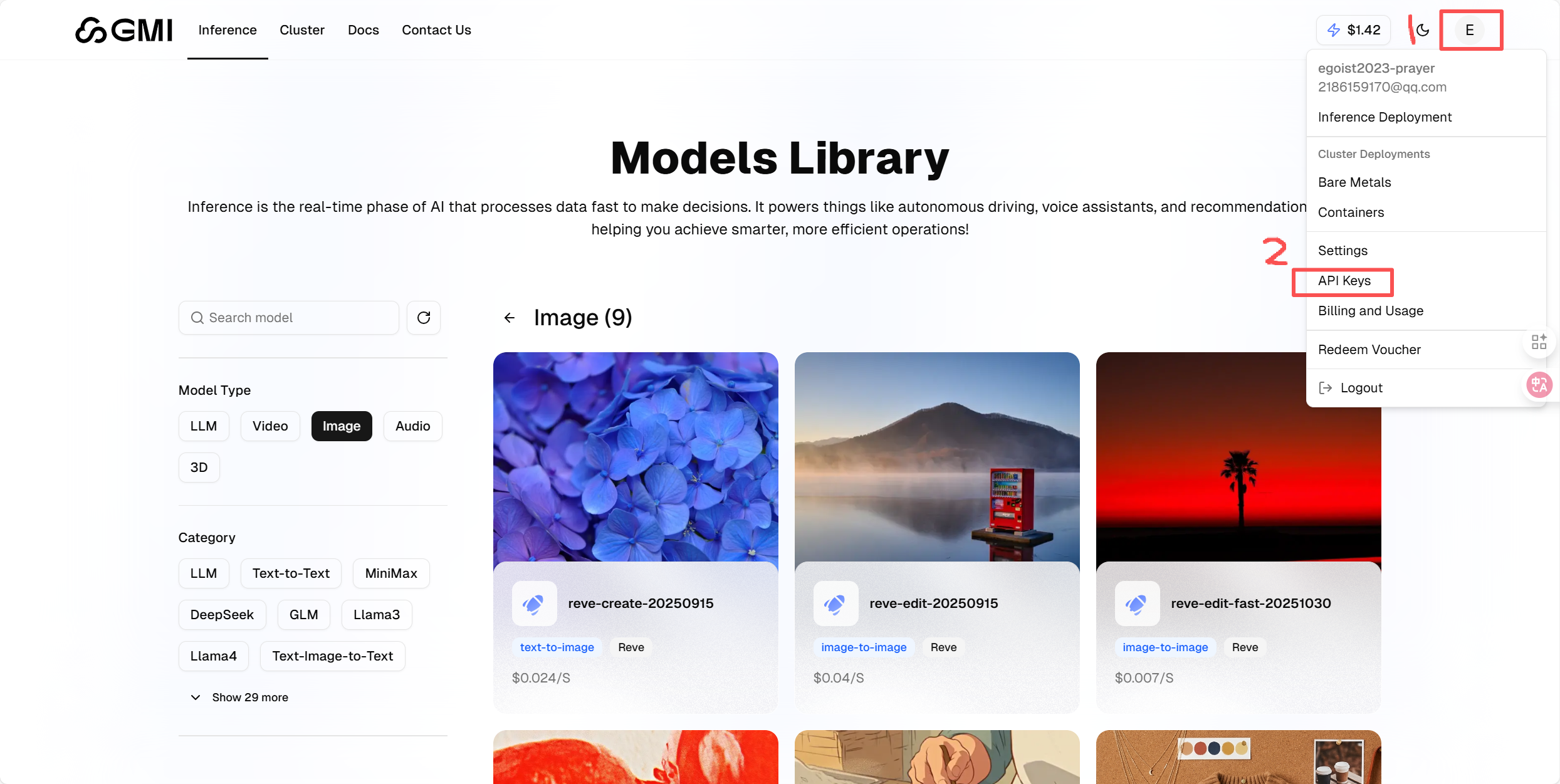
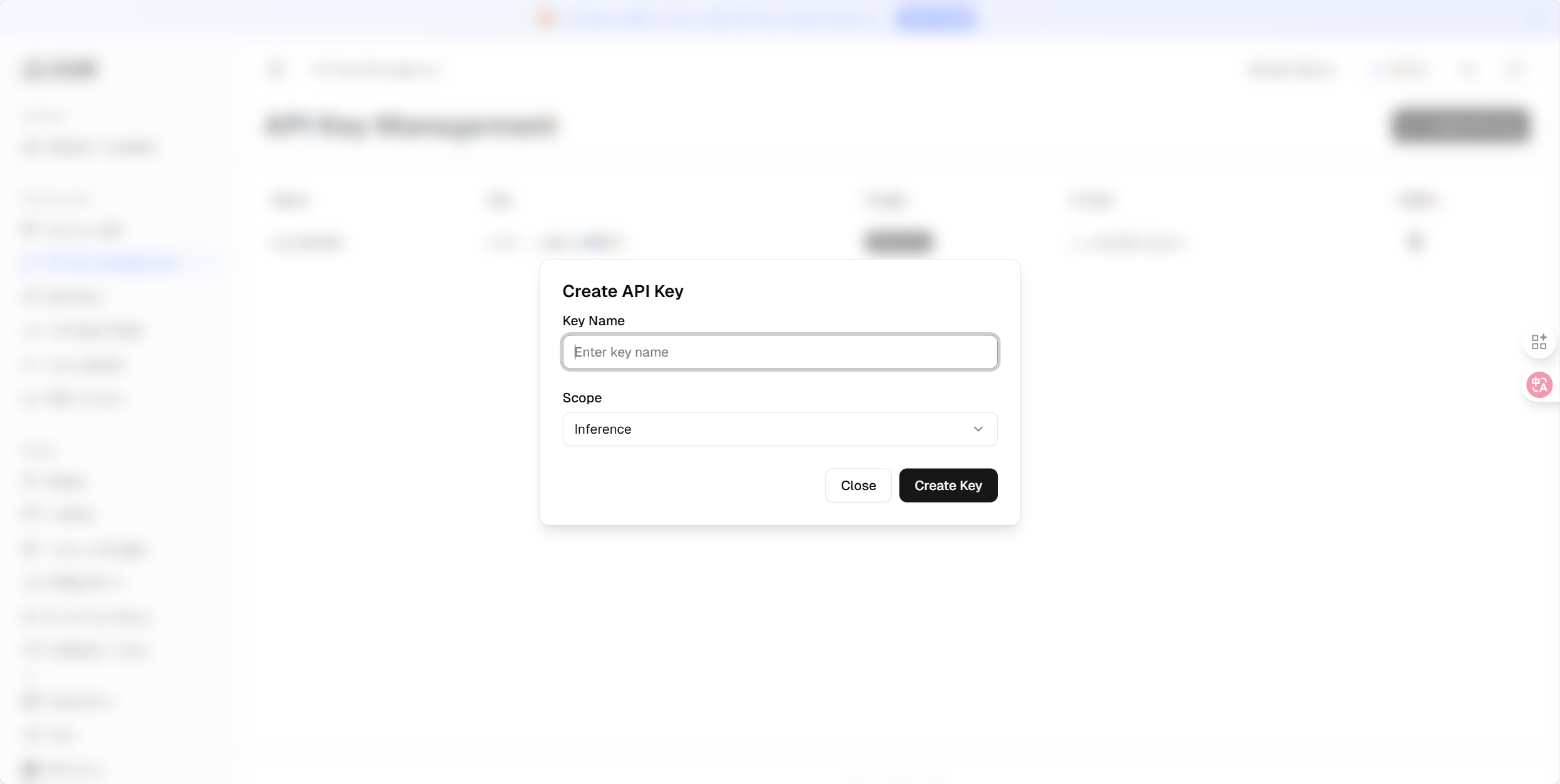
点击「Create New API Key」按钮,先为密钥设置一个便于识别的名称,再根据需求配置权限范围 —— 比如仅开放文本模型调用权限,或设置为只读模式(禁止写入操作)。需特别注意,该密钥仅在创建时显示一次,生成后请立即复制并妥善保存。
测试大语言模型
可以选择自身想测的模型,这里以 Kimi-K2-Thinking 为例:
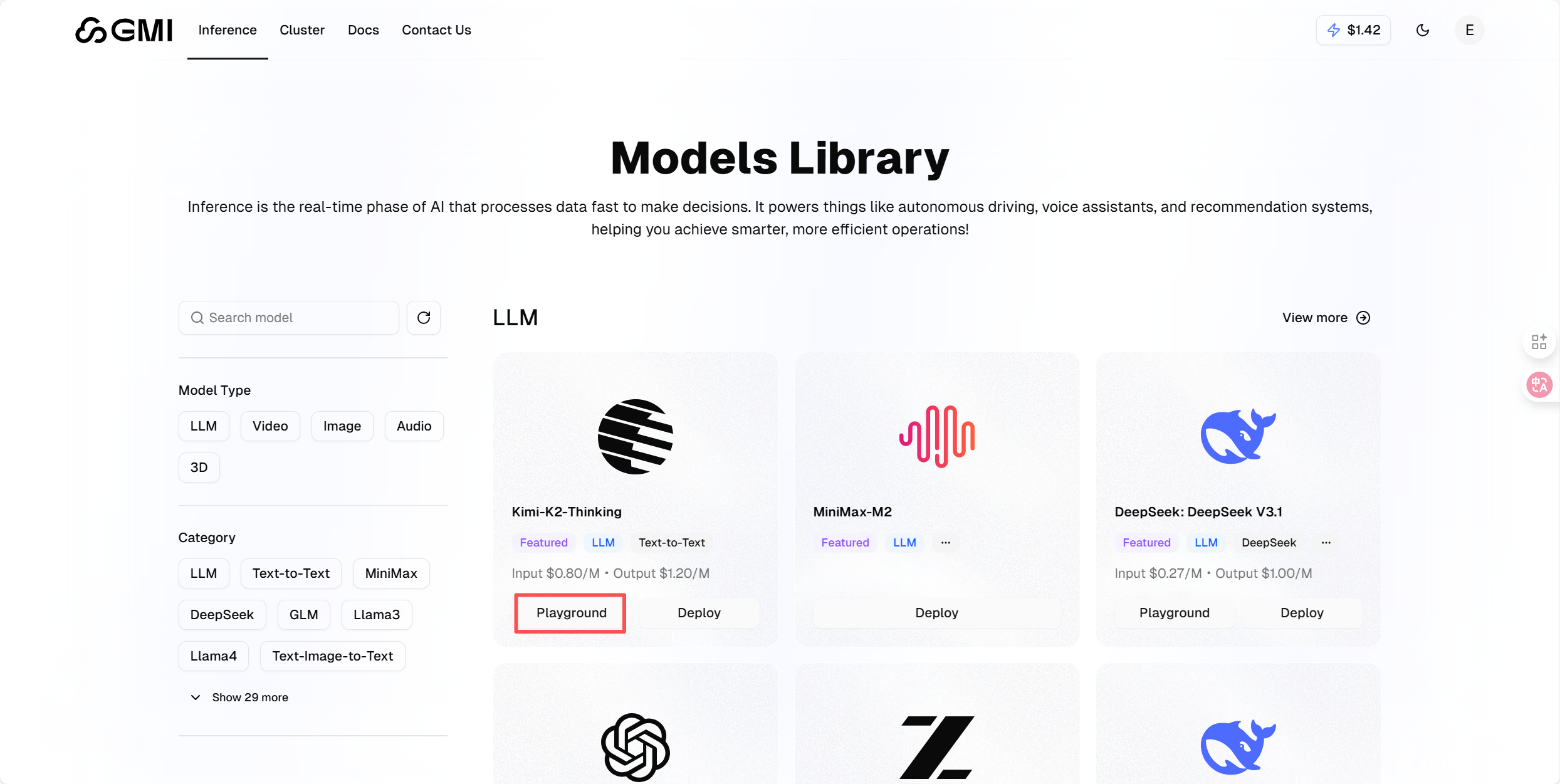
点击 Kimi-K2-Thinking 的"Playground"标签
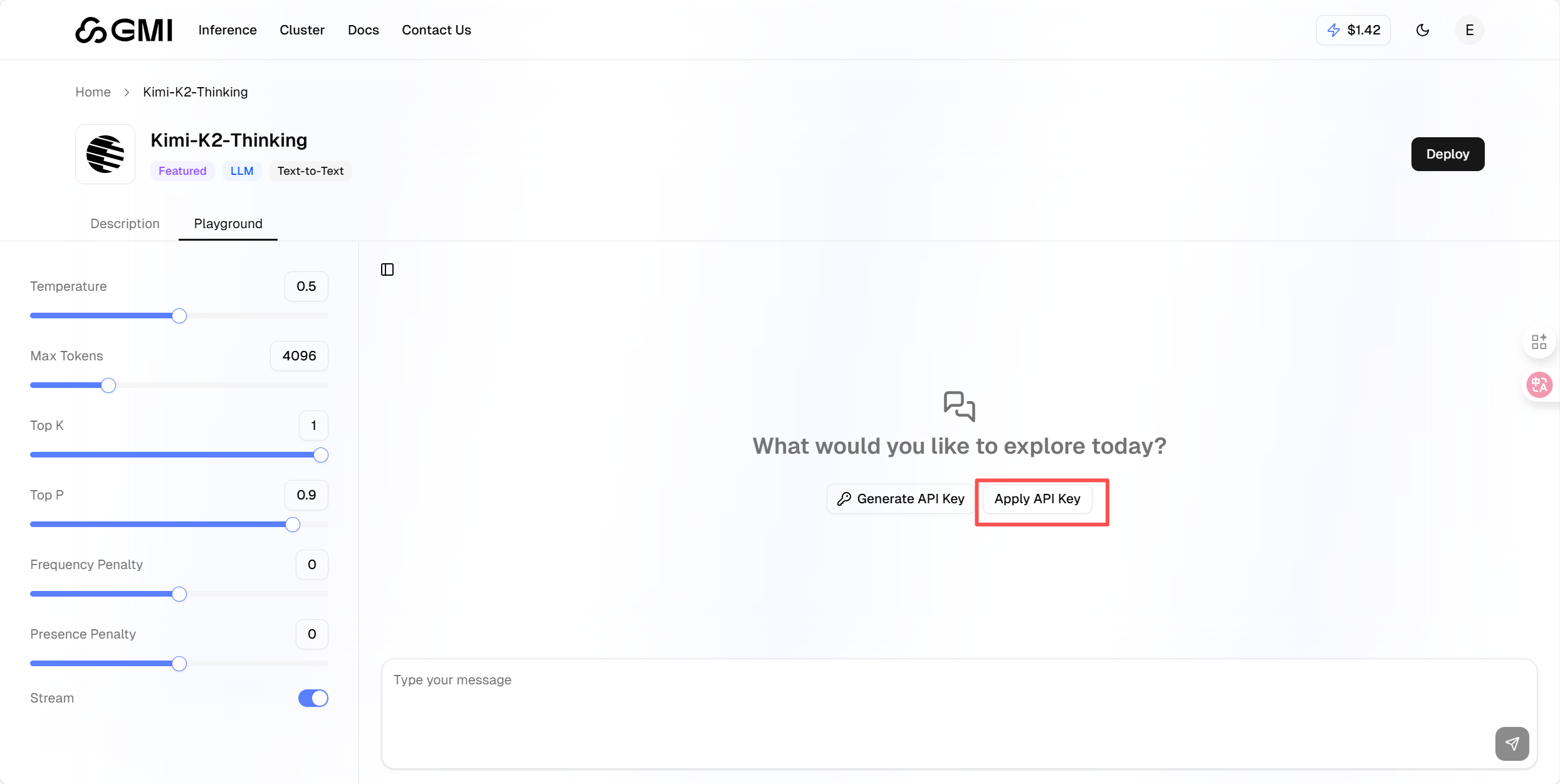
点击Apply API Key,将之前复制的API输入进去,就可以使用模型了.
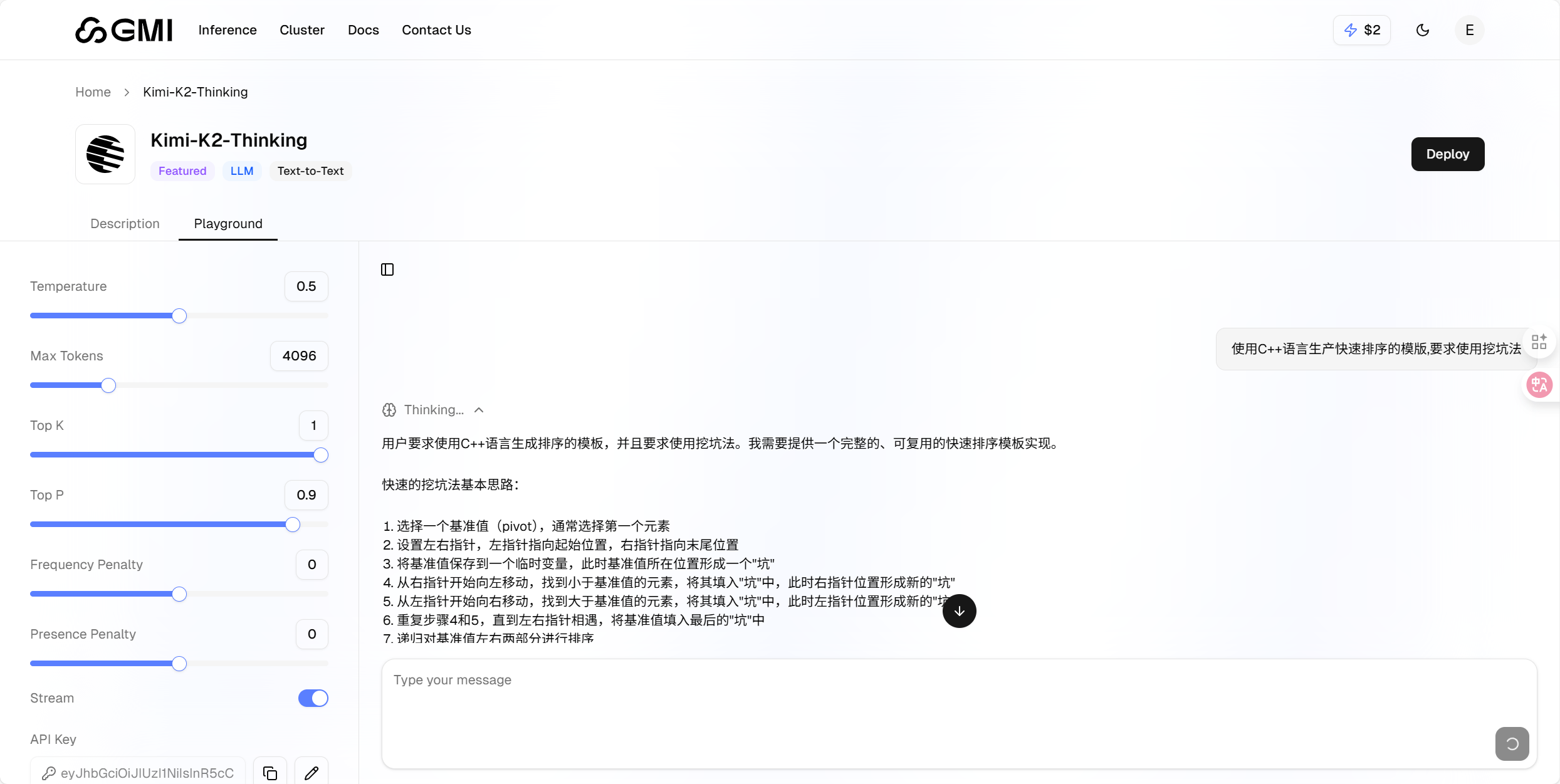
平台返回的结果精准度很高,左侧还配置了多个实用可调参数 —— 既能通过调节温度值控制回复的随机性,也能自定义设置最大令牌数限制输出长度,灵活适配不同使用需求。
生成AI视频
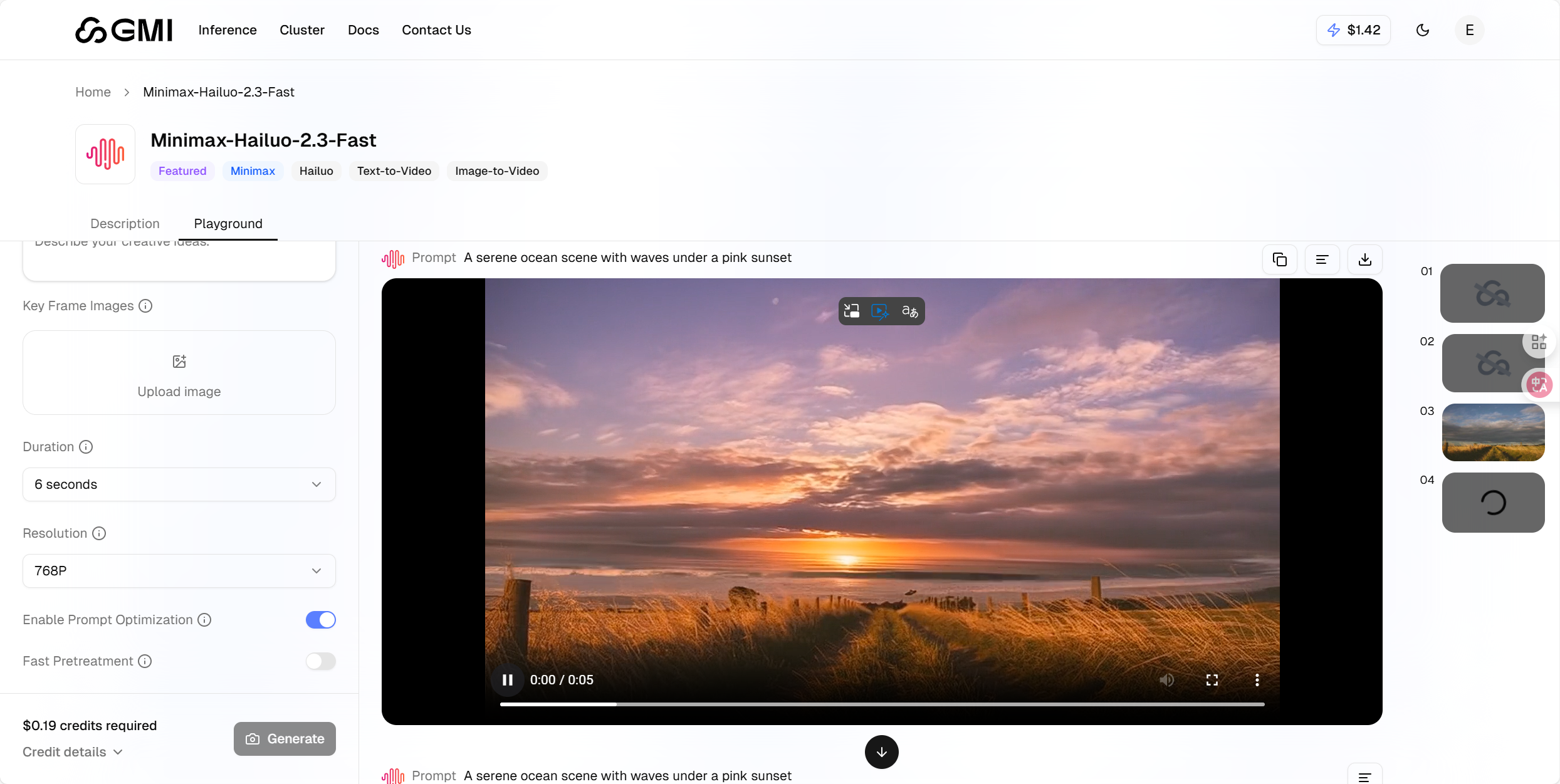
菜单选择"Video"分类,这里以 Minimax-Hailuo-2.3 为例:
点击进入模型页面,可以上传一张图片作为首帧或参考,Duration 和 Resolution 用来自主选择时长和分辨率。并可以写提示词,我写了如下提示词:
"粉色头发的女孩戴着耳机,坐在房间地板上弹奏黑色电吉他,左手按弦右手拨弦动作连贯自然,吉他弦随弹奏轻微震动,周围环境灯光柔和,保持原插画风格".
参数设置好后,点击"Generate"按钮,等待视频生成。
原图:

图片动起来的效果:

大家感兴趣就自己来体验呀!
五、一键调用API 模型
怎样调用
首先启动此前用过的 Kimi-K2-Thinking 模型,点击「Description」选项 —— 这里会呈现详细的调用指引,这里我们以Python为例:
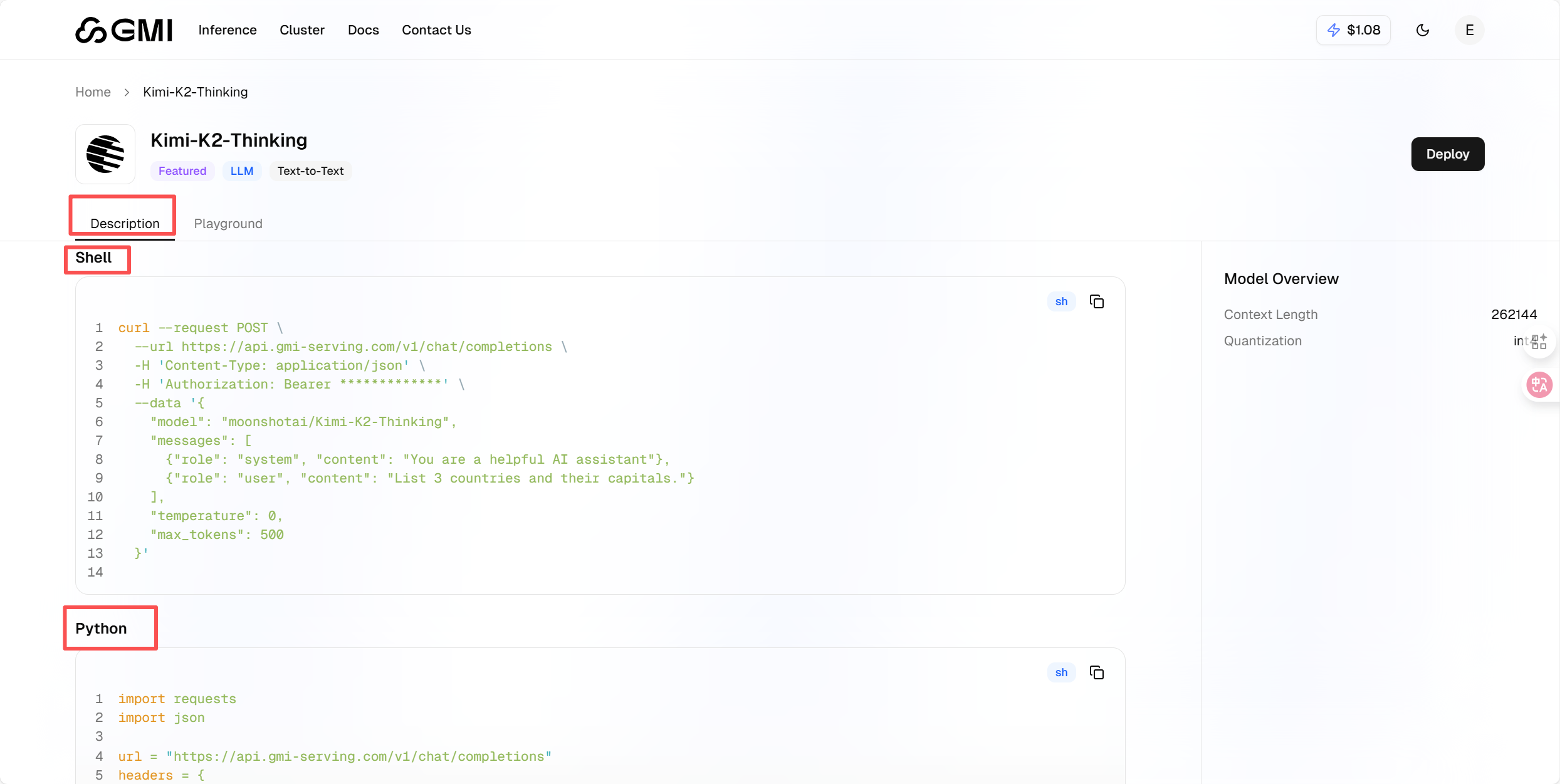
复制Python的代码块的内容,
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer *************"
}
payload = {
"model": "moonshotai/Kimi-K2-Thinking",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."}
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
print(json.dumps(response.json(), indent=2))
Bearer ************* 改为自己的 API Keys 秘钥,输入完成后点击运行,系统会返回结构化 JSON 输出 —— 格式规整、兼容性强,能被 Python、Java、JavaScript 等各类编程语言及不同系统便捷解析,这标志着 API 调用已成功落地。
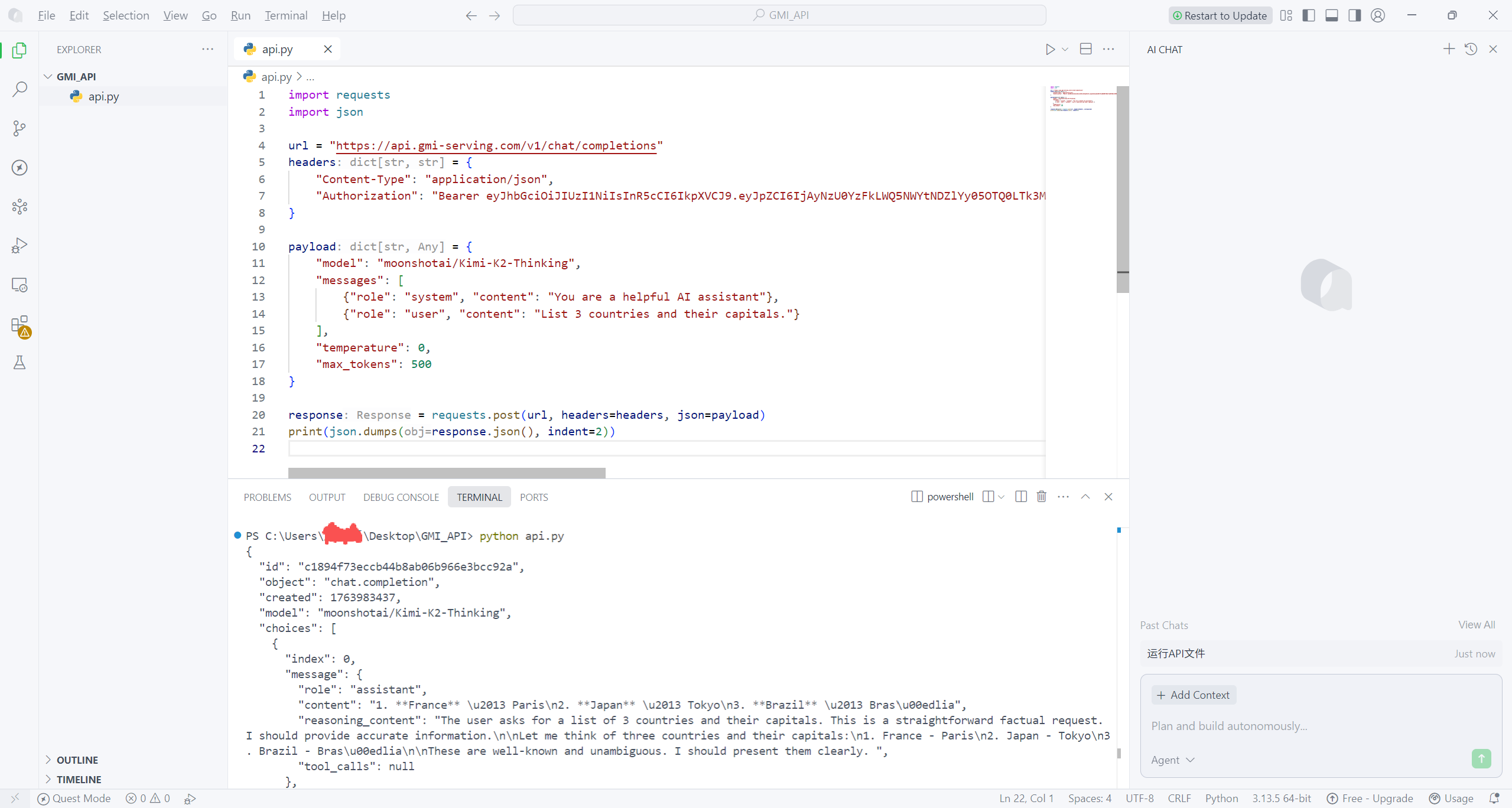
本地部署LLM模型
为了后续能便捷引用自身提问,同时避免每次修改问题时都需改动复杂的代码结构,我将原本直接嵌入 messages 中的提问内容单独抽离,定义了 user_question 变量。如此一来,后续若需更换提问,仅需修改 user_question 这一行代码,无需调整整体代码框架,代码的灵活性与可维护性均得到显著提升。
原代码仅打印 API 返回的完整 JSON 数据,不仅视觉上杂乱无章,还无法直观关联原始提问,输出效果不够友好。对此,我做了针对性优化:首先从响应数据中精准提取 AI 的核心回复内容并存储至变量;接着采用格式化输出方式,先明确打印 “你的问题:” 及对应的提问文本,换行后再打印 “AI 的回答:” 及提取后的核心回复。这样既实现了提问与回答的一一对应,让输出结果清晰直观,也更契合实际查看需求。具体优化后的代码如下:
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer ........"
}
# 提问内容
user_question = "怎么去写作"
payload = {
"model": "moonshotai/Kimi-K2-Thinking",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": user_question} # 引用提问内容
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
response_data = response.json()
# 提取 AI 的回答
ai_answer = response_data['choices'][0]['message']['content']
# 同时打印问题和回答
print(f"你的问题:{user_question}")
print("\nAI 的回答:")
print(ai_answer)
各模型的具体调用指南均可在对应模型详情页查询,大家可根据实际需求选择调用。接下来,就为大家演示视频模型的详细调用流程。
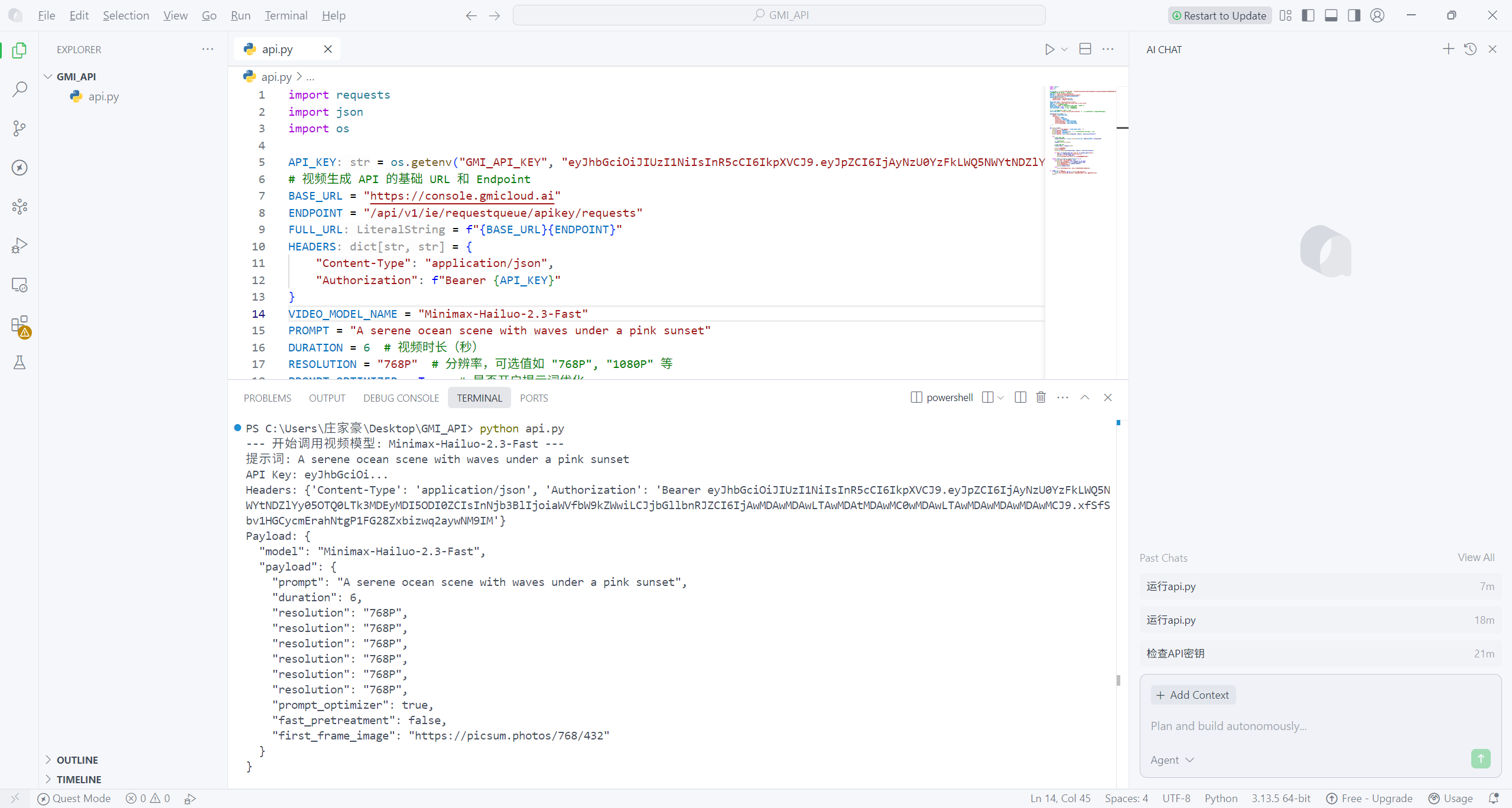
本地部署视频模型
借鉴 LLM 模型的封装思路,我们可对视频生成 API 的调用逻辑进行标准化封装,让它在本地项目中更便于复用和后续维护。下面提供一个结构化的封装示例,大家能直接落地到项目中,示例中我选择调用的是 Minimax-Hailuo-2.3-Fast 模型。
import requests
import json
import os
API_KEY = os.getenv("GMI_API_KEY", "........") # 写下自己的 API Keys 秘钥
# 视频生成 API 的基础 URL 和 Endpoint
BASE_URL = "https://console.gmicloud.ai"
ENDPOINT = "/api/v1/ie/requestqueue/apikey/requests"
FULL_URL = f"{BASE_URL}{ENDPOINT}"
HEADERS = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
VIDEO_MODEL_NAME = "Minimax-Hailuo-2.3-Fast"
PROMPT = "A serene ocean scene with waves under a pink sunset"
DURATION = 6 # 视频时长(秒)
RESOLUTION = "768P" # 分辨率,可选值如 "768P", "1080P" 等
PROMPT_OPTIMIZER = True # 是否开启提示词优化
FAST_PRETRATMENT = False # 是否开启快速预处理
# 使用一个公共可用的图像URL作为测试
FIRST_FRAME_IMAGE = "https://picsum.photos/768/432" # 一个随机的768x432图像(符合768P分辨率)
payload = {
"model": VIDEO_MODEL_NAME,
"payload": {
"prompt": PROMPT,
"duration": DURATION,
"resolution": RESOLUTION,
"prompt_optimizer": PROMPT_OPTIMIZER,
"fast_pretreatment": FAST_PRETRATMENT,
"first_frame_image": FIRST_FRAME_IMAGE
}
}
def main():
print(f"--- 开始调用视频模型: {VIDEO_MODEL_NAME} ---")
print(f"提示词: {PROMPT}")
print(f"API Key: {API_KEY[:10]}...") # 显示API密钥的前10个字符用于验证
print(f"Headers: {HEADERS}")
print(f"Payload: {json.dumps(payload, indent=2, ensure_ascii=False)}")
try:
# 发送 POST 请求
response = requests.post(FULL_URL, headers=HEADERS, json=payload)
# 检查响应状态码
response.raise_for_status()
# 解析 JSON 响应
response_data = response.json()
print("\n请求成功!")
print("完整响应:")
print(json.dumps(response_data, indent=2, ensure_ascii=False))
if "data" in response_data and "task_id" in response_data["data"]:
task_id = response_data["data"]["task_id"]
print(f"\n任务 ID: {task_id}")
print("请保存此 Task ID,用于后续查询视频生成状态。")
except requests.exceptions.RequestException as e:
print(f"\n调用 API 时发生错误: {e}")
if hasattr(e, 'response') and e.response is not None:
print("错误响应状态码:", e.response.status_code)
print("错误响应头:", e.response.headers)
print("错误响应内容:")
print(e.response.text)
else:
print("没有收到响应,请检查网络连接或API端点是否正确。")
if __name__ == "__main__":
if API_KEY == "你的API" and not os.getenv("GMI_API_KEY"):
print("警告: 请设置 GMI_API_KEY 环境变量或在代码中替换 '你的API密钥'。")
main()提示词为:A serene ocean scene with waves under a pink sunset。
当我们在前端查看该视频时,可以发现是非常逼真的:
六、总结
经过两周的深度实测,GMI Cloud 的整体表现让人十分满意,其核心价值集中体现在开发效率与使用便捷性的双重提升上。过去接入新模型,总要经历注册平台、研读文档、编写适配代码等繁琐步骤,耗时又费力;而现在只需一个账号、一套密钥,就能调用平台所有模型,基础代码编写一次即可,切换模型仅需修改名称参数,大幅减少重复工作量。
平台聚合了 36 款文本模型与 31 款视频模型,全面覆盖各类主流使用场景;更值得一提的是,新模型上线速度极快,往往在官方发布后不久就能在平台上体验到,让用户紧跟技术前沿。计费方式上采用按 Token 精准计费,每一次调用的消耗明细都清晰可查;不同模型虽有价格差异,但整体均处于合理区间,成本可控性极强。非常推荐有相关需求的朋友亲自体验一番!
1. 统一操作体系,简化开发全流程
平台以单账号、单密钥实现全模型统一管理,彻底摒弃了以往为不同模型重复注册、查阅文档、编写适配代码的繁琐流程。基础代码一次编写即可复用,模型切换仅需调整名称参数,显著降低开发与维护成本。
2. 模型资源完备,前沿能力同步快
36 款文本模型与 31 款视频模型的丰富储备,全面覆盖当前主流使用需求。新模型上线响应迅速,确保用户能第一时间接入前沿技术,无需为适配新能力等待漫长周期。
3. 计费透明精准,成本管理高效
采用按 Token 计费模式,所有调用消耗明细实时可查,无任何隐藏费用。不同模型价格虽有差异,但整体处于合理区间,配合详细的用量统计,助力团队实现精细化成本管控,避免意外超支。


















 785
785











 到【灌水乐园】发言
到【灌水乐园】发言







