




 本文深入探讨了RocketMQ作为消息中间件的核心优势,包括灵活扩展性、海量消息堆积能力和顺序消息支持等。相较于RabbitMQ和Kafka,RocketMQ在事务消息、延迟消息等方面具备独特优势。此外,文章详细解析了RocketMQ的四大组件——Name Server、Broker、Producer和Consumer的工作原理,强调了其在分布式系统中的关键作用。
本文深入探讨了RocketMQ作为消息中间件的核心优势,包括灵活扩展性、海量消息堆积能力和顺序消息支持等。相较于RabbitMQ和Kafka,RocketMQ在事务消息、延迟消息等方面具备独特优势。此外,文章详细解析了RocketMQ的四大组件——Name Server、Broker、Producer和Consumer的工作原理,强调了其在分布式系统中的关键作用。
一、 MQ背景
消息队列作为高并发系统的核心组件之一,能够帮助业务系统解构提升开发效率和系统稳定性。主要具有以下优势:
削峰填谷(主要解决瞬时写压力大于应用服务能力导致消息丢失、系统奔溃等问题)
系统解耦(解决不同重要程度、不同能力级别系统之间依赖导致一死全死)
提升性能(当存在一对多调用时,可以发一条消息给消息系统,让消息系统通知相关系统)
蓄流压测(线上有些链路不好压测,可以通过堆积一定量消息再放开来压测)
二、RocketMQ 简介
RocketMQ 是阿里巴巴在2012年开源的分布式消息中间件,目前已经捐赠给 Apache 软件基金会,并于2017年9月25日成为 Apache 的顶级项目。作为经历过多次阿里巴巴双十一这种“超级工程”的洗礼并有稳定出色表现的国产中间件,以其高性能、低延时和高可靠等特性近年来已经也被越来越多的国内企业使用。其主要特点有:
1、灵活可扩展性
RocketMQ 天然支持集群,其核心四组件(Name Server、Broker、Producer、Consumer)每一个都可以在没有单点故障的情况下进行水平扩展。
2、海量消息堆积能力
RocketMQ 采用零拷贝原理实现超大的消息的堆积能力,据说单机已可以支持亿级消息堆积,而且在堆积了这么多消息后依然保持写入低延迟。
3、支持顺序消息
可以保证消息消费者按照消息发送的顺序对消息进行消费。顺序消息分为全局有序和局部有序,一般推荐使用局部有序,即生产者通过将某一类消息按顺序发送至同一个队列来实现。
4、多种消息过滤方式
消息过滤分为在服务器端过滤和在消费端过滤。服务器端过滤时可以按照消息消费者的要求做过滤,优点是减少不必要消息传输,缺点是增加了消息服务器的负担,实现相对复杂。消费端过滤则完全由具体应用自定义实现,这种方式更加灵活,缺点是很多无用的消息会传输给消息消费者。
5、支持事务消息
RocketMQ 除了支持普通消息,顺序消息之外还支持事务消息,这个特性对于分布式事务来说提供了又一种解决思路。
6、回溯消费
回溯消费是指消费者已经消费成功的消息,由于业务上需求需要重新消费,RocketMQ 支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯。
三、目前主流的MQ & Rocketmq优势
主流MQ有Rocketmq、kafka、Rabbitmq等
Rocketmq相比于Rabbitmq、kafka具有主要优势特性有:
• 支持事务型消息(消息发送和DB操作保持两方的最终一致性,rabbitmq和kafka不支持)
• 支持结合rocketmq的多个系统之间数据最终一致性(多方事务,二方事务是前提)
• 支持18个级别的延迟消息(rabbitmq和kafka不支持)
• 支持指定次数和时间间隔的失败消息重发(kafka不支持,rabbitmq需要手动确认)
• 支持consumer端tag过滤,减少不必要的网络传输(rabbitmq和kafka不支持)
• 支持重复消费(rabbitmq不支持,kafka支持)
四、原理分析
RocketMQ 核心的四大组件 Name Server、Broker、Producer、Consumer
分布图如下
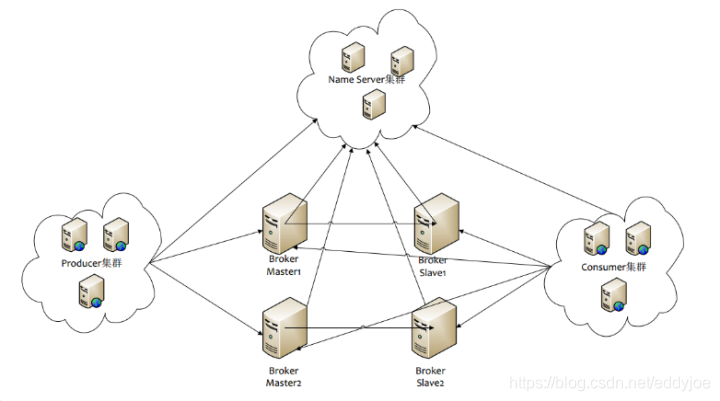
1)Name Server
- Name Server是RocketMQ的寻址服务。用于把Broker的路由信息做聚合。客户端依靠Name Server决定去获取对应topic的路由信息,从而决定对哪些Broker做连接。
- Name Server是一个几乎无状态的结点,Name Server之间采取share-nothing的设计,互不通信。
- 对于一个Name Server集群列表,客户端连接Nam
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1318
1318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









