




 Apache Pulsar是一款云原生的企业级发布订阅消息系统,具备多租户、灵活消息模型及高性能等特性。它采用计算与存储分离的架构,支持跨地域复制,能够为Yahoo等大型应用提供支持。
Apache Pulsar是一款云原生的企业级发布订阅消息系统,具备多租户、灵活消息模型及高性能等特性。它采用计算与存储分离的架构,支持跨地域复制,能够为Yahoo等大型应用提供支持。
Pulsar介绍
Apache Pulsar 是一个云原生企业级的发布订阅(pub-sub)消息系统,于2016年开源,Apache软件基金会顶级开源项目。Pulsar在Yahoo的生产环境运行了三年多,助力Yahoo的主要应用,如Yahoo Mail、 Yahoo Finance、Yahoo Sports、Flickr、Gemini广告平台和Yahoo分布式键值存储系统Sherpa
Pulsar的功能与特性
多租户模式(Multi-tenancy)
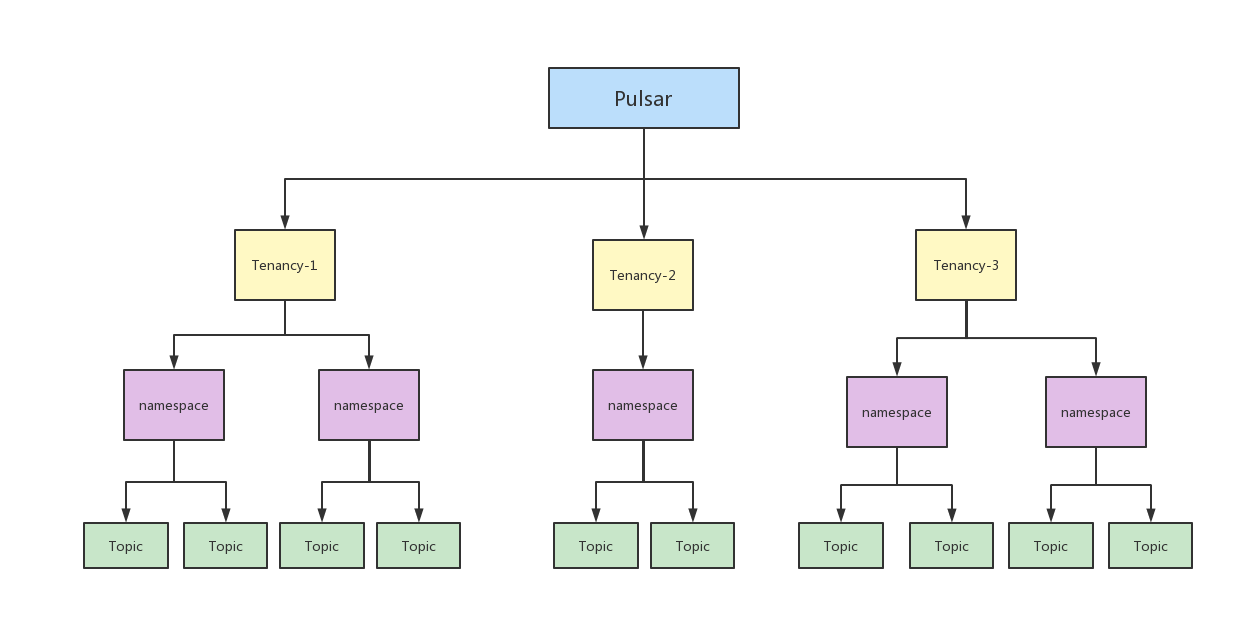
- Pulsar能为特定的租户预留合适的存储空间、应用授权与认证机制
- 一个租户中可以由多个命名空间
- Pulsar在命名空间层中,有一系列配置策略(policy),包括存储配额、流量监控、消息过期策略和不同命名空间的隔离策略。
优点:
-
多租户技术可以实现多个租户之间共享系统实例,同时又可以实现租户的系统实例的个性化定制。
-
通过使用多租户技术可以保证系统共性的部分被共享,个性的部分被单独隔离。通过在多个租户之间的资源复用,运营管理维护资源,有效节省开发应用的成本。
-
在租户之间共享应用程序的单个实例,可以实现当应用程序升级时,所有租户可以同时升级。
-
多个租户共享一份系统的核心代码,因此当系统升级时,只需要升级相同的核心代码即可。
灵活的消息系统
- Pulsar做了队列和流模型的统一,在Topic只需要保存一份
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2053
2053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











