




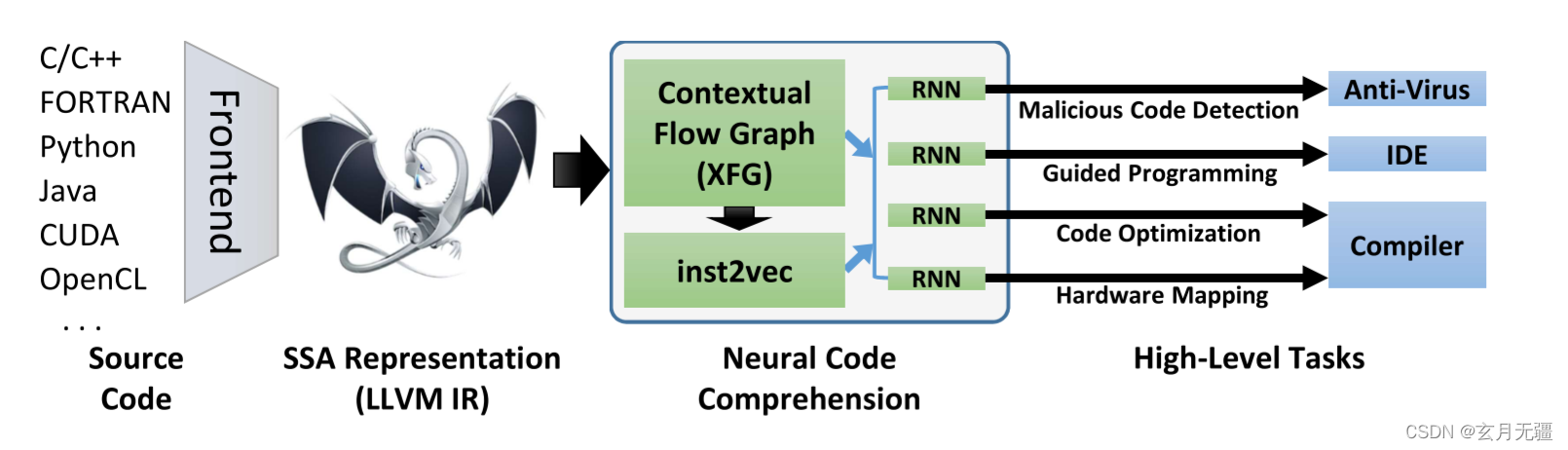
 该论文提出了Neural Code Comprehension框架,通过LLVM IR的中间表示学习代码的分布式表示,以理解程序语义。研究者构建了XFG表示来结合数据和控制流,用于语句嵌入,并在多项程序分析任务中评估了这种方法。他们使用类比、聚类和高级任务(如语义测试)来验证表示的有效性,表明即使使用简单的LSTM架构,也能取得与专门DNN架构相当甚至更好的结果。
该论文提出了Neural Code Comprehension框架,通过LLVM IR的中间表示学习代码的分布式表示,以理解程序语义。研究者构建了XFG表示来结合数据和控制流,用于语句嵌入,并在多项程序分析任务中评估了这种方法。他们使用类比、聚类和高级任务(如语义测试)来验证表示的有效性,表明即使使用简单的LSTM架构,也能取得与专门DNN架构相当甚至更好的结果。

论文标题:Neural Code Comprehension: A Learnable Representation of Code Semantics
原文链接:Neural Code Comprehension: A Learnable Representation of Code Semantics
说明:在读研究生为方便记忆梳理学习,手敲论文笔记,概括论文的主要思想
背景
在代码学习表示领域,大多数试图直接处理代码或使用句法树表示。但是,由于功能调用,分支和可互换的语句顺序等结构特征,现有方法都不足以可靠地理解程序语义。
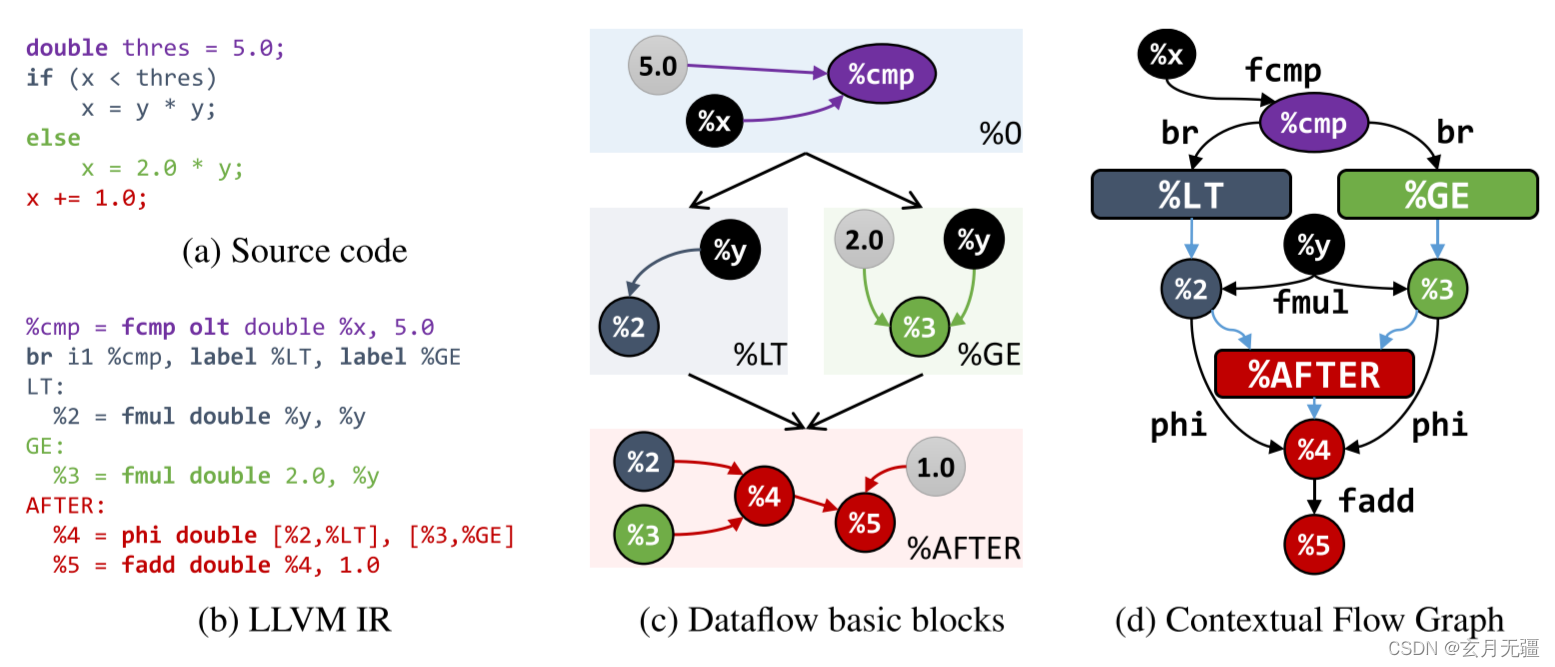
在本文中,我们提出了一种新的处理技术来学习代码语义,并将其应用于各种程序分析任务。特别是,我们规定代码的稳健分布假设适用于人类和机器生成的程序。根据这个假设,我们基于独立于源编程语言的代码的中间表示(IR)定义一个嵌入空间inst2vec。我们利用程序的基础数据流和控制流,为此IR提供了一个新的上下文流定义。然后,我们使用类比和聚类定性分析嵌入,并评估三个不同高级任务的学习表示。
挑战
- 源程序设计语言(或用于优化的机器代码)是固定的,这不能反映过多的语言,也不能推广到未来的语言。
- 现有方法按顺序处理令牌(或指令),目标是无函数和无循环的代码。然而,这样的代码并不代表大多数应用程序。
贡献
- 我们为代码制定了一个稳健的分布假设,从中我们得出了一种基于上下文流和 LLVM IR 的代码语句的新分布式表示。
- 我们详细介绍了 XFG 的构造,这是第一个专为结合数据和控制流的语句嵌入而设计的表示。
- 我们使用聚类、类比、语义测试和三个根本不同的高级代码学习任务来评估表示。
- 使用一个简单的 LSTM 架构和固定的预训练嵌入,我们匹配或超过了每项任务中表现最好的方法,包括专门的 DNN 架构。
设计过程和框架

















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









