




 论文介绍了Post2Vec,一种深度学习方法,针对StackOverflow帖子的标题、描述和代码片段进行综合表示学习。通过CNN提取特征,Post2Vec在相关性预测、分类和API推荐中表现出色,相比其他方法有15-25%的性能提升。文章关注资源效率与模型训练时间,对不同组件的考虑带来性能增长,但计算成本增加。
论文介绍了Post2Vec,一种深度学习方法,针对StackOverflow帖子的标题、描述和代码片段进行综合表示学习。通过CNN提取特征,Post2Vec在相关性预测、分类和API推荐中表现出色,相比其他方法有15-25%的性能提升。文章关注资源效率与模型训练时间,对不同组件的考虑带来性能增长,但计算成本增加。

论文标题:Post2Vec: Learning Distributed Representations of Stack Overflow Posts
原文链接:https://ieeexplore.ieee.org/abstract/document/9469219
说明:在读研究生为方便记忆梳理学习,手敲论文笔记,概括论文的主要思想和内容。
背景
- 利用深度学习的方法与模型对StackOverflow帖子进行分布式表达的学习,然后将这些向量用于不同的下游任务。
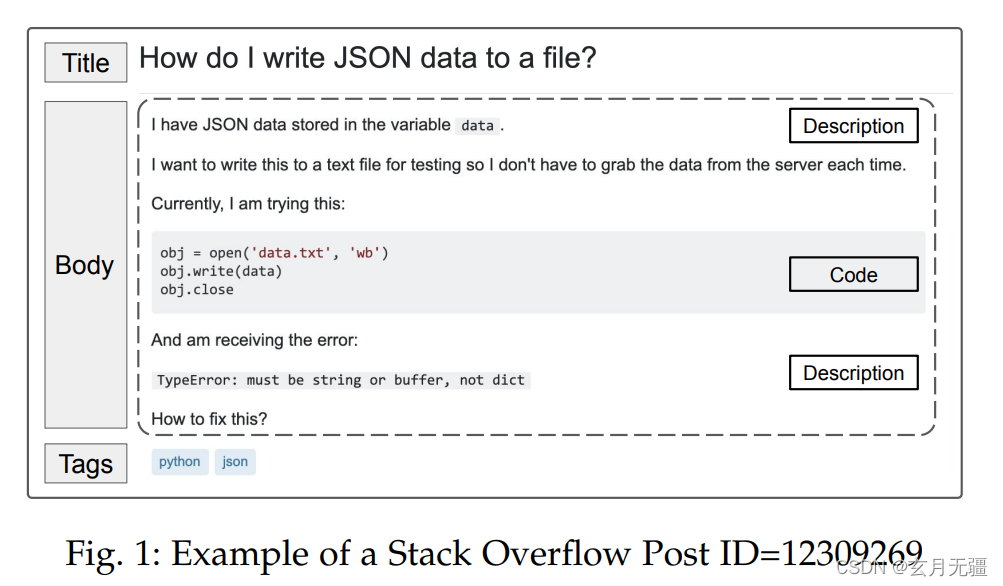
- StackOverflow帖子主要包含:标题、描述和代码片段,本文主要是将其们集成以提取帖子的语义理解,并将帖子标签作为结果比较。
- 使用Post2Vec学习到的向量表示用于相关性预测、帖子分类和API推荐,评估Post2Vec的学习能力。
本文贡献
- 提出Post2Vec深度学习架构学习SQA帖子的向量表示,为StackOverflow定制但适用于其他SQA网站帖子。
- Post2Vec与其他先进的基于神经网络方法比较,可以实现15-25%的改进并完成学习的过程最多加快1.5天。
- 在三个下游任务的表现:
1)基于CNN的Post2Vec优于基于LSTM的模型,且消耗的资源更少;
2)考虑代码片段提高效率,但是消耗更多模型训练的计算资源;
3)分别考虑帖子的多个组件提高性能,但消耗较多模型训练的计算资源。 - Post2Vec生成的帖子向量与三个任务的最先进方法对比,有实质性改进。
Post2Vec设计过程
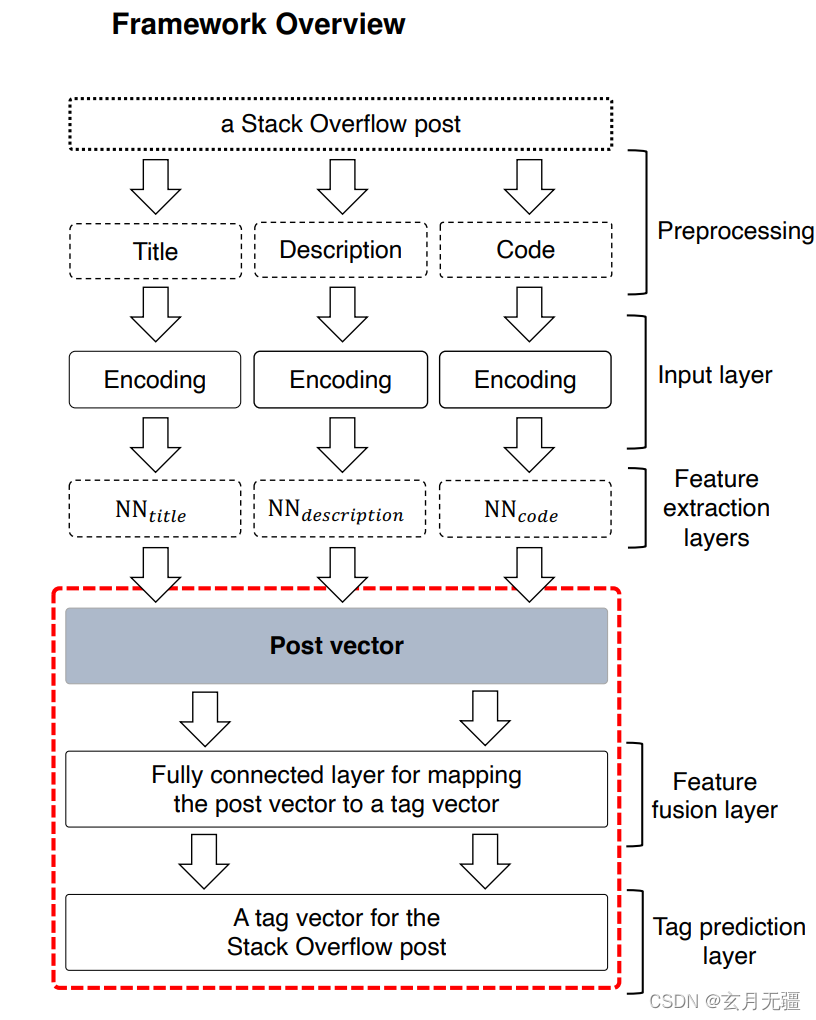
- 预处理:提取代码片段;移除html标签;向量化标题、描述和代码片段;构建特点组件的词汇表(出现次数>50)。
- 输入层:索引和填充;向量化;矩阵表示。
- 特征提取层:利用CNN模型对三者提取特征,帖子中代码片段很短、结构很差、且用不同的编程语言,现有的代码表示技术(适用于单个程序语言或代码至少是一个完整的函数或方法)无法应用。
- 特征融合和标签预测层


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









