




 本文深入探讨了机器学习的基本概念,涵盖了监督学习、无监督学习、半监督学习和强化学习等主要类型。详细解析了分类、回归、聚类等常见问题及对应的算法,如逻辑回归、BP神经网络、K-Means等。
本文深入探讨了机器学习的基本概念,涵盖了监督学习、无监督学习、半监督学习和强化学习等主要类型。详细解析了分类、回归、聚类等常见问题及对应的算法,如逻辑回归、BP神经网络、K-Means等。
机器学习基础:
机器学习是从数据中学习和提取有用的信息,不断提升机器的性能。那么对于一个具体的机器学习的问题,很重要的一部分是对数据的收集,我们称这部分为训练数据。机器学习是从这些数据中学习规则,利用学习到的规则来预测新的数据。
机器学习算法的分类:
- 在机器学习中根据任务的不同可以分为监督学习、无监督学习、半监督学习和增强学习。
- 监督学习的训练数据中包含了类别的信息,如在垃圾邮件的检测中,其训练样本包含了邮件的类别信息。如在垃圾邮件的检测中,其训练样本包含了邮件的类别信息:垃圾邮件和非垃圾邮件。在监督学习中典型的问题是分类和回归,典型的算法有:Logistic Regression和BP神经网络和线性回归算法。
- 与监督学习不同的是,无监督学习的训练数据中不包含任何类别的信息。在无监督学习中,其典型的问题为聚类问题,典型的算法有K-Means算法、DBSCAN算法等。
- 半监督学习的训练数据中有一部分数据包含类别信息,同时有一部分数据不包含类别信息,是监督学习和无监督学习的融合。在半监督学习中,其算法是在监督学习的算法上进行扩展,使之可以对未标注信息进行建模。
- 监督学习和无监督学习上使用较多的两种学习方法,而半监督学习是监督学习和无监督学习的融合。
监督学习:
- 前面简单介绍了监督学习的概念,监督学习是机器学习算法中的一种重要的学习方法,在监督学习中默契训练样本包含有特征和标签信息。在监督学习中,分类算法和回归算法是两类最重要的算法。两者之间最重要的区别是分类算法中的标签是离散的值,如广告点击问题中标签为{-1, +1},分别代表广告点击和未点击,而回归算法中的标签值是连续的值,如通过人的身高、体重、性别等信息预测人的年龄,因为年龄是连续的正整数,因此标签为[1, 80]。
监督学习的流程:
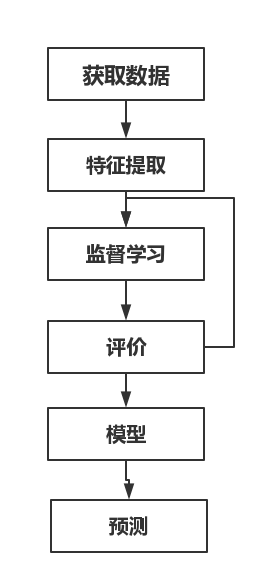
- 对于具体的监督学习任务,首先是获取到带有属性值的样本,假设有m个训练样本m1,m2 … ,然后对样本进行预处理,过滤数据中的杂质,保留其中有用的信息,这个过程称为特征处理和特征提取。
- 通过监督算法习得样本特征到样本标签之间的假设函数。监督学习通过从样本数据中习得假设函数,并用其对新的数据进行预测。
监督学习算法
- 分类问题是指通过训练数据学习一个从观测样本到离散的标签的映射,分类问题是一个监督学习问题。典型的问题有:垃圾邮件的分类。训练样本是邮件中的文本,标签是每个邮件是否是垃圾邮件{-1, +1}(-1代表垃圾邮件,+1代表不是垃圾邮件)。目标是根据这些带标签的样本,预测一个新邮件是否是垃圾邮件;点击率预测:训练样本是用户、广告和广告主的信息,标签是否被点击{-1, +1} (+1代表点击,-1代表未点击)。目标是在广告主发布广告后,预测指定的用户是否会点击,上述两种问题都是二分类问题。手写数字的识别:即是识别{0, … ,9}中的那个数字,这是一个多分类问题。
- 与分类问题不同的是,回归问题。回归问题是指通过训练数据学习一个从观测样本到连续的 标签的映射,在回归问题是一系列连续的值。典型的问题有:股票价格的预测,即利用股票的历史价格预测未来的股票价格;房屋价格的预测:即利用房屋的数据,如:房屋的面积,位置等信息来预测房屋的价格。
无监督学习
- 无监督学习是另一种机器学习算法,与监督学习不同的是,在无监督学习中,其样本只含有特征,不包含标签信息,与监督学习不同的是由于无监督学习不包含标签信息,在学习时其分类结果是否正确。
无监督学习的流程:
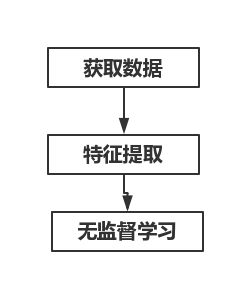
- 对于无监督学习任务,首先是获取到带有特征值的样本,建设有m个样本,对这m个样本进行处理,得到样本中有用的信息,这个过程称为特征处理或者特征提取,最后是通过无监督学习算法处理这些样本,如利用聚类算法对这些样本进行聚类。
无监督的学习算法
- 聚类算法是无监督算法中最典型的一种学习算法。聚类算法利用样本的特征,将具有相似特征的样本划分到同一个类别中,而不关心这个类别具体是什么。
- 除了聚类算法,在无监督学习中还有一类比较重要的算法是降维的算法,数据降维基本原理是将样本点从输入空间通过线性或者非线性变换映射到一个低纬空间,从而获得一个关于原始数据集紧致的低纬表示。
推荐系统和深度学习
- 在机器学习中,除了按照上述的分类将算法分为监督学习和无监督学习之外,还有一些其他的分类算法,如按照算法的功能,将算法分为分类算法、回归算法、聚类算法和降维算法等。随着机器学习领域的不断发展,出现了很多新的研究方向,推荐算法和深度算法是近年来研究较多的算法。
推荐算法
- 随着信息量的急剧扩大,信息过载的问题变得尤为突出,当用户无明确的信息需求时,用户无法从大量的信息中获取到感兴趣的信息,同时,信息量的急剧上升也导致了大量的信息被埋没,无法接触到一些潜在客户。推荐系统的出现被称为连接用户和信息的桥梁,一方面帮用户从海量数据中找到感兴趣的信息,另一方面将有价值的信息传递给潜在用户。
- 中推荐系统中,推荐算法起了至关重要的作用。常见的推荐算法有:协同过滤算法,给予矩阵分解的推荐算法和基于图的推荐算法。
深度学习
- 传统的机器学习算法都是利用浅层的结构,这些结构一般包含一到两层的非线性特征变换,浅层结构在解决很多简单的问题上效果尤为明显,但是在处理一些更加复杂的雨自然信号问题时,就会遇到更多的问题/
- 随着计算机的不断发展,2006年Hinton等人提出了逐层训练的概念,深度学习又一次进入人们的视野,数据量的不断扩大以及计算机计算能力的增强,使得深度学习技术成为可能。在深度学习中,常见的几种模型包括:1、自编码器模型,通过堆叠自编码器来构建深层网络;2、卷积神经网络,通过卷积层与采样层的不断交替构建深层网络;3、循环神经网络。

















 5801
5801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









