







1. TF-IDF原理
1.1 什么是TF-IDF?
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。 TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF有两层意思,一层是"词频"(Term Frequency,缩写为TF),另一层是"逆文档频率"(Inverse Document Frequency,缩写为IDF)。
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。
1.2 TF-IDF的计算
举个小例子:假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 log(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 *4=0.12。
1.3 代码实践
vectorizer = TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9, sublinear_tf=True)
vectorizer.fit(df_all['word_seg'])
x_train = vectorizer.transform(df_train['word_seg'])
x_test = vectorizer.transform(df_test['word_seg'])
2. 以TF-IDF特征值为权重的文本矩阵化
(可以使用Python中TfidfTransformer库)
import pkuseg
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
text = []
with open(r'..\cnews\cnews.train.txt', 'r', encoding = 'utf-8') as fsource:
text_line= fsource.readline()
seg = pkuseg.pkuseg()
seg_list = seg.cut(text_line)
text.extend(seg_list)
with open(r'..\stoplist_baidu.txt', 'r', encoding = 'utf-8') as fstop:
content = fstop.read()
stop_words = content.split('\n')
count_vectorizer = CountVectorizer(stop_words=stop_words)
tfidf_transformer = TfidfTransformer()
tfidf = tfidf_transformer.fit_transform(count_vectorizer.fit_transform(text))
print (tfidf)
print('-------------给个小一点的例子--------------')
corpus = [ 'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
s_count_vectorizer = CountVectorizer()
s_tfidf_transformer = TfidfTransformer()
s_tfidf = s_tfidf_transformer.fit_transform(s_count_vectorizer.fit_transform(corpus))
print (s_tfidf)
3. 互信息的原理
正式地,两个离散随机变量 X 和 Y 的互信息可以定义为:
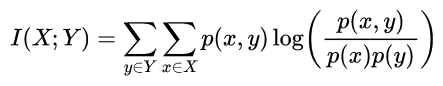
其中 p(x,y) 是 X 和 Y 的联合概率分布函数,而p(x)和p(y)分别是 X 和 Y 的边缘概率分布函数。
在连续随机变量的情形下,求和被替换成了二重定积分:
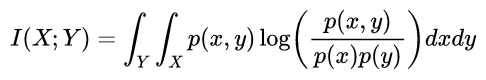
互信息量I(xi;yj)在联合概率空间P(XY)中的统计平均值。 平均互信息I(X;Y)克服了互信息量I(xi;yj)的随机性,成为一个确定的量。如果对数以 2 为基底,互信息的单位是bit。
直观上,互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X 决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。(这种情形的一个非常特殊的情况是当 X 和 Y 为相同随机变量时)
互信息又可以等价地表示成:
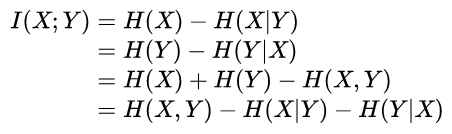
其中H(X)和H(Y) 是边缘熵,H(X|Y)和H(Y|X)是条件熵,而H(X,Y)是X和Y的联合熵。注意到这组关系和并集、差集和交集的关系类似,用Venn图表示: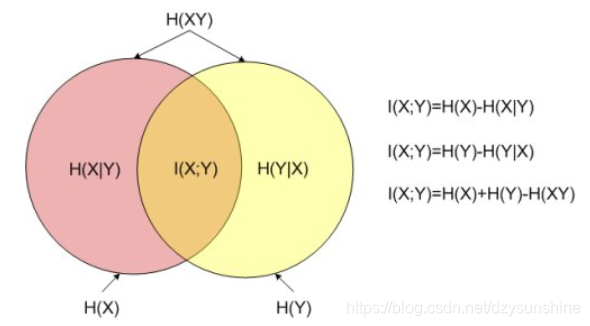
4. 利用互信息进行特征筛选
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import mutual_info_classif
#选择K个最好的特征,返回选择特征后的数据
#arr = SelectKBest(mutual_info_classif, k=2).fit_transform(tfidf, target[:99])
from nltk.corpus import stopwords
import collections
import pandas as pd
import numpy as np
import os
import codecs
pos_list=[]
with open('../Sentiment_IMDB/aclImdb/train/pos_all.txt','r',encoding='utf8')as f:
line=f.readlines()
pos_list.extend(line)
neg_list=[]
with open('../Sentiment_IMDB/aclImdb/train/neg_all.txt','r',encoding='utf8')as f:
line=f.readlines()
neg_list.extend(line)
#创建标签
label=[1 for i in range(12500)]
label.extend([0 for i in range(12499)])
#评论内容整合
content=pos_list.extend(neg_list)
content=pos_list
stop_words=set(stopwords.words('english'))
count_vectorizer = CountVectorizer(stop_words=stop_words)
tfidf_transformer = TfidfTransformer()
tfidf = tfidf_transformer.fit_transform(count_vectorizer.fit_transform(content))
print (tfidf.shape)
arr = SelectKBest(mutual_info_classif, k=2).fit_transform(tfidf[:24999], label)
print(arr)
5. 参考
互信息:https://blog.youkuaiyun.com/BigData_Mining/article/details/81279612
https://blog.youkuaiyun.com/shark803/article/details/89228875


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









