









1、Elastic Stack生态圈
Kibana 可视化
奇异果+香蕉组合单词
数据可视化工具,帮助用户
Elasticsearch 存储、计算
Logstash 数据抓取
开源的服务器端数据处理管道,支持从不同来源采集数据,转换数据
实时解析和转换数据、可扩展等
Beat 轻量的数据采集器
Go语言开发
2、安装和启动
官网下载,先e在k运行,cmd命令行直接bin/xxx
ElasticSerach 端口:9200
Kibana 端口:5601
dev tools 是k的一个很好用的console
也可以在docker容器中运行
macos教程:https://www.cnblogs.com/gshao/p/13446961.html
启动:
先到文件目录,配置好conf
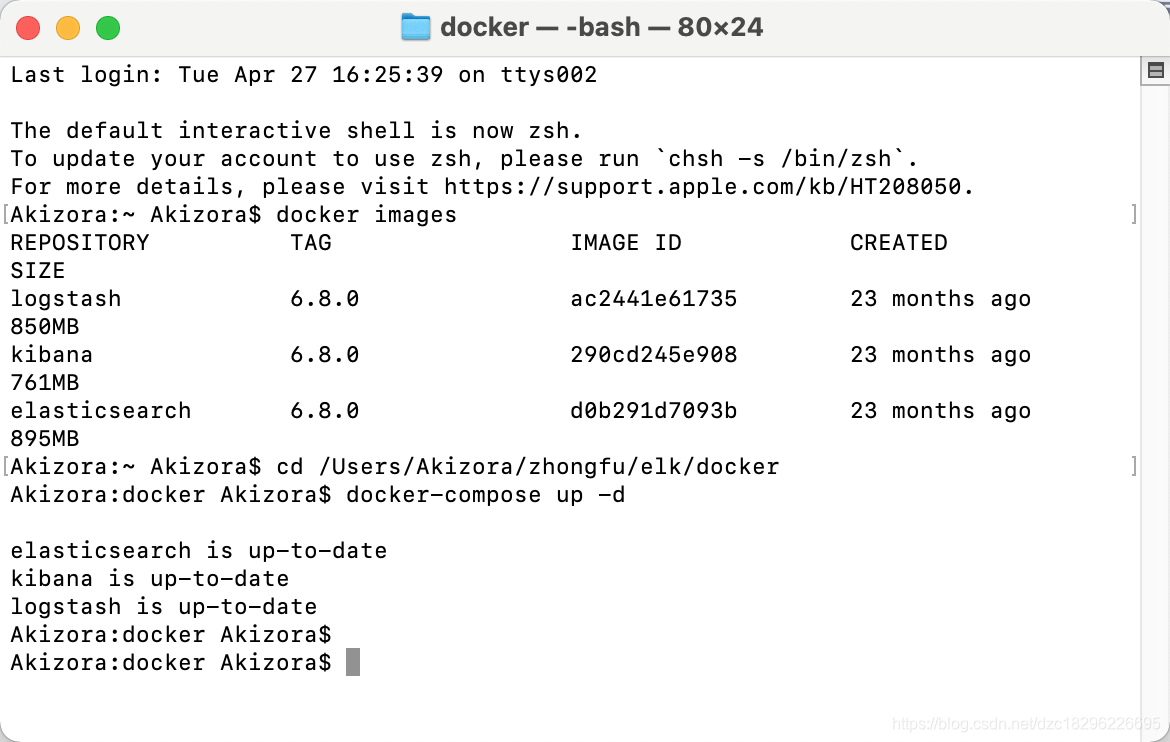
cd /Users/Akizora/zhongfu/elk/docker
运行命令启动即可:
docker-compose up -d
使用logstash导入es模拟数据movies
1、下载es对应版本的logstash,地址:https://www.elastic.co/cn/downloads/logstash
2、解压安装,然后将 配置文件放入bin目录
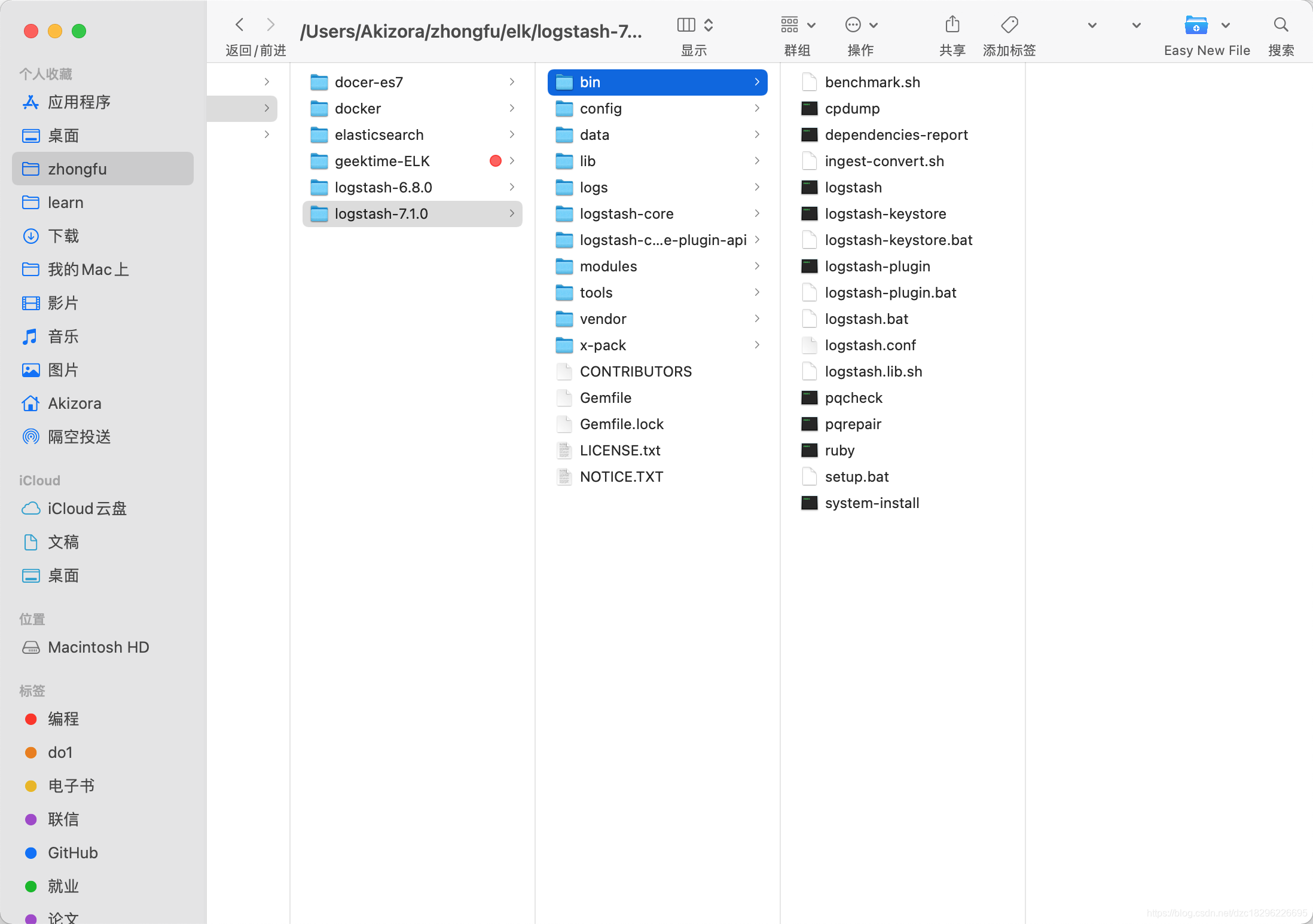
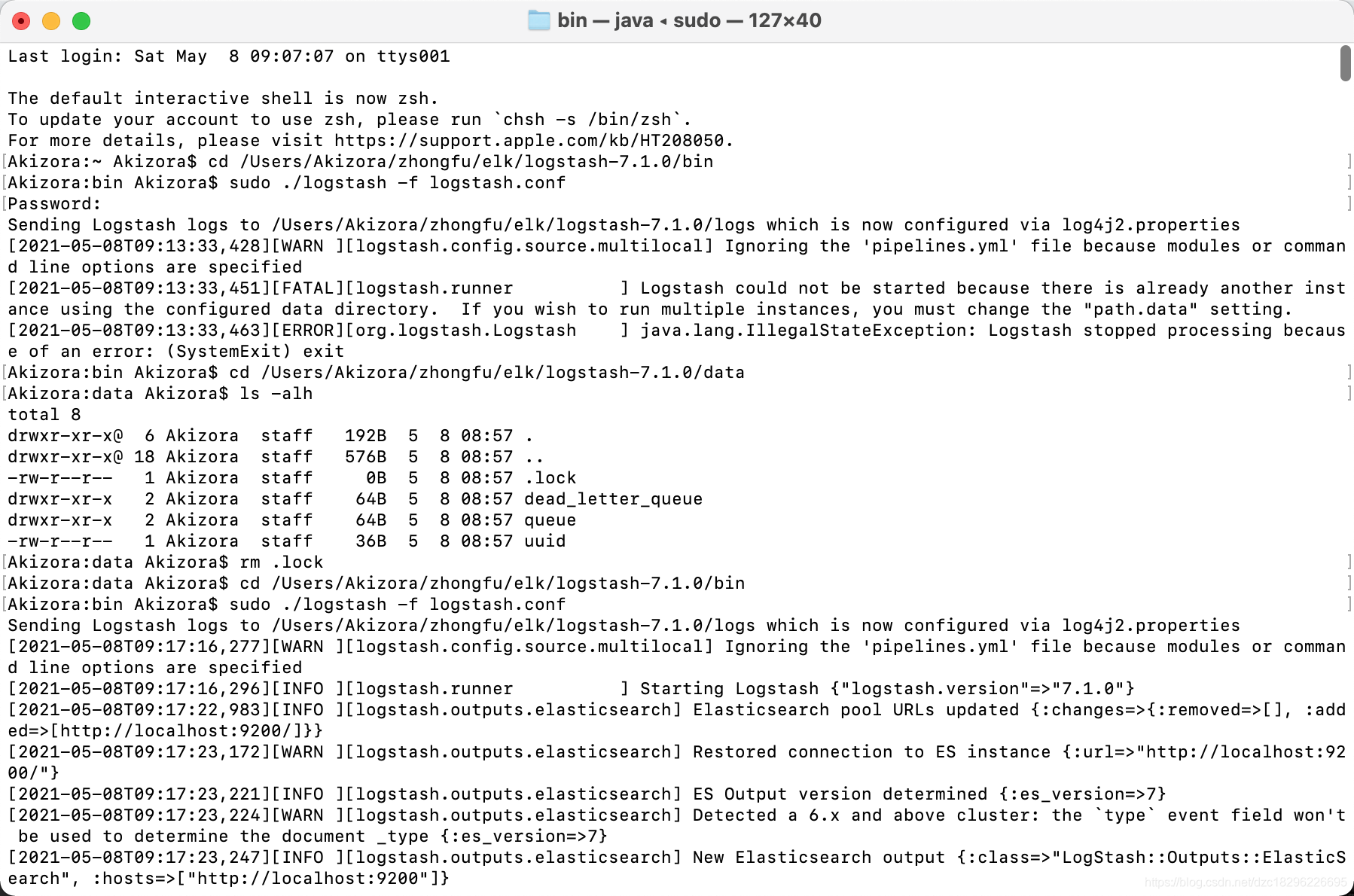
3、使用cmd 运行logstash 导入数据
如果导入失败,可能存在 .lock缓存,需要删除
删除地址
4、成功运行:
3、类比
关系型数据库中的表、数据、字段
映射到 es 中的 index、doc、filed

4、CRUD使用
需要先建立索引,然后建立type,类似数据库建表,然后用RESTful风格的接口加入数据集,doc
使用
#创建type
PUT /test
{
"mappings": {
"doc": {
"properties":{
"id":{"type":"integer"},
"name":{"type":"keyword"},
"age":{"type":"integer"},
"address":{"type":"keyword"},
"content":{"type":"text"}
}
}
}
}
GET /test/doc/2
#创建document 指定id 如果存在就报错
PUT /test/doc/2?op_type=create
{
"name":"王小黑",
"address":"深圳",
"age":20,
"content":"我就是有点黑"
}
5、倒排索引
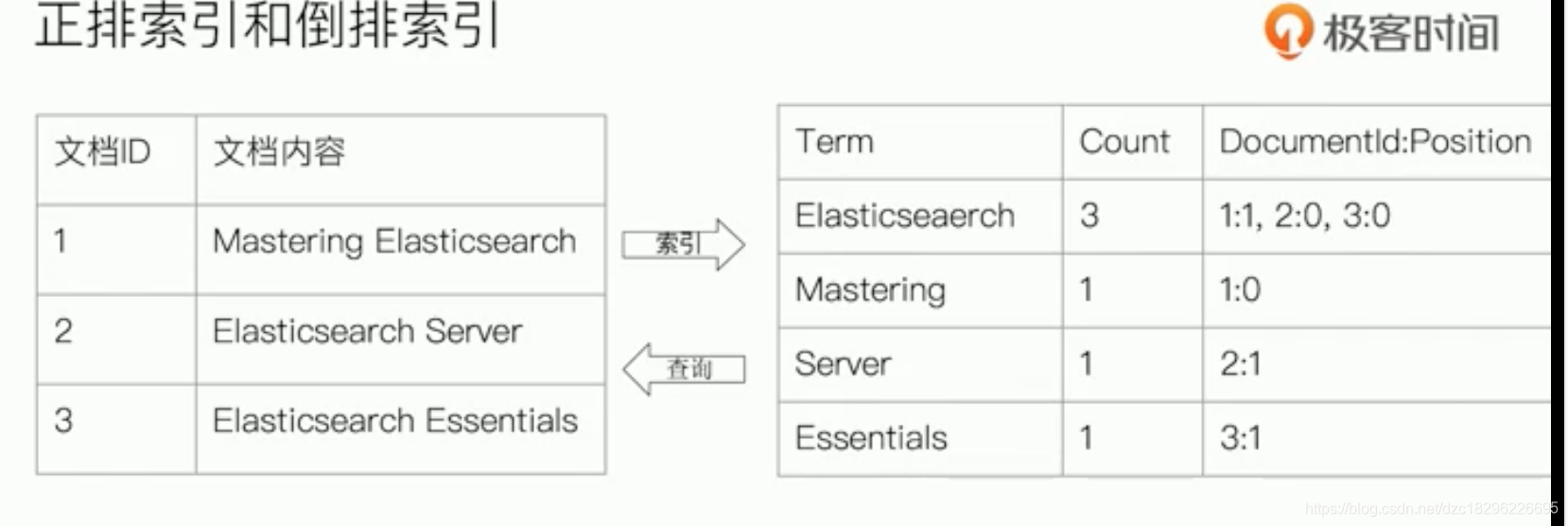
核心组成:包含两个部分
单词词典:b+树或者哈希拉链
倒排列表:记录了单词对应的文档结合,由倒排索引项组成
倒排索引项:文档id、位置(Position,单词在文档中分词的位置用于语句搜索)、词频TF(用于评分)、偏移(Offset,记录单词的开始结束位置,实现高亮显示)
6、其他
6.1、分词器 Analyzer
有一些不同的方式将文本按规则分好
中文分词会有些难点,需要按词分,不是按字分,需要plugin icuanalyzer
6.2、search api
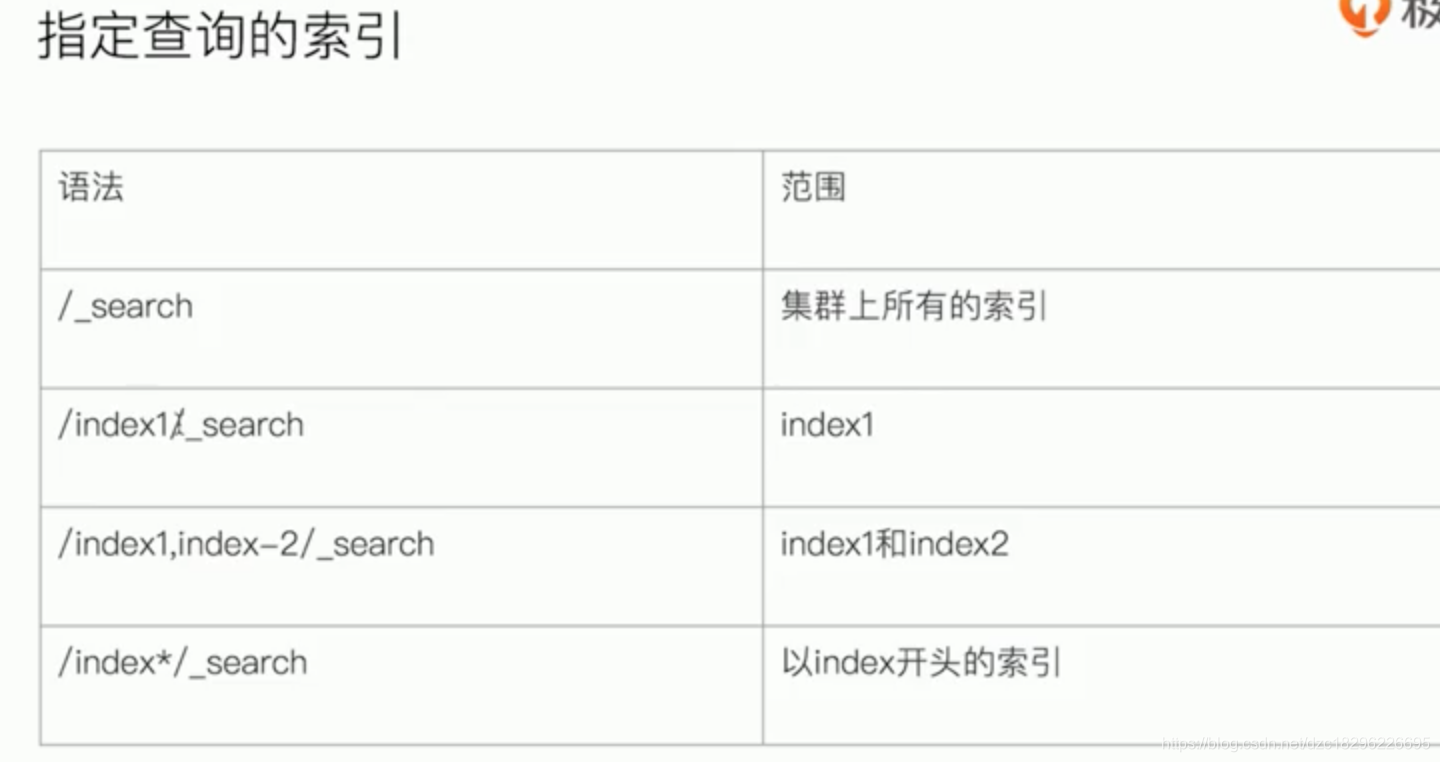

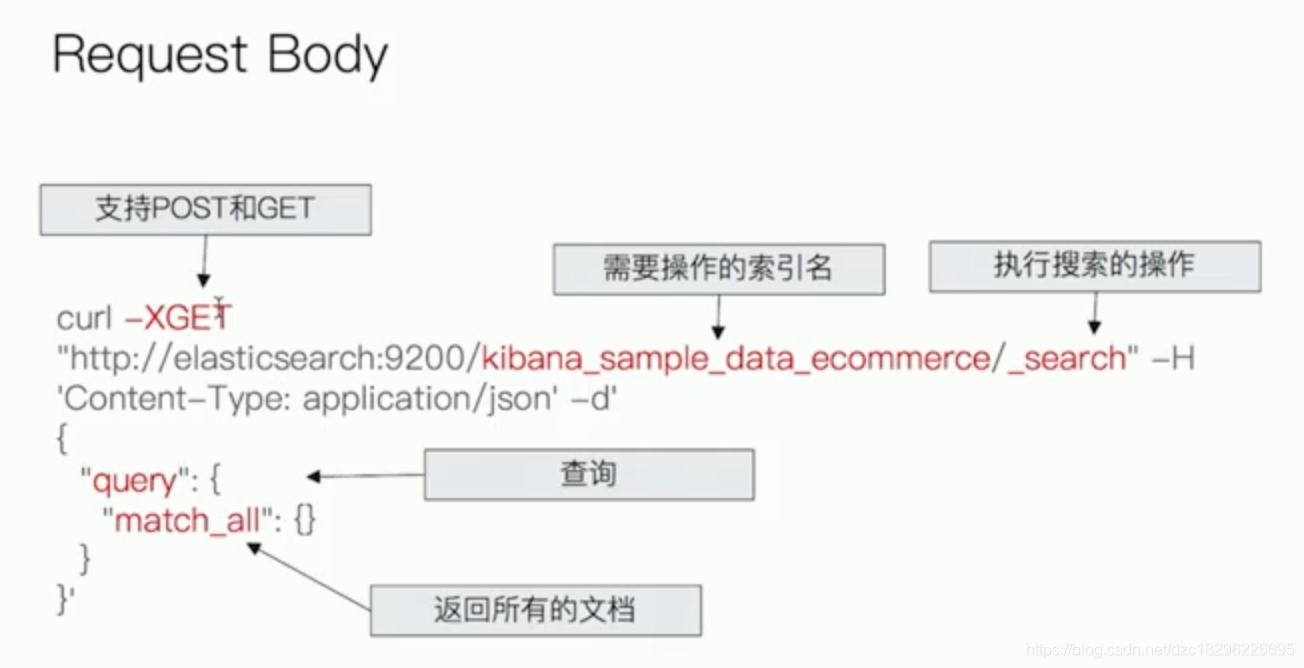
uri search

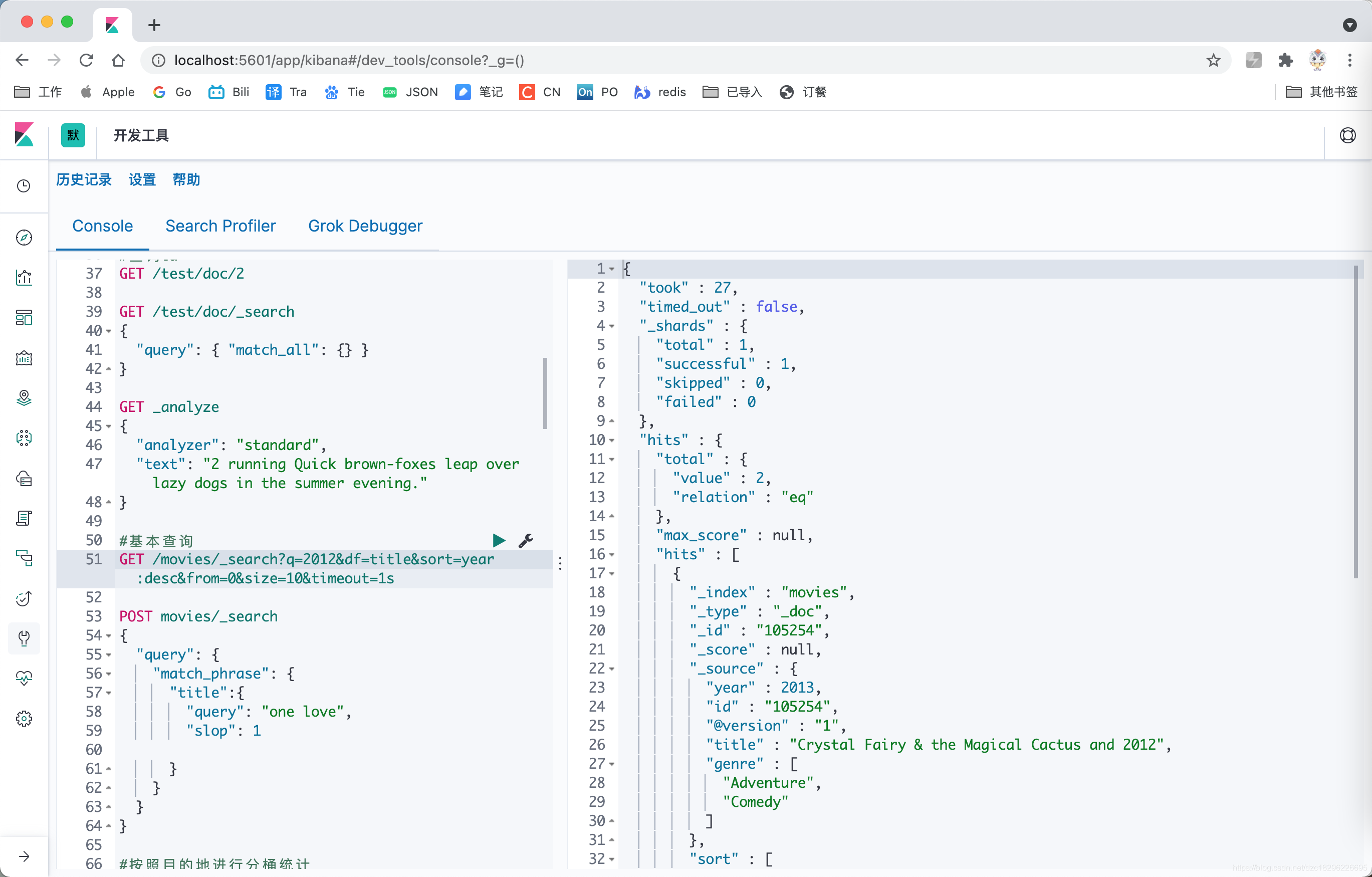
#基本查询
GET /movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s
#带profile
GET /movies/_search?q=2012&df=title
{
"profile":"true"
}
#泛查询,正对_all,所有字段
GET /movies/_search?q=2012
{
"profile":"true"
}
#指定字段
GET /movies/_search?q=title:2012&sort=year:desc&from=0&size=10&timeout=1s
{
"profile":"true"
}
# 查找美丽心灵, Mind为泛查询
GET /movies/_search?q=title:Beautiful Mind
{
"profile":"true"
}
# 泛查询
GET /movies/_search?q=title:2012
{
"profile":"true"
}
#使用引号,Phrase查询
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile":"true"
}
#分组,Bool查询
GET /movies/_search?q=title:(Beautiful Mind)
{
"profile":"true"
}
#布尔操作符
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful AND Mind)
{
"profile":"true"
}
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful NOT Mind)
{
"profile":"true"
}
# 查找美丽心灵
GET /movies/_search?q=title:(Beautiful %2BMind)
{
"profile":"true"
}
#范围查询 ,区间写法
GET /movies/_search?q=title:beautiful AND year:[2002 TO 2018%7D
{
"profile":"true"
}
#通配符查询
GET /movies/_search?q=title:b*
{
"profile":"true"
}
//模糊匹配&近似度匹配
GET /movies/_search?q=title:beautifl~1
{
"profile":"true"
}
GET /movies/_search?q=title:"Lord Rings"~2
{
"profile":"true"
}


7、聚合
- bucket 类似 groupby
- metric 类似count
8、查询
# 基于term 和全文本的查询
DELETE products
PUT products
{
"settings": {
"number_of_shards": 1
}
}
POST /products/_bulk
{"create": {"_index": "products", "_type": "docs", "_id": 1}}
{ "productID" : "XHDK-A-1293-#fJ3","desc":"iPhone" }
{"create": {"_index": "products", "_type": "docs", "_id": 2}}
{ "productID" : "KDKE-B-9947-#kL5","desc":"iPad" }
{"create": {"_index": "products", "_type": "docs", "_id": 3}}
{ "productID" : "JODL-X-1937-#pV7","desc":"MBP" }
GET /products
POST /products/_search
{
"query": {
"term": {
"desc": {
"value":"ipad"
}
}
}
}
POST /products/_search
{
"query": {
"term": {
"desc.keyword": {
"value":"iPad"
}
}
}
}
POST /products/_search
{
"query": {
"term": {
"productID": {
"value": "XHDK-A-1293-#fJ3"
}
}
}
}
POST /products/_search
{
//"explain": true,
"query": {
"term": {
"productID.keyword": {
"value": "XHDK-A-1293-#fJ3"
}
}
}
}
POST /products/_search
{
"explain": true,
"query": {
"constant_score": {
"filter": {
"term": {
"productID.keyword": "XHDK-A-1293-#fJ3"
}
}
}
}
}
#设置 position_increment_gap
DELETE groups
PUT groups
{
"mappings": {
"properties": {
"names":{
"type": "text",
"position_increment_gap": 0
}
}
}
}
GET groups/_mapping
POST groups/_doc
{
"names": [ "John Water", "Water Smith"]
}
POST groups/_search
{
"query": {
"match_phrase": {
"names": {
"query": "Water Water",
"slop": 100
}
}
}
}
POST groups/_search
{
"query": {
"match_phrase": {
"names": "Water Smith"
}
}
}
term查询是按词拆开了的,所以iPhone查不出,需要加keyword
复合查询:bool query
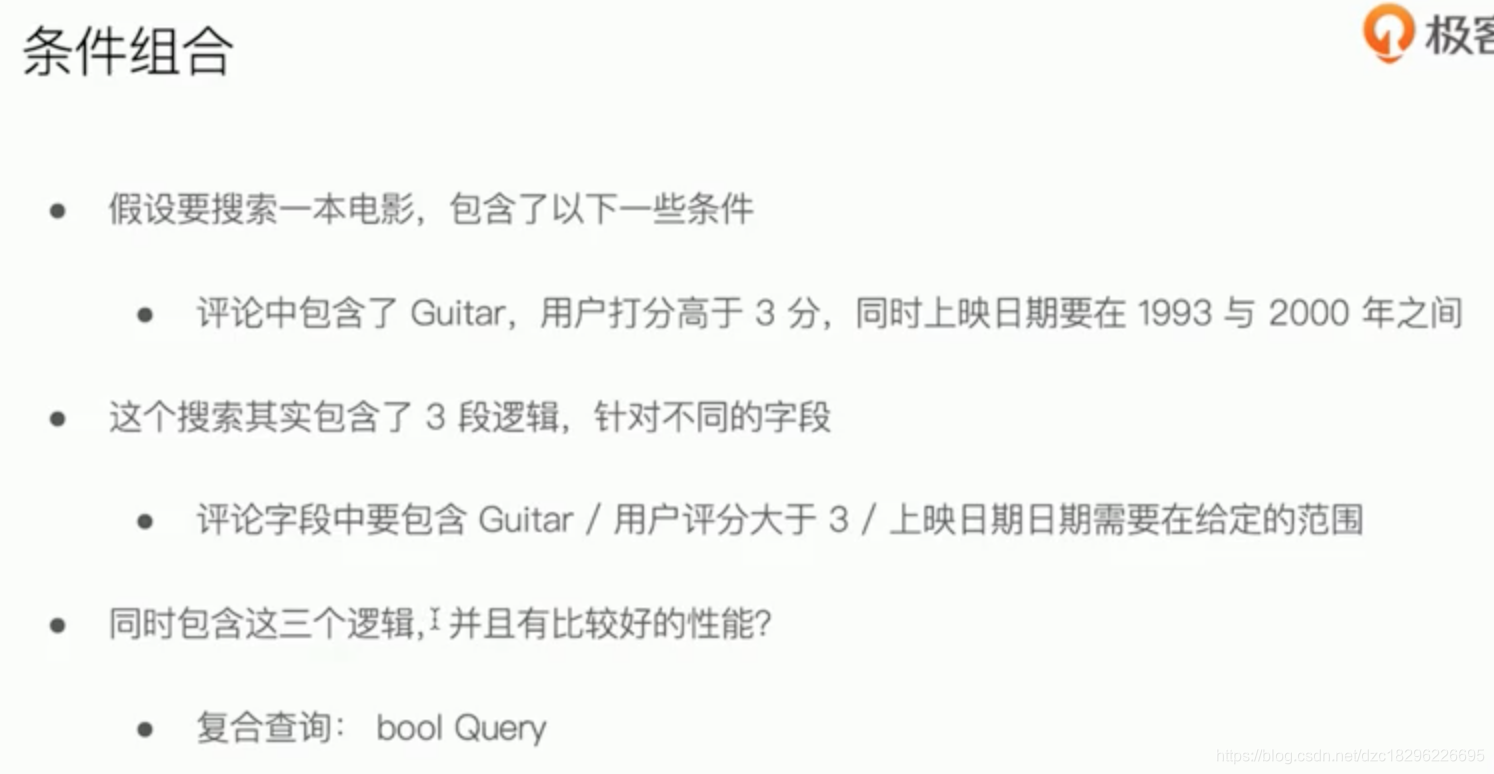
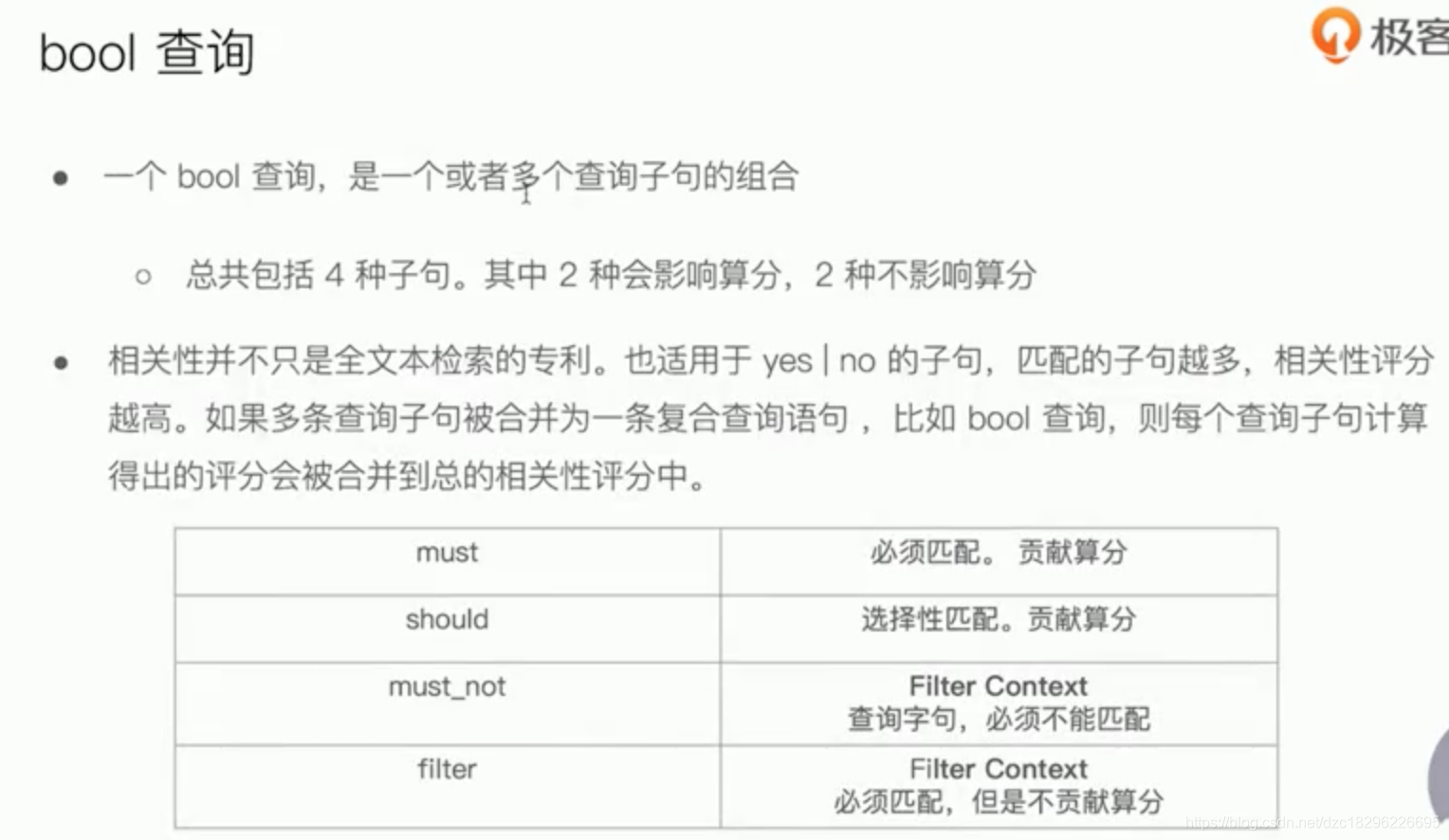

使用bool做结构化查询

影响权重,控制返回结果

dixMaxQuery处理竞争字段、tie_breaker对算分进行调整
mutiMatch
各种分词器:
HanLp、Ik



集群的搭建:
去config里的elasticsearch yaml改配置
默认单节点:1分片 1副本
分片概念:数据放在不同的‘表’组合起来是完整的
副本:备份的数据
水平扩容:
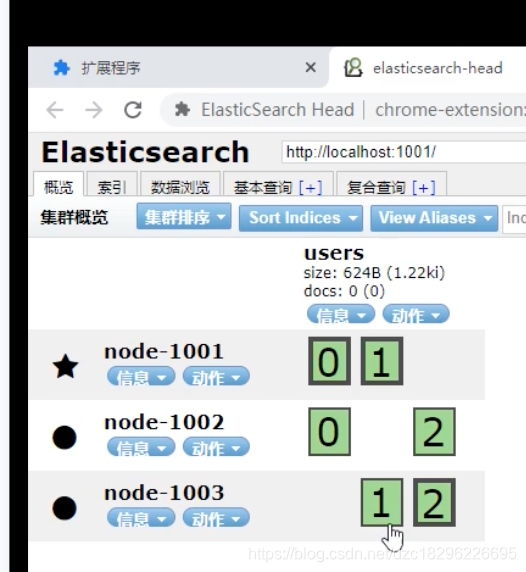
均匀分配
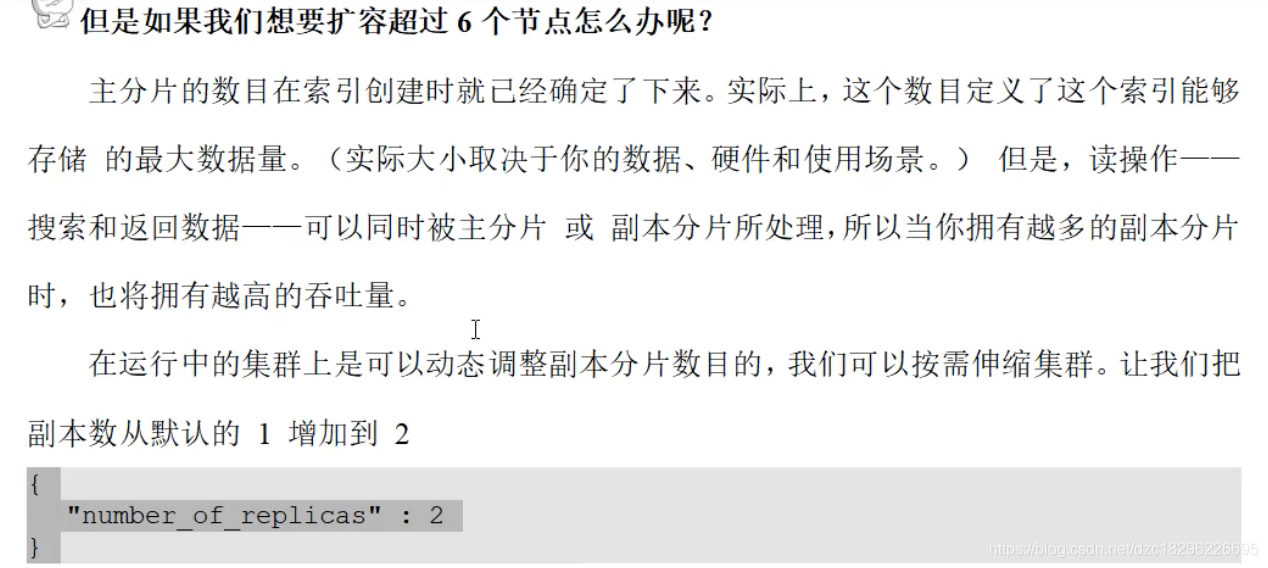
改不了主节点的分片数量,但是可以让副本节点调整分片
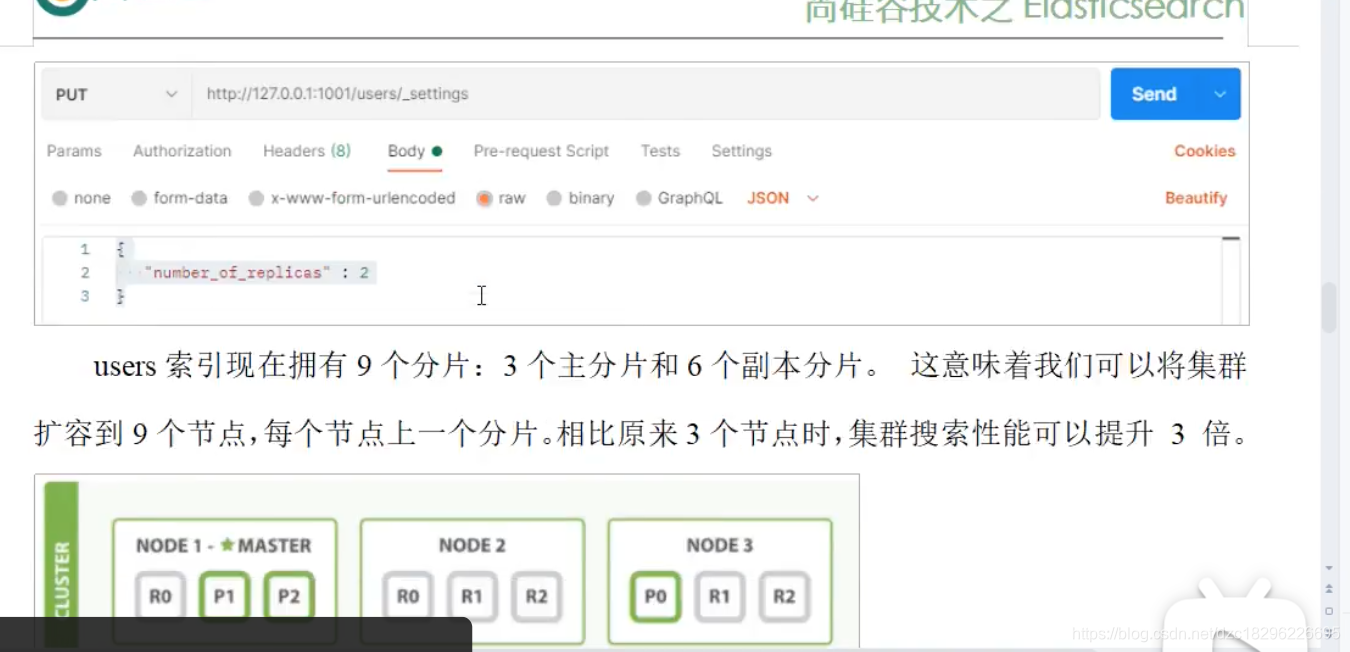
路由计算 & 分片控制:
插入数据先放到主分片,副本做备份
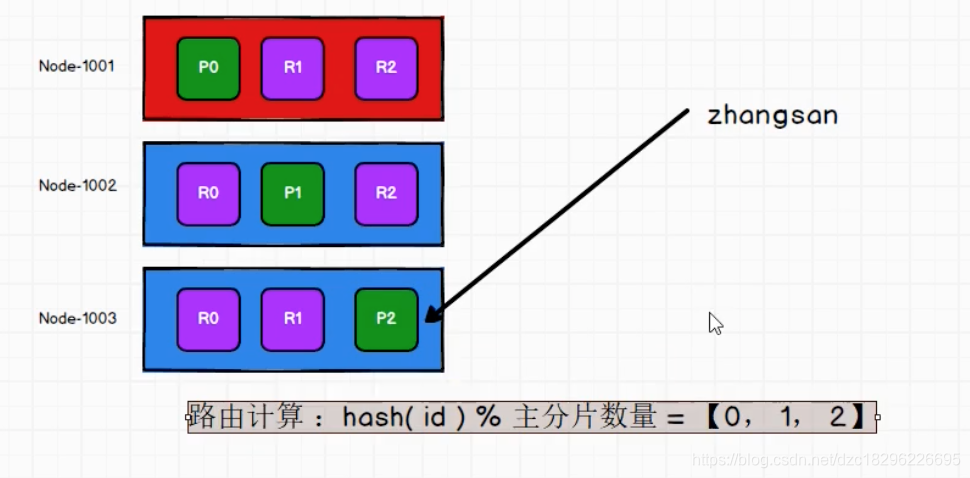
怎么存?怎么取?
这个规则需要在 存取时统一
路由计算:hash(id)%主分片数量
用户在取的时候可以访问任何一个节点获取数据,这个节点叫做协调节点
且会轮训
数据写流程:
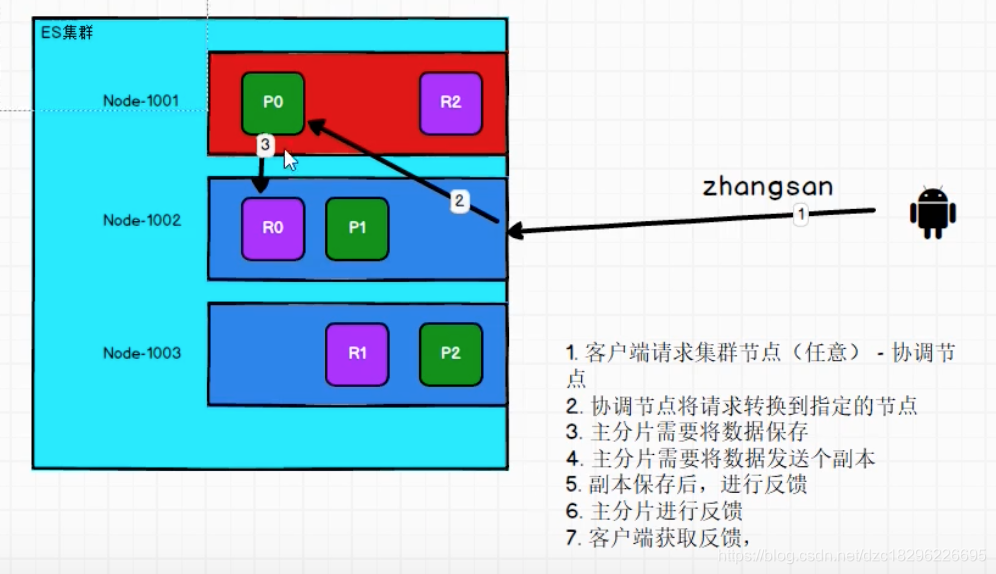
一致性操作,one 只要主成功就查询,all 主和副都更新才能查询。默认:quorum 绝大多数有数据就可以


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









