



 本文深入解析word2vec的两种模型——CBOW与Skip-gram的工作原理。通过具体例子展示了如何利用上下文词预测中心词(CBOW)及利用中心词预测上下文词(Skip-gram),并介绍了one-hot向量如何转化为低维词向量。
本文深入解析word2vec的两种模型——CBOW与Skip-gram的工作原理。通过具体例子展示了如何利用上下文词预测中心词(CBOW)及利用中心词预测上下文词(Skip-gram),并介绍了one-hot向量如何转化为低维词向量。
前言
word2vec如何将corpus(语料库)的one-hot向量(模型的输入)转换成低维词向量(模型的中间产物,更具体来说是输入权重矩阵),真真切切感受到向量的变化,暂不涉及加速算法。
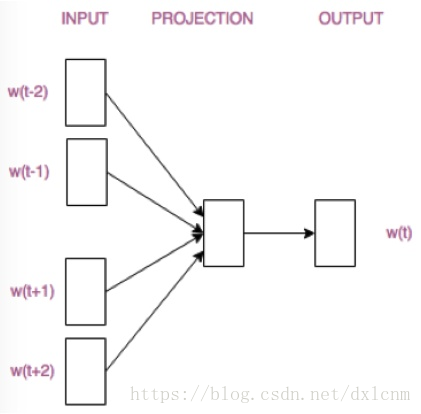
CBOW模型根据中心词W(t)周围的词来预测中心词:
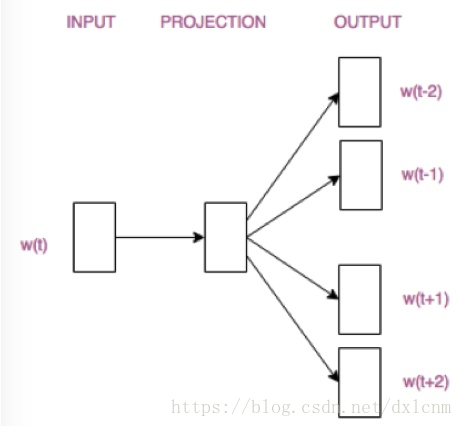
Skip-gram模型则根据中心词W(t)来预测周围词:
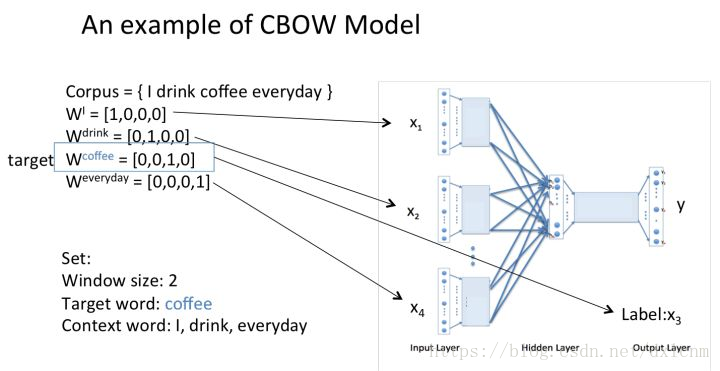
CBOW模型的理解
假设我们现在的Corpus是这一个简单的只有四个单词的document:{I drink coffee everyday}
我们选coffee作为中心词,window size设为2
也就是说,我们要根据单词"I","drink"和"everyday"来预测一个单词,并且我们希望这个单词是coffee。
输入层:上下文单词的onehot1*4维*3个词
输出层:1*4维的向量(概率表示)
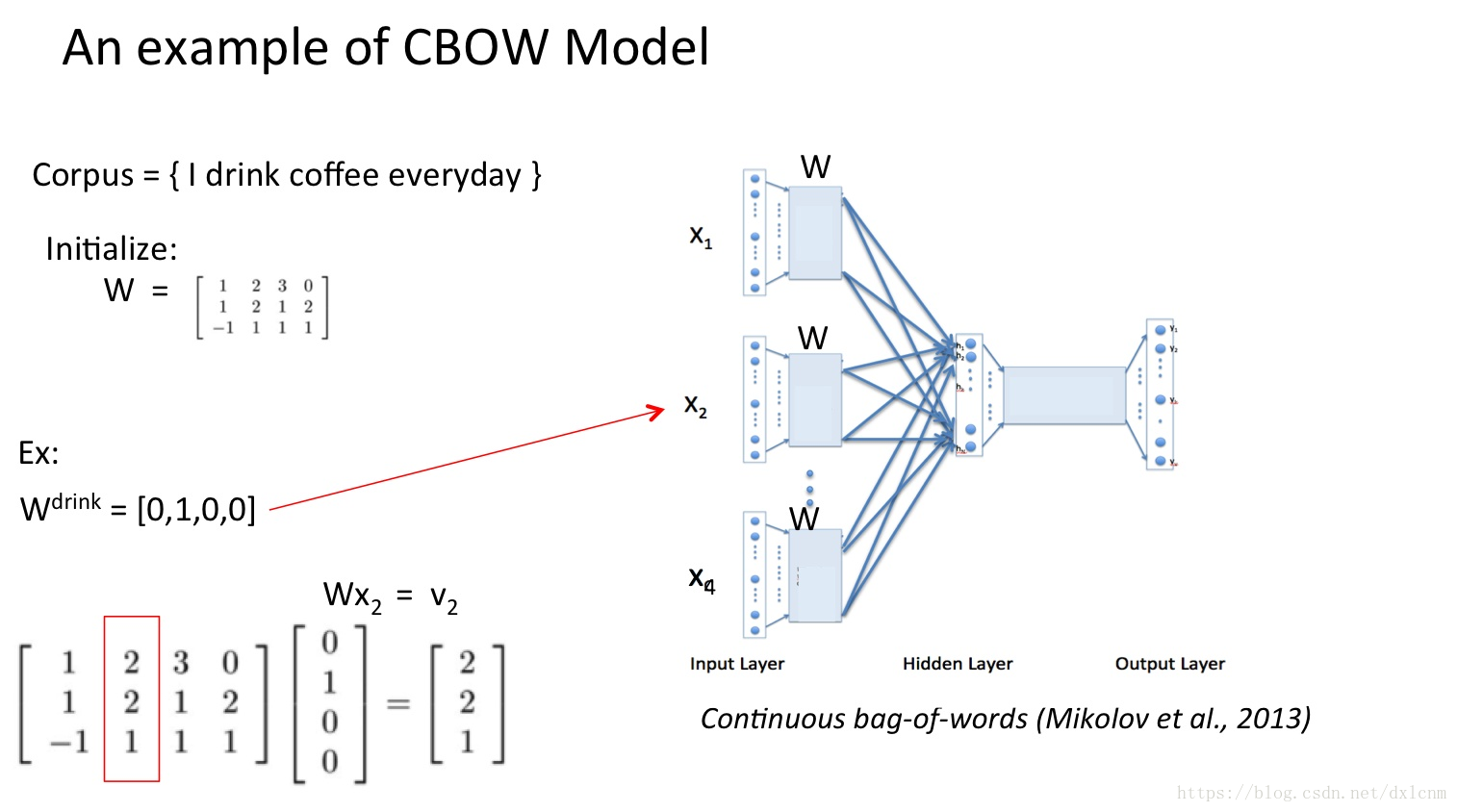
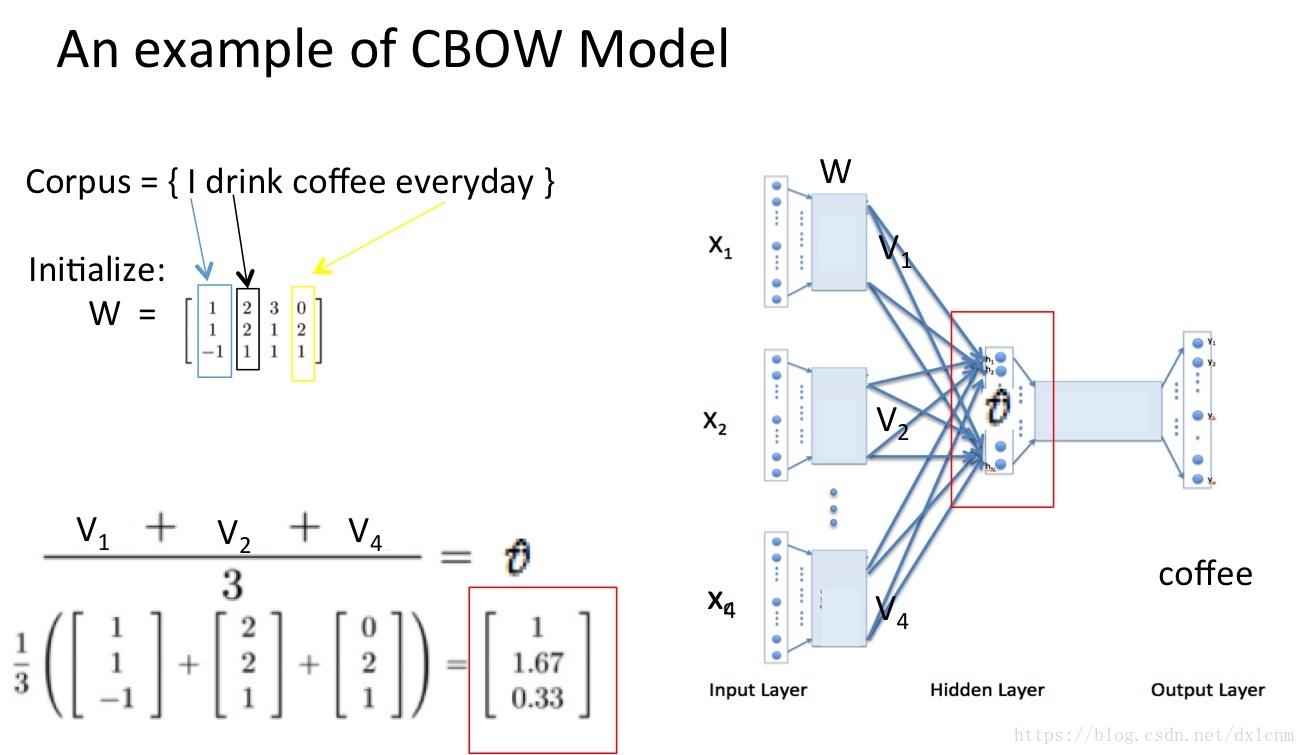
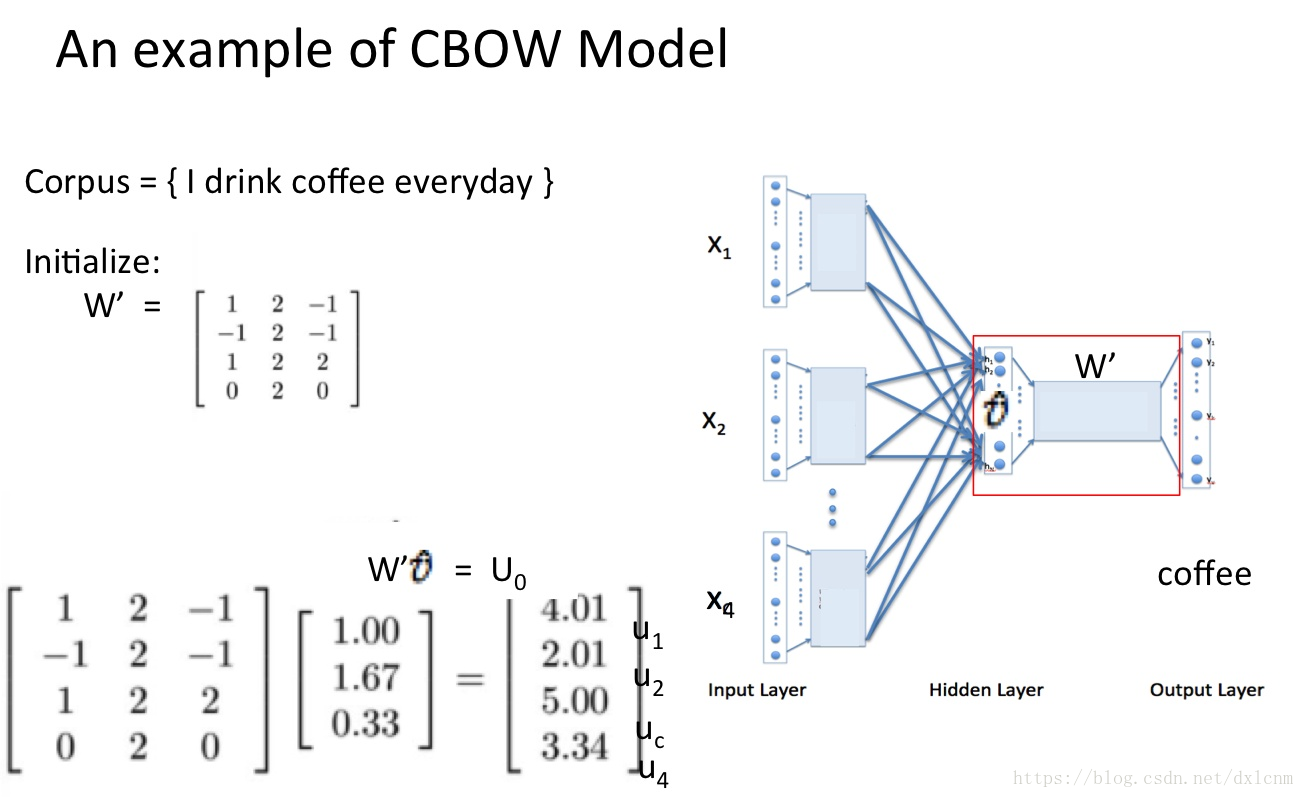
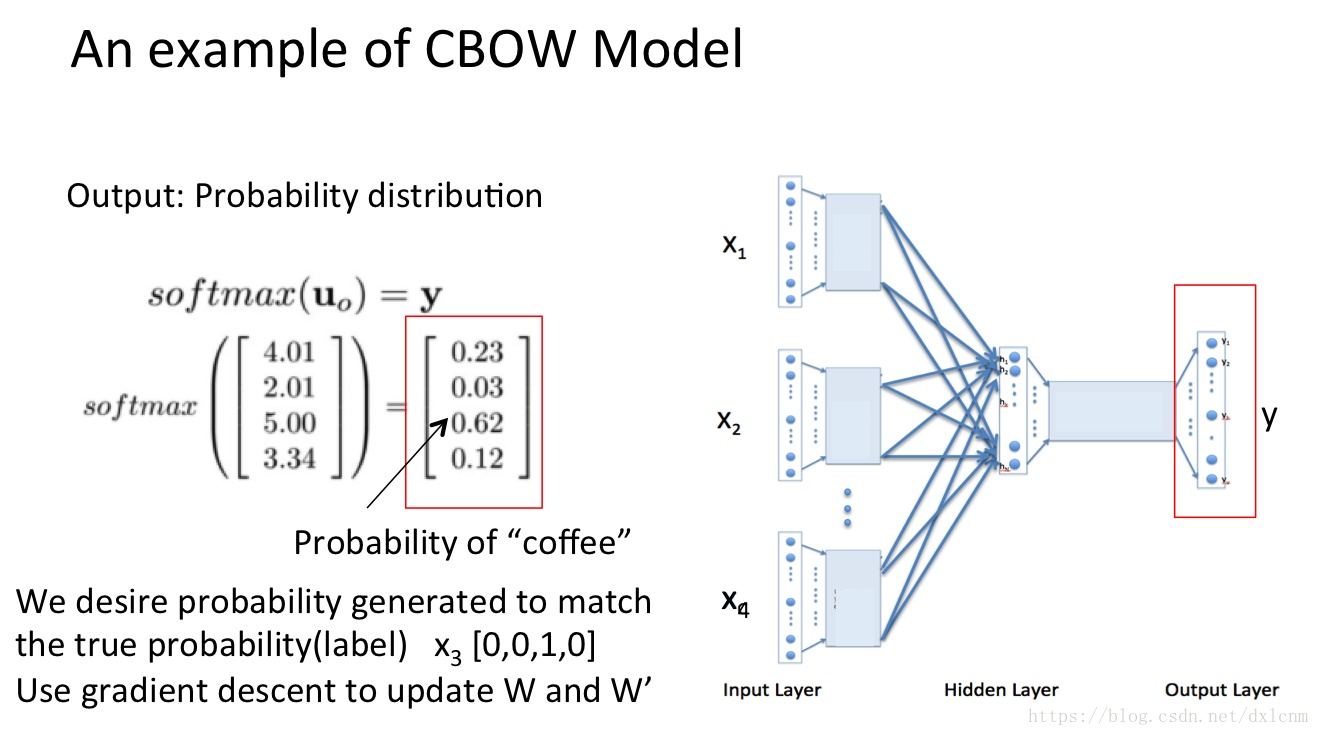
任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。
SKip-Gram模型
首先,我们建立一个10000个词的词典,输入的单词就是一个的10000维one-hot向量,而网络的输出也是一样 10,000维的向量,代表每个词预测的概率
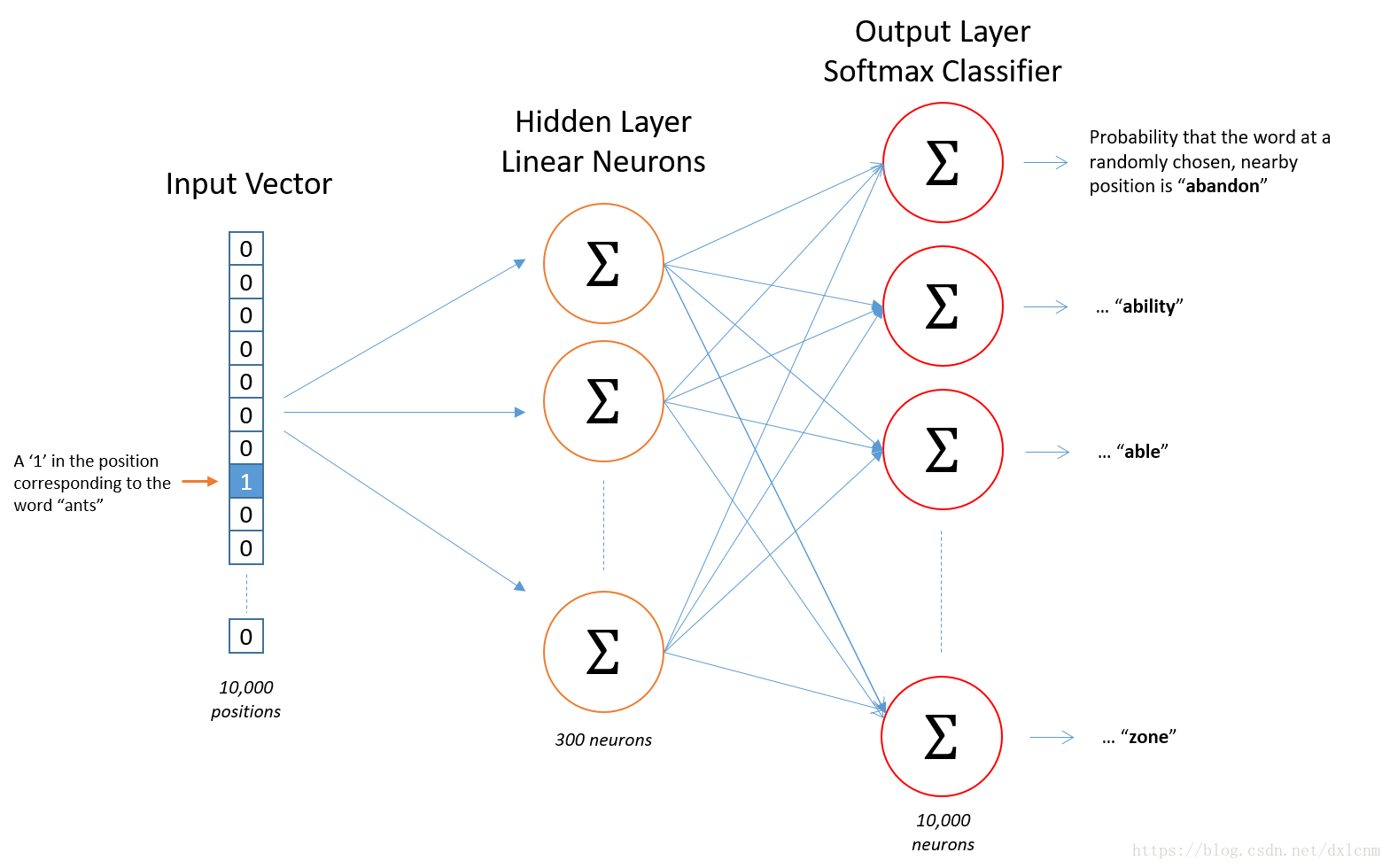
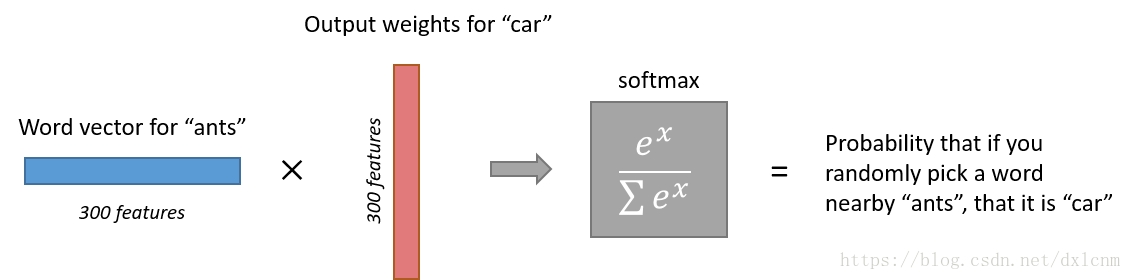
模型小trick

















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









