






使用Seaborn进行可视化
Matplotlib已经证明了自己是一个异常有用和流行的可视化工具,但即使是狂热的用户也承认它有很多不足的地方。下面是一些经常被提出来关于Matplotlib的吐槽:
- 在2.0版之前,Matplotlib默认值不总是最好的选择。因为它是基于MATLAB circa 1999的,这一点经常会被吐槽。
- Matplotlib的API相对来说比较底层,当然可以用来创建复杂的统计图表,但是经常需要撸很多冗长的代码。
- Matplotlib比Pandas开发早了超过10年,然而却还不支持直接使用Pandas的
DataFrame。为了将Pandas的DataFrame可视化,你必须将每个Series提取出来并组合成合适的格式。如果能够提供直接使用DataFrame的标签进行图表可视化的工具会方便的多。
上述问题可以通过Seaborn得到解答。Seaborn在Matplotlib之上提供了一套API,包括合理的默认样式和颜色,为通用统计报表设计的简单的高层函数和对Pandas的DataFrame的集成。
公平的说,Matplotlib团队也在改进这些问题:近期的版本增加了plt.style工具(参见自定义matplotlib:配置和样式单),开始让Matplotlib更加无缝地对接Pandas的数据。2.0版本会使用新的默认样式单用来改进目前的样式问题。但是对于我们刚才讨论的问题来说,Seaborn依然是一个很有用的扩展。
Seaborn 对比 Matplotlib
下面的例子是一个简单的随机趋势数据的例子,在Matplotlib使用经典的图表样式和颜色绘制。先进行标准导入:
import matplotlib.pyplot as plt
plt.style.use('classic')
%matplotlib inline
import numpy as np
import pandas as pd
然后创建随机趋势的数据:
# 创建一些随机数据
rng = np.random.RandomState(0)
x = np.linspace(0, 10, 500)
y = np.cumsum(rng.randn(500, 6), 0)
绘制简单折线图:
# 使用默认样式绘制图表
plt.plot(x, y)
plt.legend('ABCDEF', ncol=2, loc='upper left');
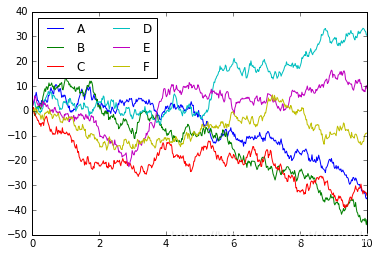
虽然结果包含了所有我们希望涵盖的信息,但是它展现的形式并不是特别的美观,和21世纪的数据可视化效果比较起来甚至显得有一点老土。
现在让我们看一看Seaborn的结果。正如我们看到的,Seaborn有很多的自己的高层绘图函数,但是它也覆盖了Matplotlib默认参数并且能使用更简单的Matplotlib代码脚本产生复杂的输出结果。我们可以通过调用Seaborn的set()函数设置Seaborn的样式。按照惯例Seaborn被载入成别名sns:
import seaborn as sns
sns.set()
现在我们来产生同样的折线图:
# 所有的代码与上例中的代码一样
plt.plot(x, y)
plt.legend('ABCDEF', ncol=2, loc='upper left');
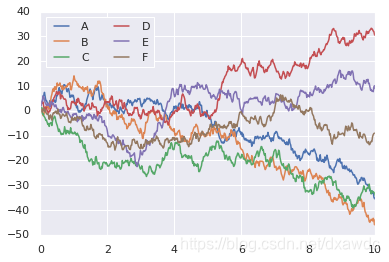
嗯,好看多了。
探索 Seaborn 图表
Seaborn的主要设计思想是提供一套高层的接口来创建各种各样的统计数据报表,甚至与一些统计模型适应。
下面让我们看看Seaborn中一些数据集和图表类型。请注意所有下面介绍到的内容都可以通过Matplotlib(实际上是Seaborn的底层)实现,但是Seaborn的API用起来方便多了。
直方图、KDE 和 密度
通常在统计数据可视化当中,绘制直方图和变量的联合分布可能就是你全部的需求。我们已经在Matplotlib中相对直接的展示过这种技巧:
下面代码将normed参数改为density。
data = np.random.multivariate_normal([0, 0], [[5, 2], [2, 2]], size=2000)
data = pd.DataFrame(data, columns=['x', 'y'])
for col in 'xy':
plt.hist(data[col], density=True, alpha=0.5)
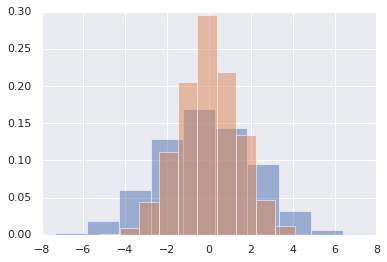
相对于直方图,我们可以使用核密度估计(KDE)来获得一个平滑的估计图,在Seaborn中调用sns.kdeplot得到:
for col in 'xy':
sns.kdeplot(data[col], shade=True)
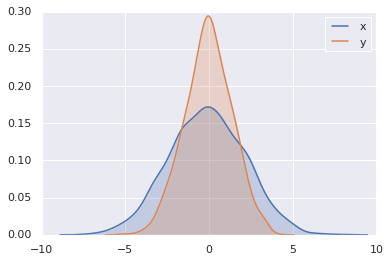
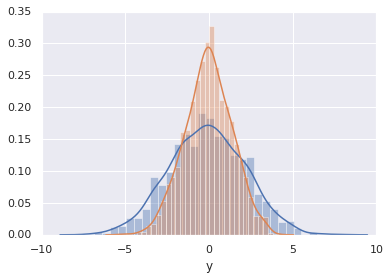
直方图和KDE可以使用distplot组合输出:
sns.distplot(data['x'])
sns.distplot(data['y']);
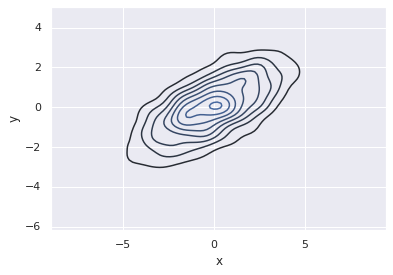
如果我们将完整的二维数据集传递给kdeplot,我们会得到数据的二维可视化图:
译者注:新版Seaborn的kdeplot函数不再支持传递二维数据,需要拆分成两个参数,因此下面的代码改为两个参数的调用方式。
sns.kdeplot(data.x, data.y);
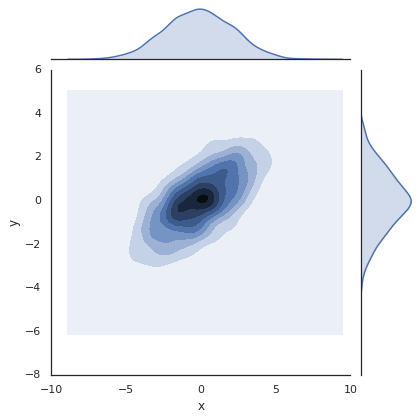
我们可以使用sns.jointplot函数同时绘制联合分布和边缘分布。下例中,我们将图表背景改为白色:
with sns.axes_style('white'):
sns.jointplot("x", "y", data, kind='kde');
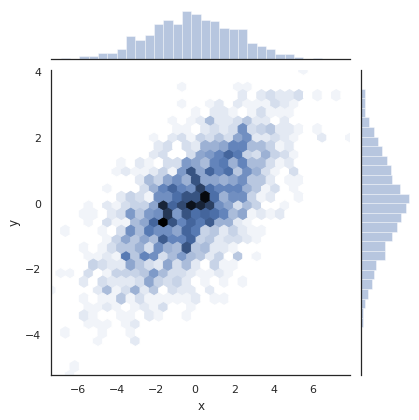
我们还可以传递其他的参数到jointplot,例如,使用六边形联合分布和直方图:
with sns.axes_style('white'):
sns.jointplot("x", "y", data, kind='hex')
散点图矩阵
当你将联合分布图推广到更多的维度时,你就会获得散点图矩阵。当你希望将所有属性两两组成一对来分析多维数据时是非常有用的。
我们使用著名的鸢尾花数据集来展示散点图矩阵,里面列出了三种不同种鸢尾花的花瓣和花萼的测量值:
iris = sns.load_dataset("iris")
iris.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
传递样本数据集调用sns.pairplot函数可以很容易的展示多维数据的关系:
译者注:下面代码中的size已经过时,修改为height。
sns.pairplot(iris, hue='species', height=2.5);
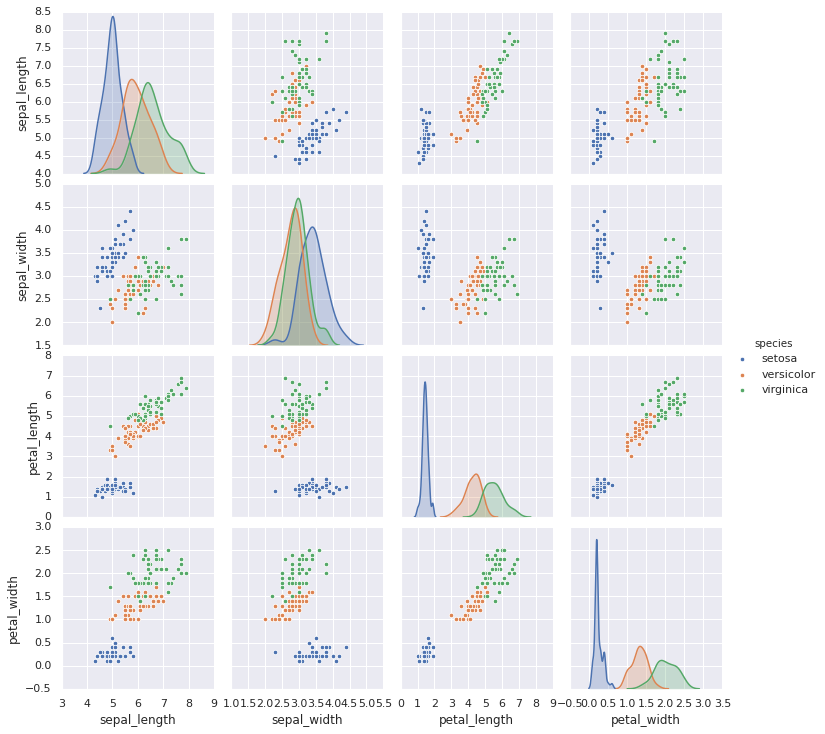
多面直方图
有些情况下展示数据的最好方式通过子数据集的直方图。Seaborn的FacetGrid将它变得非常简单。我们首先查看一些餐厅工作人员获得小费的数据情况,这是通过不同的指标数据获得的数据集:
译者注:下面代码将直接从data目录中读取tips.csv文件,因为Seaborn已经无法从网上下载tips数据集。
import pandas as pd
tips = pd.read_csv('data/tips.csv')
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
tips['tip_pct'] = 100 * tips['tip'] / tips['total_bill']
grid = sns.FacetGrid(tips, row="sex", col="time", margin_titles=True)
grid.map(plt.hist, "tip_pct", bins=np.linspace(0, 40, 15));
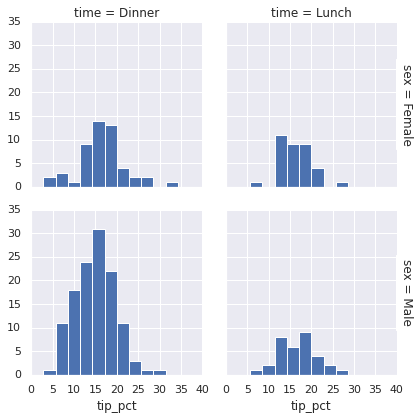
因子图
因子图也可以很好的展现这个数据。它允许你将一个参数的分布按照另一个参数进行分桶再展示在图表中:
译者注:factorplot函数已过时,下面代码更新为了catplot函数。
with sns.axes_style(style='ticks'):
g = sns.catplot("day", "total_bill", "sex", data=tips, kind="box")
g.set_axis_labels("Day", "Total Bill");
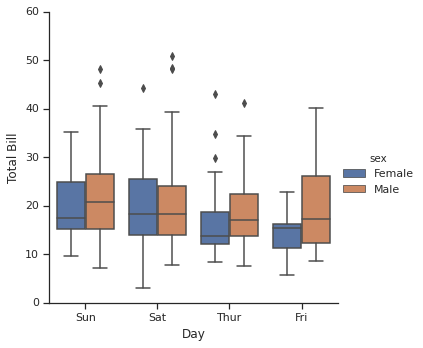
联合分布
类似前面的散点图矩阵,我们可以使用sns.jointplot来展示不同数据集中间的联合分布,以及它们的边缘分布情况:
with sns.axes_style('white'):
sns.jointplot("total_bill", "tip", data=tips, kind='hex')
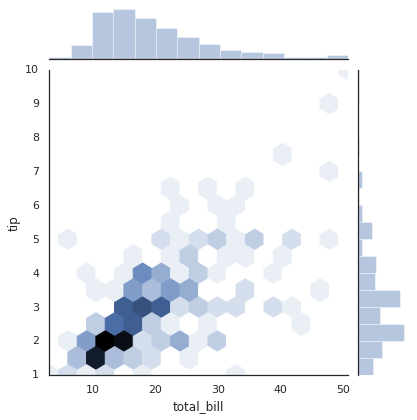
联合分布图还可以自动进行核密度估计以及回归:
sns.jointplot("total_bill", "tip", data=tips, kind='reg');
柱状图
时间序列可以使用sns.factorplot进行图表绘制。在下例中,我们会使用在聚合与分组中使用过的行星数据:
译者注:同样,下面的factorplot因为过时被catplot取代。
planets = sns.load_dataset('planets')
planets.head()
| method | number | orbital_period | mass | distance | year | |
|---|---|---|---|---|---|---|
| 0 | Radial Velocity | 1 | 269.300 | 7.10 | 77.40 | 2006 |
| 1 | Radial Velocity | 1 | 874.774 | 2.21 | 56.95 | 2008 |
| 2 | Radial Velocity | 1 | 763.000 | 2.60 | 19.84 | 2011 |
| 3 | Radial Velocity | 1 | 326.030 | 19.40 | 110.62 | 2007 |
| 4 | Radial Velocity | 1 | 516.220 | 10.50 | 119.47 | 2009 |
with sns.axes_style('white'):
g = sns.catplot("year", data=planets, aspect=2,
kind="count", color='steelblue')
g.set_xticklabels(step=5)
我们还可以使用发现这些行星的方法来更加细致的分析这个数据集:
with sns.axes_style('white'):
g = sns.catplot("year", data=planets, aspect=4.0, kind='count',
hue='method', order=range(2001, 2015))
g.set_ylabels('Number of Planets Discovered')
想获得更多使用Seaborn绘制图表的内容,请参考Seaborn在线文档、教程以及Seaborn图库。
例子:马拉松完成时间分析
下面我们来看一下使用Seaborn分析和可视化马拉松完成结果数据的例子。作者已经从网上将数据爬取了下来,组合了这些数据并且删除了身份信息,数据放在GitHub上面提供下载(如果你对使用Python进行网页爬取感兴趣,作者推荐Ryan Mitchell写的Python网络爬取)。我们首先下载这个数据,然后使用Pandas将数据载入:
译者注:本仓库notebooks/data目录下带有数据文件,下面的载入语句目录相应修改。
# !curl -O https://raw.githubusercontent.com/jakevdp/marathon-data/master/marathon-data.csv
data = pd.read_csv('data/marathon-data.csv')
data.head()
| age | gender | split | final | |
|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 |
| 1 | 32 | M | 01:06:26 | 02:09:28 |
| 2 | 31 | M | 01:06:49 | 02:10:42 |
| 3 | 38 | M | 01:06:16 | 02:13:45 |
| 4 | 31 | M | 01:06:32 | 02:13:59 |
默认情况下,Pandas将时间列读取载入成Python字符串(Pandas中的object类型);我们可以通过查看DataFrame的dtypes属性知道:
data.dtypes
age int64
gender object
split object
final object
dtype: object
让我们提供一个转换器函数来修正这一列:
import datetime
def convert_time(s):
h, m, s = map(int, s.split(':'))
return datetime.timedelta(hours=h, minutes=m, seconds=s)
data = pd.read_csv('data/marathon-data.csv',
converters={'split':convert_time, 'final':convert_time})
data.head()
| age | gender | split | final | |
|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 |
| 1 | 32 | M | 01:06:26 | 02:09:28 |
| 2 | 31 | M | 01:06:49 | 02:10:42 |
| 3 | 38 | M | 01:06:16 | 02:13:45 |
| 4 | 31 | M | 01:06:32 | 02:13:59 |
data.dtypes
age int64
gender object
split timedelta64[ns]
final timedelta64[ns]
dtype: object
这样看起来就正常了。为了Seaborn绘图工具能正常工作,为这个数据集添加上两列,将时间转为秒数:
data['split_sec'] = data['split'].astype(int) / 1E9
data['final_sec'] = data['final'].astype(int) / 1E9
data.head()
| age | gender | split | final | split_sec | final_sec | |
|---|---|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 | 3938.0 | 7731.0 |
| 1 | 32 | M | 01:06:26 | 02:09:28 | 3986.0 | 7768.0 |
| 2 | 31 | M | 01:06:49 | 02:10:42 | 4009.0 | 7842.0 |
| 3 | 38 | M | 01:06:16 | 02:13:45 | 3976.0 | 8025.0 |
| 4 | 31 | M | 01:06:32 | 02:13:59 | 3992.0 | 8039.0 |
要初步查看目前数据的情况,我们可以在数据集上绘制一个联合分布图:
with sns.axes_style('white'):
g = sns.jointplot("split_sec", "final_sec", data, kind='hex')
g.ax_joint.plot(np.linspace(4000, 16000),
np.linspace(8000, 32000), ':k')
上图中的点线表示,如果一个人在一场马拉松比赛中保持了一个完美的匀速,那么他的成绩将位于这条线上。事实上这个分布都处于这条线上的原因,也是显而易见的,大多数人随着马拉松的进程都会慢下来。如果你有参加过竞技马拉松比赛,你可能就会了解那些不符合这个趋势的选手,即后半程跑的更快的参赛者,被称为后半程加速。
让我们再创建一个列,用来衡量每个选手是后半程加速还是前半程跑的快:
data['split_frac'] = 1 - 2 * data['split_sec'] / data['final_sec']
data.head()
| age | gender | split | final | split_sec | final_sec | split_frac | |
|---|---|---|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 | 3938.0 | 7731.0 | -0.018756 |
| 1 | 32 | M | 01:06:26 | 02:09:28 | 3986.0 | 7768.0 | -0.026262 |
| 2 | 31 | M | 01:06:49 | 02:10:42 | 4009.0 | 7842.0 | -0.022443 |
| 3 | 38 | M | 01:06:16 | 02:13:45 | 3976.0 | 8025.0 | 0.009097 |
| 4 | 31 | M | 01:06:32 | 02:13:59 | 3992.0 | 8039.0 | 0.006842 |
sns.distplot(data['split_frac'], kde=False);
plt.axvline(0, color="k", linestyle="--");
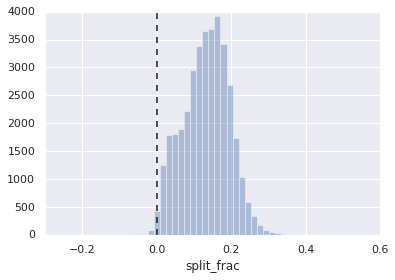
sum(data.split_frac < 0)
251
将近40000名选手中,仅有250人是使用后半程加速完成马拉松比赛的。
让我们观察一下这个半程加速分布列和其他列的相关性。你应该也知道应该使用pairgrid绘制散点图矩阵了:
g = sns.PairGrid(data, vars=['age', 'split_sec', 'final_sec', 'split_frac'],
hue='gender', palette='RdBu_r')
g.map(plt.scatter, alpha=0.8)
g.add_legend();
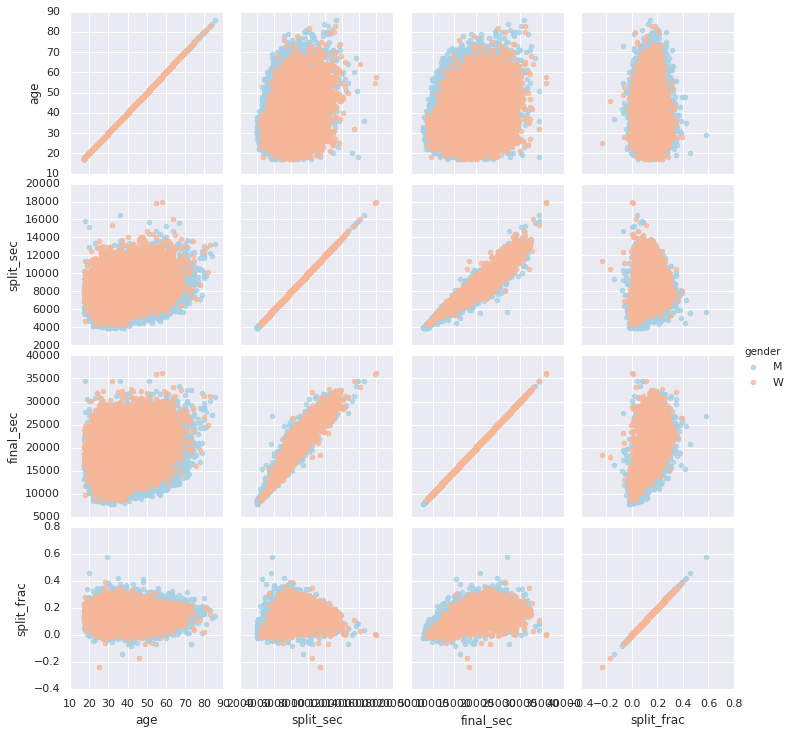
从上图得知,半程加速分布似乎与年龄没有特别大的相关性,但是确实和最终完成时间有相关性:成绩越好的选手越善于平均分配前后半程的速度和时间。
这里比较有趣的是性别的差异。让我们将这两个组的半程加速分布数据用直方图展示出来:
sns.kdeplot(data.split_frac[data.gender=='M'], label='men', shade=True)
sns.kdeplot(data.split_frac[data.gender=='W'], label='women', shade=True)
plt.xlabel('split_frac');
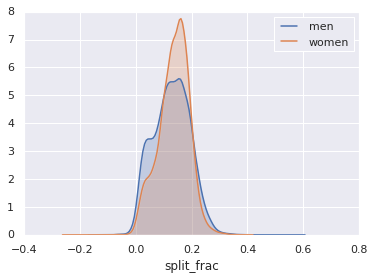
上图中有趣的地方是男性前后半程均匀速度和时间的数量比女性多很多。这几乎有点像一个双峰分布的形状了。让我们试着探寻里面的原因。
比较两个分布的好方法是使用小提琴图
sns.violinplot("gender", "split_frac", data=data,
palette=["lightblue", "lightpink"]);
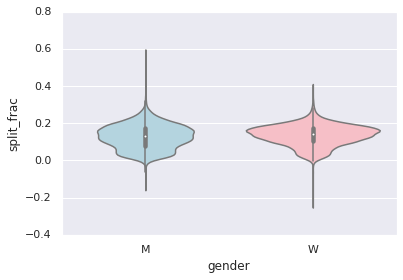
这也是一个比较男性和女性分布情况的方式。
让我们继续深入,根据年龄数据比较这些小提琴图。我们再创建一个列来表示每个选手的年龄段:
data['age_dec'] = data.age.map(lambda age: 10 * (age // 10)) # 10-20/20-30 等
data.head()
| age | gender | split | final | split_sec | final_sec | split_frac | age_dec | |
|---|---|---|---|---|---|---|---|---|
| 0 | 33 | M | 01:05:38 | 02:08:51 | 3938.0 | 7731.0 | -0.018756 | 30 |
| 1 | 32 | M | 01:06:26 | 02:09:28 | 3986.0 | 7768.0 | -0.026262 | 30 |
| 2 | 31 | M | 01:06:49 | 02:10:42 | 4009.0 | 7842.0 | -0.022443 | 30 |
| 3 | 38 | M | 01:06:16 | 02:13:45 | 3976.0 | 8025.0 | 0.009097 | 30 |
| 4 | 31 | M | 01:06:32 | 02:13:59 | 3992.0 | 8039.0 | 0.006842 | 30 |
men = (data.gender == 'M')
women = (data.gender == 'W')
with sns.axes_style(style=None):
sns.violinplot("age_dec", "split_frac", hue="gender", data=data,
split=True, inner="quartile",
palette=["lightblue", "lightpink"]);
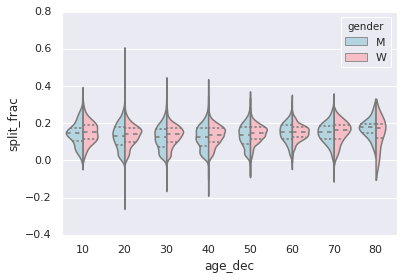
再看上图,我们可以发现男性和女性分布情况的区别:男性年龄处于20到50之间的时候,其半程平均程度的分布均比同年龄段女性的分布要更密集。
令我们惊讶的是,80岁以上的女性似乎在半程平均程度上优于所有年龄段和性别的分布。这也许是由于这个分布是来自一个很小的数据样本,因为这个年龄段的参加人数是很稀少的:
(data.age > 80).sum()
7
回到后半程加速的选手身上:它们是谁?是否后半程加速与比赛成绩有相关性?我们可以很容易的绘制这张图。调用regplot函数,它能自动的为数据找到一个线性回归预测:
g = sns.lmplot('final_sec', 'split_frac', col='gender', data=data,
markers=".", scatter_kws=dict(color='c'))
g.map(plt.axhline, y=0.1, color="k", ls=":");
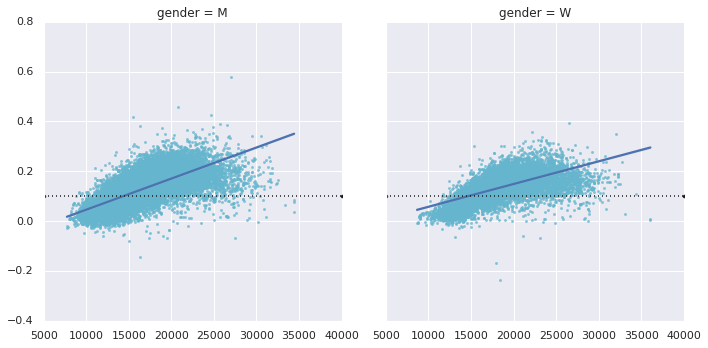
很明显了,成绩优秀的选手或者叫精英选手,是那些能在约15000秒或4个小时内完成的人。低于这个成绩的选手很少能在后半程加速完成比赛。

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









