



在日常生活中,我们或许会看到一些人手部不由自主地颤抖,走路时姿势僵硬、步伐缓慢,这些看似普通的症状,有可能是帕金森病在作祟。
帕金森病,又被称为震颤麻痹,是一种常见的老年神经系统退行性疾病。其发病根源在于大脑中黑质区域的多巴胺能神经元受损,致使多巴胺分泌减少,进而引发一系列运动和非运动症状。
帕金森病的运动症状十分典型。静止性震颤常为首发症状,安静状态下,患者手部、头部等部位会出现如搓药丸般的不自主颤抖,活动时症状减轻,入睡后消失。运动迟缓也是一大显著特征,患者完成任何动作都变得极为缓慢,简单的穿衣、洗漱等日常活动都困难重重。肌肉强直同样明显,肢体仿佛被固定住,活动时僵硬感十足,就像在转动生锈的机器。此外,患者还可能出现姿势平衡障碍,行走时身体前倾,难以保持平衡,极易摔倒。
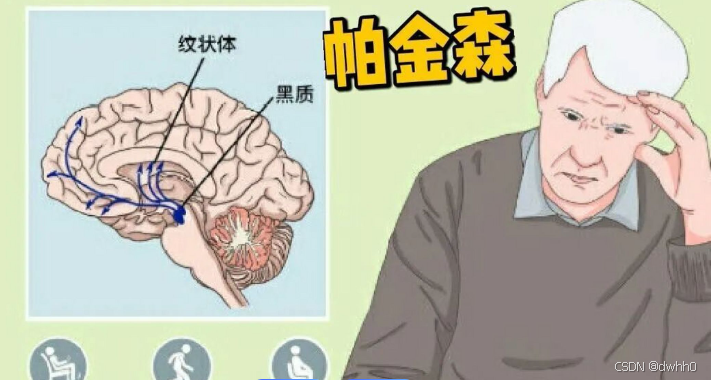
除运动症状外,帕金森病还伴有诸多非运动症状。嗅觉减退较为常见,患者常常难以分辨各种气味;睡眠障碍也很突出,失眠、多梦、睡眠中频繁惊醒等情况时有发生;便秘问题也困扰着许多患者,影响正常的生活节奏;同时,焦虑、抑郁等精神症状也较为普遍,部分患者还会出现认知障碍,严重影响生活质量。
目前,帕金森病的病因尚未完全明确,一般认为与遗传因素、环境因素、神经系统老化等多种因素相关。诊断主要依靠医生对患者症状的详细观察与评估,同时结合脑部影像学检查、嗅觉测试、神经电生理检查等辅助手段,以确保准确判断。
虽然帕金森病目前无法完全治愈,但通过药物治疗、手术治疗、康复治疗等综合手段,能够有效控制症状,延缓病情发展。药物治疗是主要方式,通过补充多巴胺等药物来改善症状。手术治疗如脑深部电刺激术,也能为部分患者带来显著改善。康复治疗则包括运动疗法、物理治疗等,有助于提高患者的运动能力和生活自理能力。
帕金森病给患者及其家庭带来了沉重的负担,我们需要给予他们更多的理解、关爱和支持。同时,也期待医学的不断进步,能够早日找到彻底治愈帕金森病的方法。


















 2749
2749




 到【灌水乐园】发言
到【灌水乐园】发言







