







一、基本概念
Adam(Adaptive Moment Estimation) 是一种结合了动量法(Momentum)和RMSProp优点的自适应学习率优化算法,由Diederik P. Kingma和Jimmy Ba于2014年提出,广泛应用于深度学习模型训练。
二、核心原理
Adam通过计算梯度的一阶矩(均值)和二阶矩(方差)估计,动态调整每个参数的学习率,其核心公式如下:
-
动量计算(一阶矩估计)
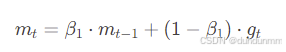
-
自适应学习率计算(二阶矩估计)
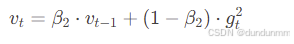
-
偏差修正(针对初始化的零偏置)
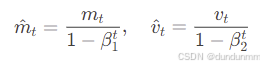
-
参数更新
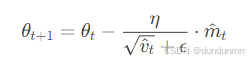
参数说明:
-
𝛽1,𝛽2:动量衰减率(默认0.9和0.999)
-
𝜂:初始学习率
-
𝜖:数值稳定性常数(通常1e-8)
三、优势与劣势
| 优势 | 劣势 |
|---|---|
| 自适应调整学习率,减少调参难度 | 内存占用较高(需保存一阶、二阶矩) |
| 适合稀疏梯度场景(如NLP任务) | 可能收敛到次优解(尤其在小数据集) |
| 对噪声数据鲁棒性强 | 超参数(如β)选择影响较大 |
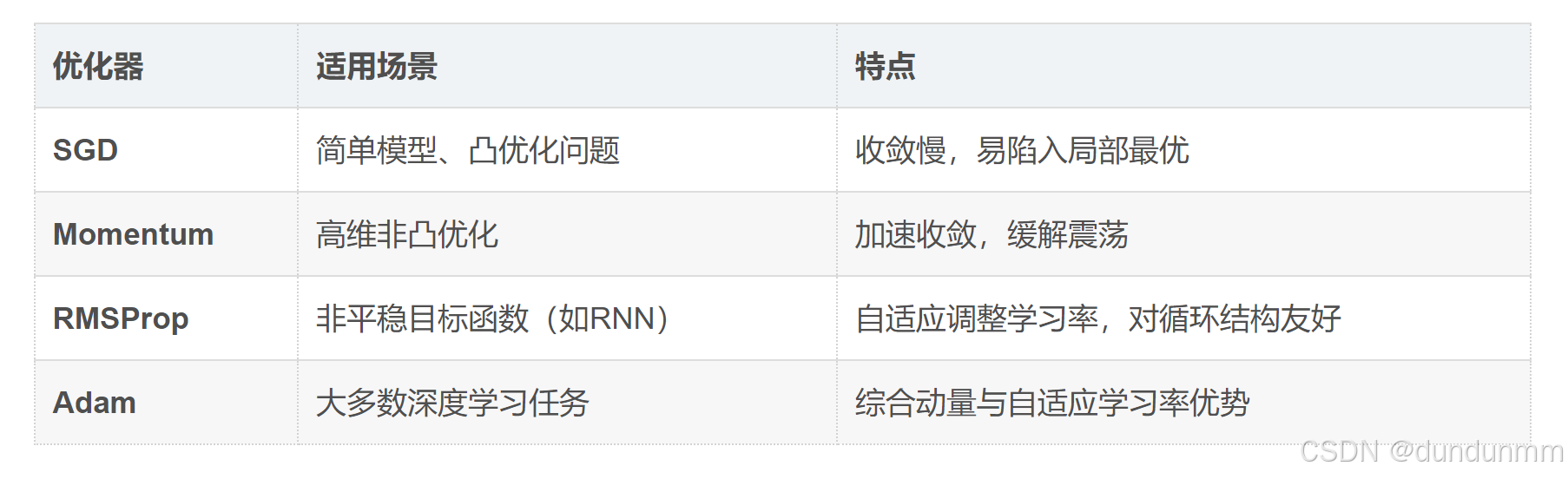
四、与其他优化器对比
| 优化器 | 适用场景 | 特点 |
|---|---|---|
| SGD | 简单模型、凸优化问题 | 收敛慢,易陷入局部最优 |
| Momentum | 高维非凸优化 | 加速收敛,缓解震荡 |
| RMSProp | 非平稳目标函数(如RNN) | 自适应调整学习率,对循环结构友好 |
| Adam | 大多数深度学习任务 | 综合动量与自适应学习率优势 |
五、实际应用技巧
-
学习率设置
-
默认学习率:𝜂=0.001
-
可尝试范围:10−5∼10−3
-
搭配学习率调度器(如CosineAnnealingLR)
-
-
参数调整策略
-
𝛽1:增大可增强动量效应(适合平稳梯度场景)
-
𝛽2:增大可抑制梯度方差波动(适合噪声数据)
-
-
代码实现示例(PyTorch)
import torch.optim as optim # 定义模型 model = YourNeuralNetwork() # 初始化Adam优化器 optimizer = optim.Adam( model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0 # L2正则化系数 ) # 训练循环 for epoch in range(num_epochs): for data, target in dataloader: optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step()
六、在产教融合模型中的典型应用
结合用户研究场景,Adam优化器可在以下模块发挥作用:
-
智能需求匹配系统
-
应用场景:训练神经网络模型,动态映射产业需求与课程知识图谱。
-
优势:快速收敛,适应需求数据的动态变化(如贵州大数据岗位技能要求)。
-
-
虚拟实训工场
-
应用场景:优化基于AIGC的虚拟仿真模型(如数字孪生技术)。
-
代码示例(TensorFlow/Keras):
model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.0005), loss='mse', metrics=['accuracy'] )
-
-
动态课程生成模型
-
调参建议:使用
weight_decay参数防止过拟合(如生成重复性教学案例)。
-
七、常见问题与解决方案
| 问题现象 | 原因分析 | 解决方案 |
|---|---|---|
| 训练初期loss剧烈震荡 | 初始学习率过高 | 降低学习率至1e-4 ~ 1e-5 |
| 后期收敛速度变慢 | 未使用学习率衰减 | 添加ReduceLROnPlateau调度器 |
| 模型泛化性能差 | 过拟合 | 增加weight_decay(L2正则化) |
八、进阶优化策略
-
AdamW优化器
-
改进点:解耦权重衰减与梯度更新,提升泛化能力。
-
适用场景:需要强正则化的复杂模型(如Transformer)。
-
-
NAdam(Nesterov-accelerated Adam)
-
改进点:引入Nesterov动量,加速收敛。
-
目前深度学习中较为常用的经典优化器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









