







缓存算法、热点数据与更新缓存、更新缓存与原子性、缓存崩溃与快速恢复
合理应用缓存也是一个选择问题;
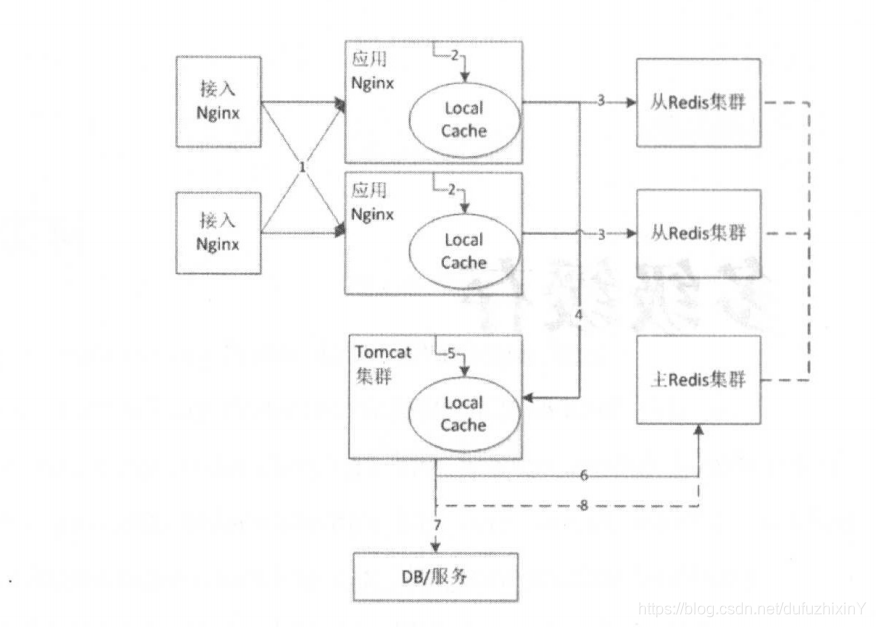
多级缓存:
Nginx本地缓存、分布式缓存(底层为redis/redis主从架构)、tomcat堆缓存
nginx本地缓存解决热点缓存问题;
分布式缓存减少访问回源率;
tomcat堆缓存解决缓存失效/崩溃之后的冲击;
过期与不过期:
①不设置过期时间条件:
对数据一致性要求不高,数据量不是很大,考虑定期全量更新同步缓存;
②设置过期时间条件:
缓存其他系统的数据、空间有限时、低频热点数据
③过期时间的设置需要根据场景来进行选择;
维度化缓存与增量缓存:
如果一个数据的维度很多,如商品的信息,可以将其根据维度拆分成基础属性、规格参数、上下架、商品介绍等来进行缓存,并且在更新时进行增量更新;
大Value缓存:
考虑使用多线程实现的缓存,如Memcached;
拆分成小的value;
对value进行压缩
热点缓存:
①热点缓存的访问会非常的高,要考虑高可用;
②缓存采用主从结构,并且从结构要根据情况增多;
③可以在应用层(客户端)增加一层本地缓存,缓存的时间具体场景具体设置
分布式缓存:
①采用分片实现,将数据分散到多个实例或多台服务器;
②算法为取模或一致性哈希;
③使用redis时,考虑redis-cluster分布式集群方案;
应用负载均衡:
①采用轮询或者一致性哈希;
②轮询:请求更加均匀,缓存命中率随服务器增多下降;
③一致性哈希:相同请求会转发给同一台服务器,缓存命中率可以控制,但存在单台服务器负载过重问题;

热点数据与更新缓存:几种方案
①单机全量缓存+主从
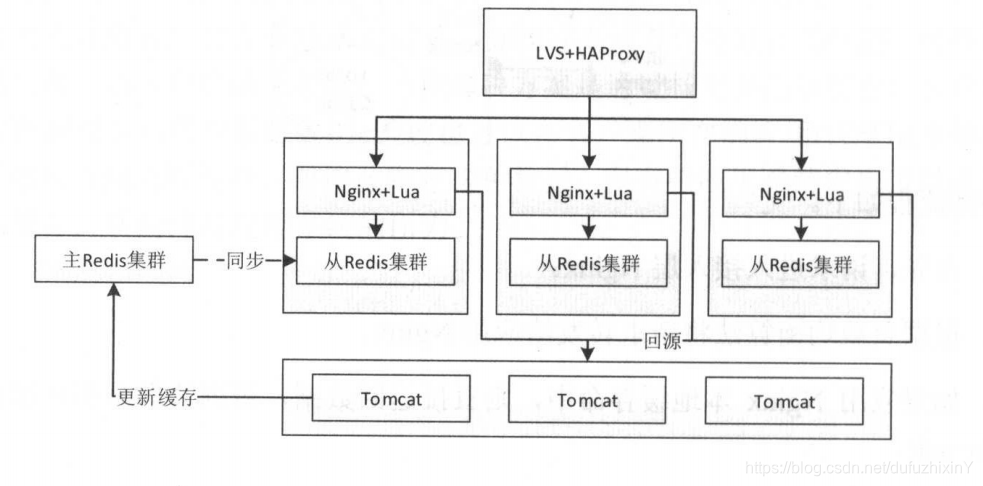
②分布式缓存:
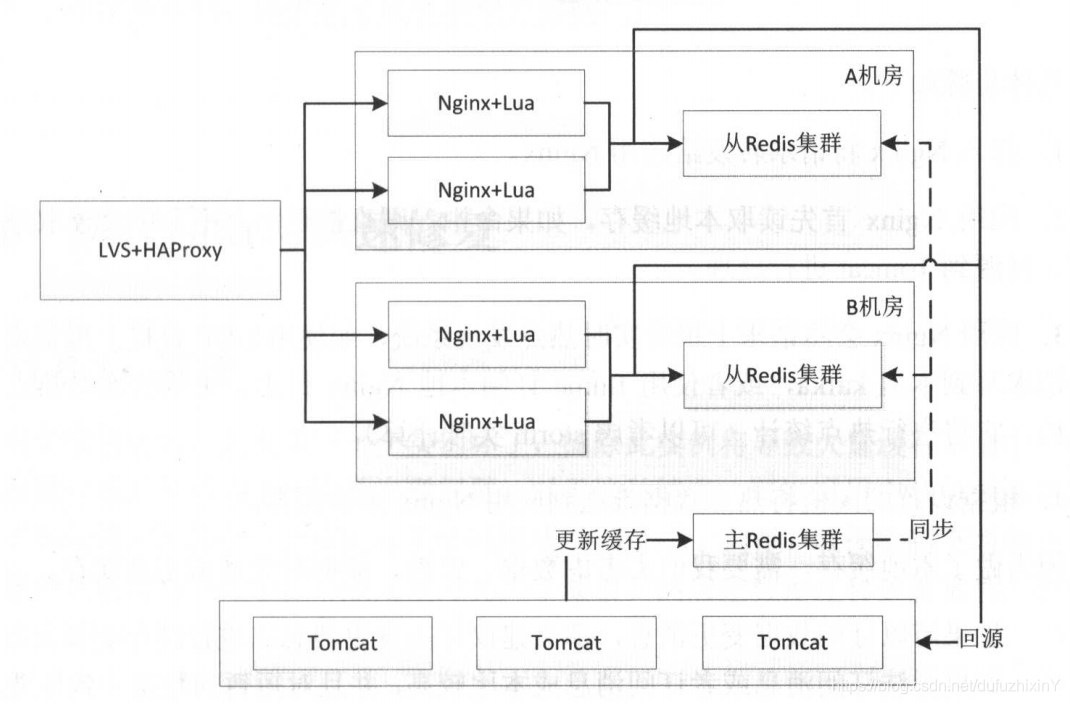
<1>用一致性哈希还是轮询?
正常情况用哈希;特定的可以设置一个阈值,超过时自动降级为轮询;提前可以预知的情况则预先将数据推送到nginx,并才用轮询;
③实时热点发现系统:
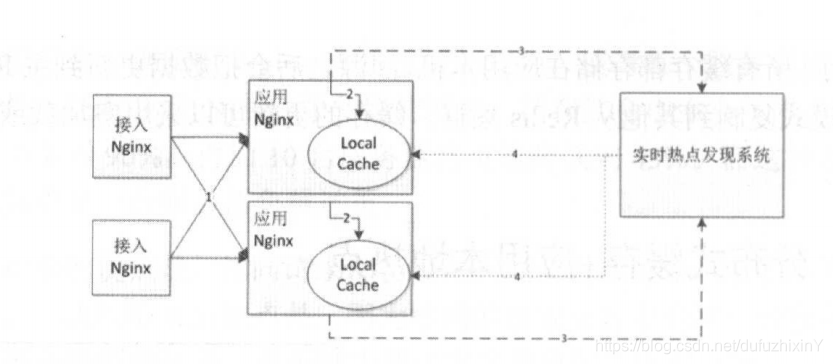
<1>应用Nginx将请求上报给实时热点发现系统:
udp直接上报;kafka;使用flume订阅本地Nginx日志

更新缓存与原子性:防止数据变成脏数据
①使用时间戳、版本等方式;
②使用redis,天然单线程;
③上锁,使用分布式锁;
④使用canal订阅数据库binlog;
⑤使用队列,然后单线程更新,制定相应规则将请求分别装入不同的队列;
缓存崩溃与快速修复:
①采用了取模的方式时:
<1>采用主从模式,消除某个实例坏掉需要摘除时导致的大量缓存不命中情况
<2>流量迁移:增加节点时,先建立一个新的集群将数据导入过去,并迁移流量;
②快速恢复:
<1>主从机制,做好冗余;
<2>没有备份的情况下,采取部分用户降级,后台通过Worker预热缓存数据;

















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









