







官方文档-》https://prestodb.github.io/docs/current/admin/resource-groups.html
注意presto的版本需要大于0.153,而且开源版本,即使算上非资源组的集群维度,在使用资源这一块最多只能限制任务的执行时间、使用内存、核时,如果在工作中看到限制任务sql长度、任务拉取数据量的限制,这两个确实在历史版本中存在过,但是后期版本被删除了,因为在长度上有jvm的最长字节限制,而可拉取的数据量在开源版本下是通过限制内存来间接控制的,但是也有二次开发的服务供应商自己开发了对应的能力
presto在多用户的场景下,可以实现yarn资源对列等价的能力,不过和yarn提供刷新命令不同的是,presto的资源组配置更改生效时机取决于你选择的配置方式。资源组使得多用户的资源可以被隔离,配置的方式是在presto的etc目录下,创建resource-groups.properties文件,写入如下内容
resource-groups.configuration-manager=file
resource-groups.config-file=etc/resource_groups.json
resource-groups.configuration-manager:意思为通过什么方式配置资源队列,目前只可以通过数据库和json文件两种配置方式,分别对应db和file。如果你选择db,那么你的资源组配置更改是立即生效的,但目前只能配置到mysql上,配置方法见官网,不过通常用的都是文件,文件方式更改资源组配置需要重启服务
resource-groups.config-file:资源队列配置文件的路径
随后创建对应的etc/resource_groups.json文件,写入如下的内容
{
"rootGroups": [
{
"name": "global",
"softMemoryLimit": "80%",
"hardConcurrencyLimit": 100,
"maxQueued": 1000,
"schedulingPolicy": "weighted",
"jmxExport": true,
"subGroups": [
{
"name": "data_definition",
"softMemoryLimit": "10%",
"hardConcurrencyLimit": 5,
"maxQueued": 100,
"schedulingWeight": 1
},
{
"name": "adhoc",
"softMemoryLimit": "10%",
"hardConcurrencyLimit": 50,
"maxQueued": 1,
"schedulingWeight": 10,
"subGroups": [
{
"name": "other",
"softMemoryLimit": "10%",
"hardConcurrencyLimit": 2,
"maxQueued": 1,
"schedulingWeight": 10,
"schedulingPolicy": "weighted_fair",
"subGroups": [
{
"name": "${USER}",
"softMemoryLimit": "10%",
"hardConcurrencyLimit": 1,
"maxQueued": 100
}
]
},
{
"name": "bi-${toolname}",
"softMemoryLimit": "10%",
"hardConcurrencyLimit": 10,
"maxQueued": 100,
"schedulingWeight": 10,
"schedulingPolicy": "weighted_fair",
"subGroups": [
{
"name": "${USER}",
"softMemoryLimit": "10%",
"hardConcurrencyLimit": 3,
"maxQueued": 10
}
]
}
]
},
{
"name": "pipeline",
"softMemoryLimit": "80%",
"hardConcurrencyLimit": 45,
"maxQueued": 100,
"schedulingWeight": 1,
"jmxExport": true,
"subGroups": [
{
"name": "pipeline_${USER}",
"softMemoryLimit": "50%",
"hardConcurrencyLimit": 5,
"maxQueued": 100
}
]
}
]
},
{
"name": "admin",
"softMemoryLimit": "100%",
"hardConcurrencyLimit": 50,
"maxQueued": 100,
"schedulingPolicy": "query_priority",
"jmxExport": true
}
],
"selectors": [
{
"user": "bob",
"group": "admin"
},
{
"source": ".*pipeline.*",
"queryType": "DATA_DEFINITION",
"group": "global.data_definition"
},
{
"source": ".*pipeline.*",
"group": "global.pipeline.pipeline_${USER}"
},
{
"source": "jdbc#(?<toolname>.*)",
"clientTags": ["hipri"],
"group": "global.adhoc.bi-${toolname}.${USER}"
},
{
"group": "global.adhoc.other.${USER}"
}
],
"cpuQuotaPeriod": "1h"
}
presto的资源组配置分为组定义、用户选择器、 cputime配额周期这三个部分。资源组的定义参数含义如下
1、name(必填):资源组的名称。
2、maxQueued(必填):资源组中可以排队的查询最大数量。如果达到此限制,新查询将被拒绝提交。
3、hardConcurrencyLimit(必填):资源组可以同时运行的最大查询数。
4、softMemoryLimit(必填):资源组可以使用的最大内存量。这可以用绝对值(如“10GB”)或指定为父组内存的百分比(如“50%”)来指定。
5、hardCpuLimit(可选):该组在一段时间内可以使用的最大CPU时间,到了这个值新的任务即使资源组还有cpu配额,也会进入排队。一般都不配,因为presto的cputime配置格式用的是d、h这种,配不明白反而会弄巧成拙,有总体的资源限制就够了
6、softCpuLimit(可选):这个配置也是该组在一段时间内可以使用的最大CPU时间,但是触发它的后果不是新查询进入排队,而是组的最大并发性将线性降低。并注意如果你配置了softCpuLimit的值,那么必须指定hardCpuLimit,且不能大于hardCpuLimit
7、softConcurrencyLimit(可选):对并发查询数量的软限制。如果超过此限制,调度器将尝试阻止新查询开始,但不会强制停止正在运行的查询。
8、schedulingPolicy(可选):决定如何在资源组内安排查询的策略。这可以设置为四个值之一,fair、weighted、weighted_fair或query_priority
fair(默认):排队的查询以进先出的方式处理,如果子组有任何排队,则必须轮流开始新的查询。
weighted_fair:根据子组的权重和已同时运行的查询数综合选择子组。子组运行查询的预期份额是根据当前所有符合条件的子组的权重计算的。选择相对于其份额的并发性最小的子组来开始下一个查询。通俗理解就是那个子组在运行的任务最少那个先来
weighted: 根据优先级(通过query_priority会话属性指定)随机选择队列中的查询。并综合子组的权重启动新查询。
query_priority:所有子组也必须配置query_priority。严格根据其优先级选择排队查询。商用场景用的最多。
9、schedulingWeight(可选):当父组使用weighted调度策略时,资源组的权重。更高的权重意味着该组获得了父组资源的更大份额。
10、jmxExport(可选):如果设置为true,资源组的统计数据将通过JMX导出。默认为false。
11、perQueryLimits(可选):指定资源组中每个查询在被终止之前可能消耗的最大资源。这些限制不是从父组继承的。可以设置三种限制:
executionTimeLimit(可选):指定查询执行的最大时间的绝对值(例如1h)。
totalMemoryLimit(可选):为查询可能消耗的最大分布式内存指定一个绝对值(例如,1GB)。
cpuTimeLimit(可选):指定查询可能使用的最大CPU时间的绝对值(例如,1h)。
11、workerPerQueryLimit(可选):指定每个查询必须可用的最小节点数。如果用于弹性集群,其中节点数量会随着时间的推移而变化。一般不配置,和上面的最大CPU时间一样,有资源组其他配置就够了。
12、subGroups(可选):子组列表。资源组中的子组列表。每个子组可以有自己的属性集。
用户选择器的定义参数如下
1、group(必填):这些查询将运行的资源组组。
2、user(可选):与提交查询的用户相匹配,可以是一个正则表达式。
3、source(可选):这与查询的来源相匹配,这通常是提交查询的应用程序,一般不配置,使用user的场景占多数,也支持正则表达式的配置,如果你要使用它的话,通过。 jdbc和客户端携带对应的参数就行。
4、queryType(可选):与提交的查询类型匹配的字符串,一般也不配置,这个就是说根据执行操作的不同,用不同限制的资源,可以配置的值如下
SELECT:SELECT查询
EXPLAIN:EXPLAIN查询(非EXPLAIN ANALYZE)
DESCRIBE: DESCRIBE、DESCRIBE INPUT、DESCRIBE OUTPUT、SHOW
INSERT: INSERT、CREATE TABLE AS、 REFRESH MATERIALIZED VIEW
UPDATE:UPDATE查询
DELETE:DELETE查询
ANALYZE:ANALYZE查询
DATA_DEFINITION:更改/创建/删除模式/表/视图的元数据,并管理准备好的语句、特权、会话和事务的查询。
5、clientTags(可选):标签列表,每个tag必须在用户提交任务的tag列表里,这个一般也不用用的时候,你可以在网上查一下, jdbc使用jdbc:presto://presto-coordinator:8080/hive/default?clientTags=etl,high_priority,客户端提供了参数–client-tags
6、selectorResourceEstimate(可选):根据资源估计选择资源组。executionTime、peakMemory、cpuTime这三个作为依据
7、clientInfo(可选):与客户端信息匹配的字符串。
8、principal(可选):这是一个正则表达式,与提交查询的委托人相匹配,这个就是presto权限管理中配置的principal规则中的服务身份
9、schema(可选):这与查询的会话模式相匹配。
至于上面所看到的获取变量,比如USER这些是presto内置的一些动态变量可以用来获取经过认证后映射到的用户等,不过博主本人工作经历中没有遇到过直接这么用的,都是比较规范的多租户详细明细配置,而且就算你享用,提供的变量官网也没有说明文档,只能自己找社区,并且这种动态分配生成资源组会影响性能
要重点注意cpuQuotaPeriod,虽然它是一个可选配置,默认是1h,但是如果你另行配置了值,就必须同时配置hardCpuLimit。cpuQuotaPeriod决定了资源组可用cputime新配额的时间因子。当资源组cputime使用额度到达hardCpuLimit配置的上限时,该组在新的配额没有将已使用cputime对冲到hardCpuLimit以下的这段时间,则会发生上面配置说明中提到的新查询进入排队现象。
可以通俗的理解为,presto认为只要组使用的cputime触发到hardCpuLimit,就说明当前组可用的剩余cputime配额不够了,或者其他一些情况不能让该组其他的任务再跑了,和yarn的Reserved Resources有点异曲同工之妙,都是保障资源,不过yarn是为了能继续跑任务,presto是在重新生成足够的配额前,阻止新任务开始运行。
而CPU配额重新生成的多少取决于组的hardCpuLimit和cpuQuotaPeriod这两个值相除的结果。比如当cpuQuotaPeriod为100秒,而hardCpuLimit为500秒,则该组每秒重新生成5秒的cputime配额。Presto在内部使用“ usageMillis”跟踪配额。每次查询完成时,系统都会将任务用了多少cpuSeconds添加到该值,并且每过一秒钟便会根据相关组的配额策略通过减小该值来重新生成该值,达到对冲的目的。
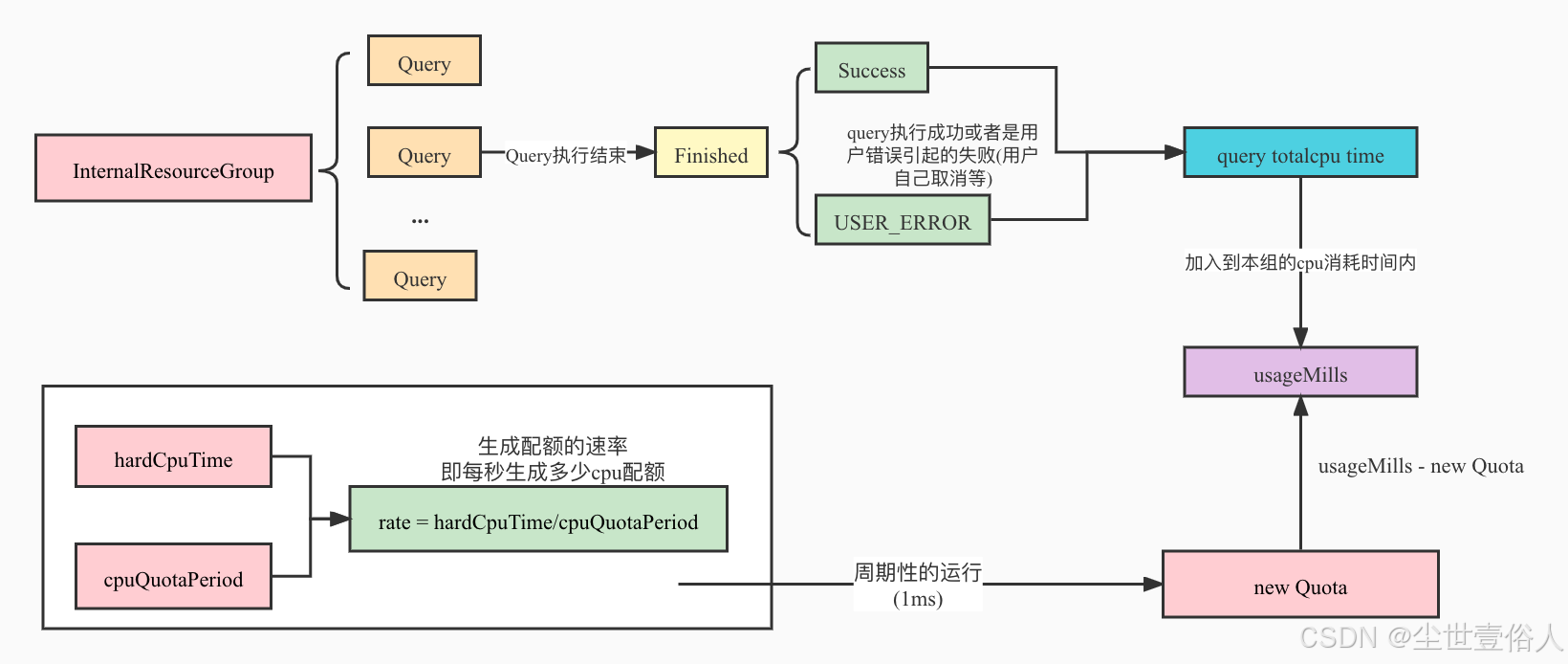
通过hardCpuTime 和 cpuQuotaPeriod配置不同资源队列占有cpu资源的比例,如果将cpuQuotaPeriod配置为1小时,而当前集群有10个核的计算资源,这相当于集群总共有10个CPU小时的执行时间可以用,将某资源队列组的hardCpuTime配置为5小时,则说明该组最多能占有50%的cpu资源(5/10),说白了cpuQuotaPeriod有点像yarn资源的最小因子,presto用它来限制cpu资源的使用,但是同样的,你或许也发现了presto它并没有像yarn一样硬性去限制整个集群的cpu有多少,如果你不设置,它将使用所有节点当前整个可用资源来跑任务,而如果你想设置,它也只是提供了上面说到的可选配置去限制整个集群CPU能够用到的最高峰
但是!!!!!!在商用的公有云场景下,cputime的限制是一定会配置的,虽然不同厂商的收费规格不同,但是在基于什么收费的原则上,普遍选择了CPU,一是因为presto有直接的cputime数据可用,二是因为内存会由于使用者的任务场景不同导致忽高忽低,因此公有云普遍是cputime和成本单价计算使用费用,当然也有的厂商是打包出售,也就是cpu和内存折中
此外另行提一嘴, Presto在多租户上支持像yarn一样,从物理上隔离资源,但并不是使用标签能力,而是在服务发现节点上会有一层resource管理器,搭建方式看官网就行
如果你只是基于使用,看到这里就可以了,下面要说一些执行原理,需要对代码阅读能力有一定要求

上图是presto存储资源对列信息的结构图,ManagerSpec为解析配置文件后对应的实体类,属性有rootGroups(根资源队列)、cpuQuotaPeriod(cpu配额时间段)和selectors(资源组选择器),ResourceGroupSpec为资源组对应的实体类,属性为资源组的参数,SelectorSpec为资源组选择器对应的实体类,属性为资源组选择器的参数
ManagerSpec的生成流程是从FileResourceGroupConfigurationManager类开始,它继承了AbstractResourceConfigurationManager,被@Inject注解表注,在presto启动时自动注入,源码如下
public class FileResourceGroupConfigurationManager extends AbstractResourceConfigurationManager
{
private static final JsonCodec<ManagerSpec> CODEC = new JsonCodecFactory(() -> new ObjectMapperProvider().get().enable(FAIL_ON_UNKNOWN_PROPERTIES)).jsonCodec(ManagerSpec.class);
private final List<ResourceGroupSpec> rootGroups;
private final List<ResourceGroupSelector> selectors;
private final Optional<Duration> cpuQuotaPeriod;
@Inject
public FileResourceGroupConfigurationManager(ClusterMemoryPoolManager memoryPoolManager, FileResourceGroupConfig config)
{
//传到AbstractResourceConfigurationManager类中的构造方法
super(memoryPoolManager);
requireNonNull(config, "config is null");
ManagerSpec managerSpec;
try {
//将资源队列配置文件解析成ManagerSpec对象
managerSpec = CODEC.fromJson(Files.readAllBytes(Paths.get(config.getConfigFile())));
}
catch (IOException e) {
throw new UncheckedIOException(e);
}
catch (IllegalArgumentException e) {
Throwable cause = e.getCause();
if (cause instanceof UnrecognizedPropertyException) {
UnrecognizedPropertyException ex = (UnrecognizedPropertyException) cause;
String message = format("Unknown property at line %s:%s: %s",
ex.getLocation().getLineNr(),
ex.getLocation().getColumnNr(),
ex.getPropertyName());
throw new IllegalArgumentException(message, e);
}
if (cause instanceof JsonMappingException) {
// remove the extra "through reference chain" message
if (cause.getCause() != null) {
cause = cause.getCause();
}
throw new IllegalArgumentException(cause.getMessage(), e);
}
throw e;
}
//从managerSpec中获取根资源队列
this.rootGroups = managerSpec.getRootGroups();
//从managerSpec中获取cpuQuotaPeriod
this.cpuQuotaPeriod = managerSpec.getCpuQuotaPeriod();
//确认根资源队列配置的参数无误
validateRootGroups(managerSpec);
//从managerSpec中获取selectors
this.selectors = buildSelectors(managerSpec);
}
}
检查根资源对列配置参数的方法源码如下,注意这里的根资源对列,指定就是配置文件中写的rootGroups部分
protected void validateRootGroups(ManagerSpec managerSpec)
{
//新建一个队列,从ManagerSpec managerSpec 的getRootGroups()方法中获取根资源队列 即 List<ResourceGroupSpec>对象
Queue<ResourceGroupSpec> groups = new LinkedList<>(managerSpec.getRootGroups());
while (!groups.isEmpty()) {
//取队列第一个元素
ResourceGroupSpec group = groups.poll();
//获取该资源队列的子资源队列,并加到队列groups中
List<ResourceGroupSpec> subGroups = group.getSubGroups();
groups.addAll(subGroups);
//softCpuLimit或者hardCpuLimit存在一个则需要检查cpuQuotaPeriod是否存在,不存在则报错
if (group.getSoftCpuLimit().isPresent()  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









