



翻译原文地址:https://www.thinkautonomous.ai/blog/faster-rcnn/
2018年的一天,我正在购买我的第一辆车——一辆奥迪A1,销售代表向我推荐了“Sportback”版本,据说动力更强。 “为什么?”我问道。结果发现,它比经典版本拥有更多的马力。马力?这个概念让我感到好奇,尤其是自从人们用汽车取代马匹已经过去了一个世纪,但我们仍然使用马力作为描述汽车的关键指标。
这个指标虽然看似过时,但仍然是汽车行业的黄金标准……这让我想起了目标检测中的Faster R-CNN算法。
Faster R-CNN算法于2015年引入AI社区,尽管已经过去了10多年,你仍然可以在大多数新的目标检测论文中看到它被列为基准。不知何故,Faster R-CNN仍然是研究人员在创建新算法时使用的参考。
例如,CO-DETR这篇论文使用了混合Transformer进行目标检测,这是一项非常先进的技术,发布于2023年底(几乎是Faster R-CNN发布10年后),而它对比的论文列表中仍然包括Faster R-CNN。
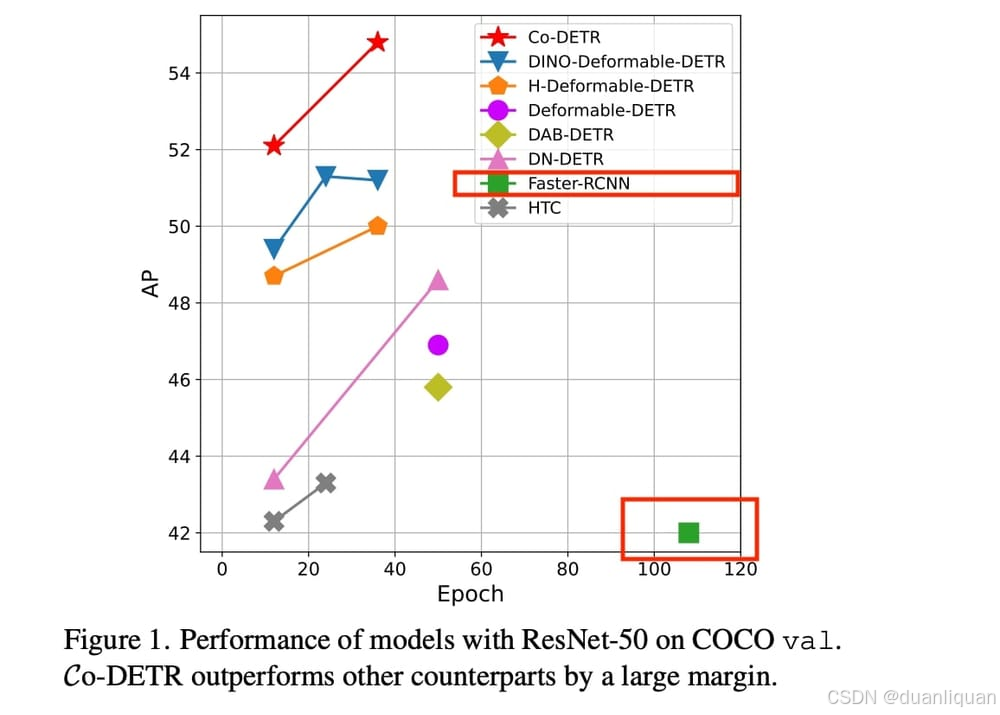
你注意到了吗?几乎每篇论文都是如此!
为什么? 当这个算法首次发布时,大约在2018年,我正在寻找一个目标检测模型集成到我的自动驾驶班车(shuttle)中,当时整个市场似乎得出了三个结论:
- SSD (Single Shot Detector) 是最快的目标检测网络
- Faster R-CNN 是精度最高的模型,尤其是对于小物体
- YOLO (You Only Look Once) 是精度和速度之间的最佳折衷方案
然而,最初的YOLOv3已经被多次取代,而Faster RCNN模型仍然屹立不倒。在这篇文章中,我想向你描述这个模型,解释其关键组件,并帮助你理解是否值得花时间研究它。
在我们深入探讨这个算法之前,先简单提一下:
当我第一次学习目标检测时,是通过Udacity的自动驾驶汽车纳米学位课程,我们学习了一种名为“HOG+SVM”的机器学习技术,它的工作原理如下:

传统的“HOG+SVM”目标检测,图像被发送到一个运行滑动窗口的算法中,对于每个窗口,提取方向梯度直方图(Histogram of Oriented Gradient,HOG)特征,并使用支持向量机(Support Vector Machine,SVM)进行分类。虽然这种方法很老,完全是“传统”的,但确实有效。它并没有赢得目标检测的奥斯卡奖,但它确实有效。这个想法就是我们所说的两阶段目标检测器:
- 我们提出区域或边界框(在这种情况下,我们定义了窗口尺寸)
- 我们对每个区域进行分类
以下是输出结果:

Faster R-CNN算法正是基于相同的“两阶段”原则构建的,只不过它用神经网络取代了所有这些技术。
让我们来看看:
R-CNN:选择性搜索
第一个想法是用CNN(卷积神经网络)取代使用方向梯度直方图进行的特征提取。以下是它的工作原理:
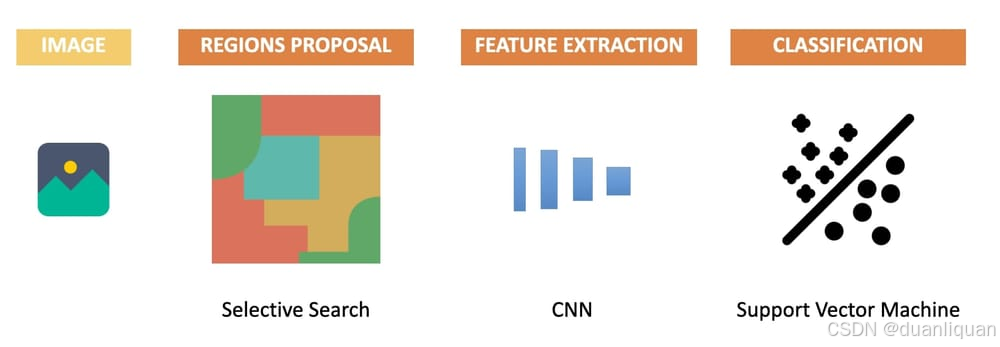
该算法有几个步骤:
- 使用选择性搜索算法提出2000多个先验框
- 对于每个区域,使用CNN提取特征
- 对于每个区域,使用SVM对特征进行分类
这个想法与我的项目几乎相似,只不过区域提议网络是使用选择性搜索(一种老旧的计算机视觉算法)完成的,而提取是使用CNN完成的。

该算法有几个问题: 太多无用的区域,需要提取的特征太多,而且每个区域都必须手动调整大小/变形以匹配CNN的输入层。
这并不理想……
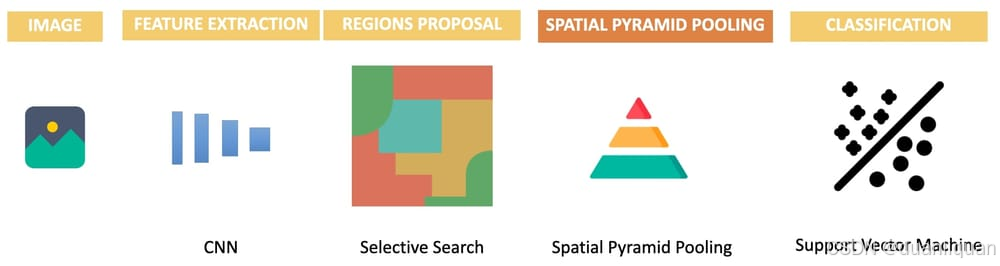
SPP-Net:添加空间金字塔池化(SPP)块
SPP-Net是这篇论文的进化版本,使用了一种称为空间金字塔池化 (Spatial Pyramid Pooling) 的巧妙技术。其想法如下:
- 首先使用CNN提取特征
- 使用选择性搜索提出2000多个特征图区域
- 使用空间金字塔池化来避免裁剪/变形区域
- 将每个特征图发送到全连接层,并使用SVM进行分类
来自我的课程:MASTER OBSTACLE TRACING
这个想法奏效了!在特征上工作而不是在区域上工作有助于去除一些噪声,而引入空间金字塔池化有助于通过多个“最大池化”操作从不同的纵横比查看图像。
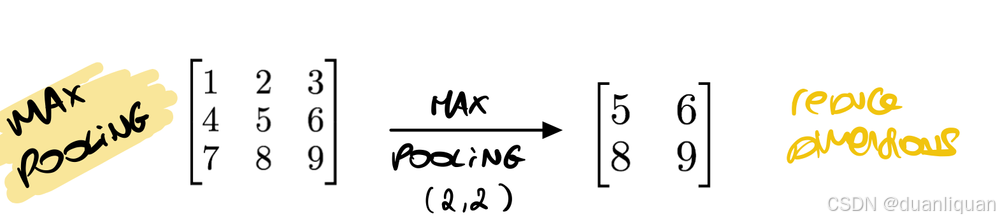
让我简要回顾一下最大池化的概念: 它采用一个窗口(比如2x2)并计算最大值以减小输入的大小,因此500x500的图像变为250x250。
空间金字塔池化做的是类似的事情,但在多个不同的尺度上,比如(1x1)、(2x2)、(3x3)等:
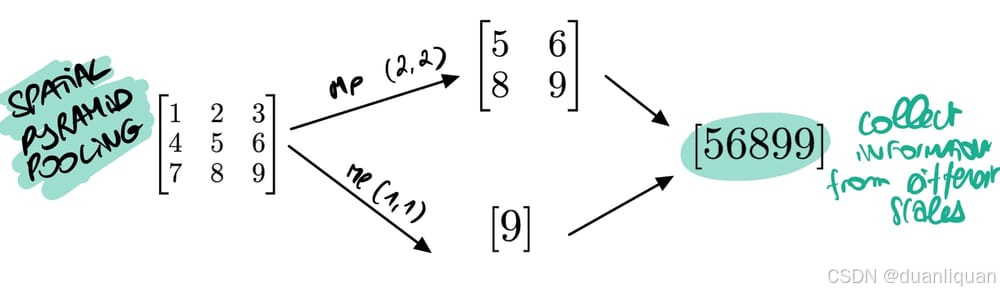
来自我的课程:MASTER OBSTACLE TRACING
其想法是:从不同尺度收集信息。
到目前为止,我们用CNN取代了特征提取,并添加了SPP。接下来呢?
Fast R-CNN:添加神经网络分类和ROI池化
接下来是Fast R-CNN检测器!其想法几乎相同,只不过它用ROI (Region of interest) 池化取代了空间金字塔池化,并用多层感知器分类器取代了最终的SVM:
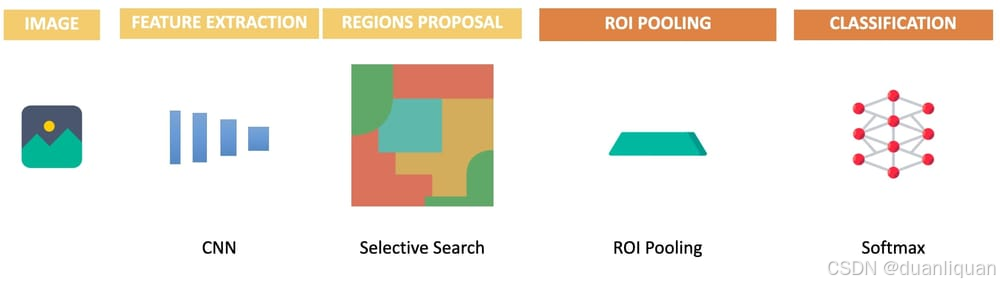
注意关键步骤:
- 使用CNN提取特征
- 使用选择性搜索提出2000多个区域
- 使用ROI池化来避免裁剪/变形区域
- 将其发送到全连接层,并使用神经网络进行分类
Fast R-CNN架构有两个核心思想:ROI池化和全连接分类。
1. ROI池化:更好的SPP
ROI池化是空间金字塔池化的一种特殊情况,增加了一个专注于特定区域的想法。
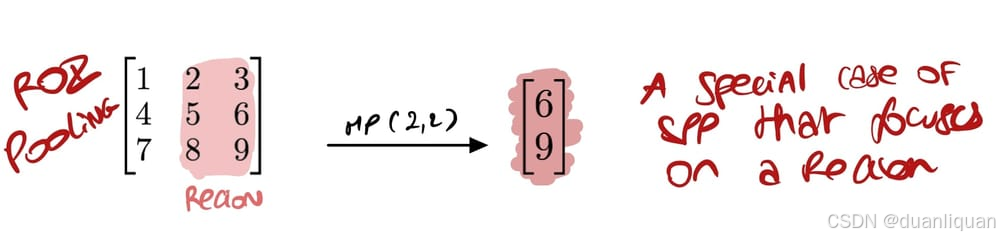
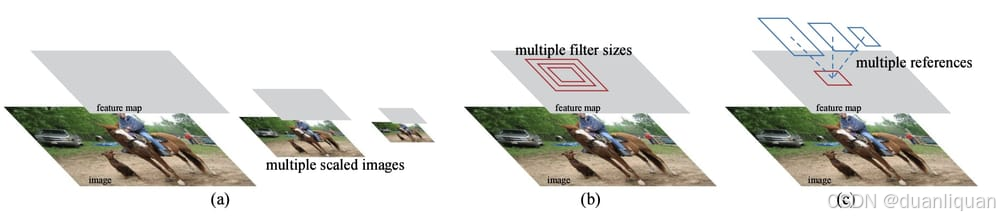
这在两阶段目标检测算法中特别有用,这些算法首先使用选择性搜索 (Selective Search) 或Faster R-CNN中的区域提议网络(Region Proposal Networks) 所提出的区域。与SPP相比,这种技术非常快,因为SPP需要在不同尺度上多次计算池化(它还直接为所有区域计算池化)。
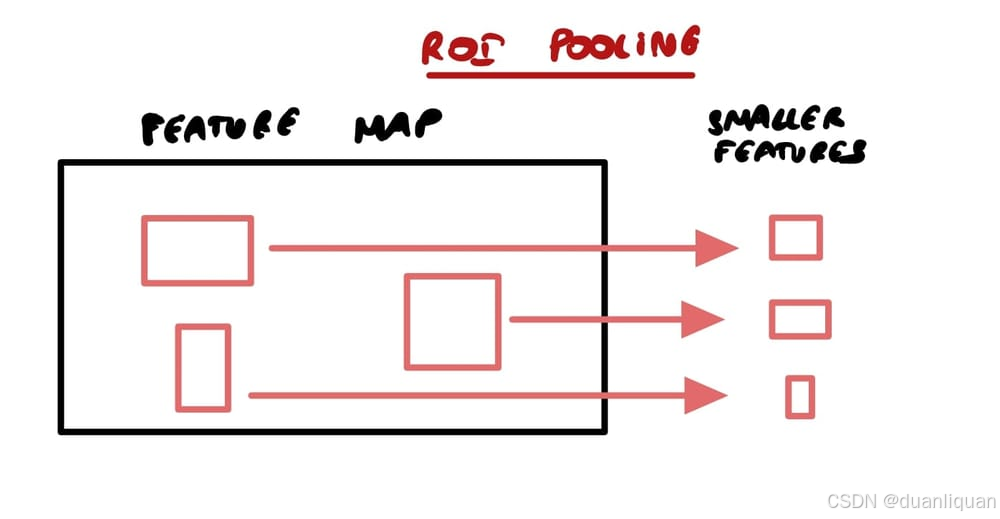
你可以注意到,这种技术通过在不同尺度上工作,使网络更加准确,尤其是对于不同大小的物体。 许多目标检测模型使用锚框技术来找到边界框。问题是,你必须每次都手动定义锚框。在这个过程中,我们首先找到区域(而不是一些框),然后提取这些区域的信息。
我们也可以在Faster R-CNN论文中看到这一点(它使用了相同的技术):
2. 全连接分类器:更好的SVM
第二个改进是用Softmax层取代了传统的机器学习SVM(支持向量机,Support Vector Machine)。这里没有太多需要评论的地方——我们在k个区域提议上使用softmax来对每个边界框进行目标分类。这个想法在Fast R-CNN中使用,也在Faster R-CNN中使用。
说到这一点,从Fast R-CNN到Faster R-CNN还有最后一个进化:
Faster R-CNN:用区域提议网络(RPN)取代选择性搜索
当我们在2013年开始这个算法时,几乎所有的工作都是由传统技术完成的:
- 我们使用选择性搜索提出区域(老式的计算机视觉/分割)
- 我们使用CNN进行特征提取(这是深度学习)
- 我们使用SVM对特征进行分类(传统的机器学习分类)
逐渐地,我们用全连接层取代了SVM,并通过金字塔改进了CNN提取。剩下的就是用深度学习取代选择性搜索算法!是的,这确实是一种老旧的、缓慢的计算机视觉技术:
Faster R-CNN用基于深度学习的区域提议网络(Region proposal Network,RPN)取代了选择性搜索。这样,所有内容都可以使用统一的网络进行端到端训练。它是一个单一的网络!
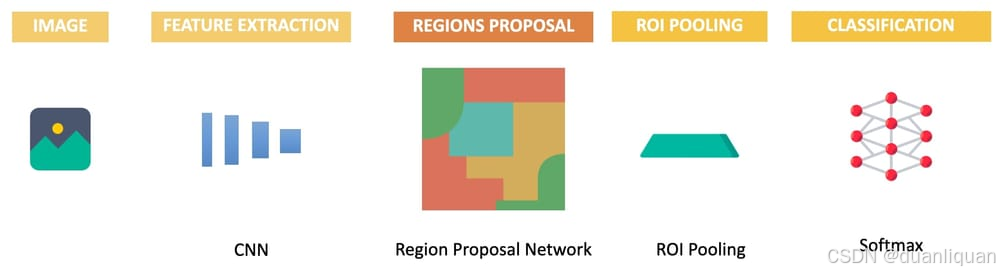
整个过程如下:
- 使用CNN提取特征
- 使用区域提议网络 (Region proposal Network) 生成区域
- 使用ROI池化来避免裁剪/变形区域
- 将其发送到全连接层,并使用神经网络进行分类
这就是Faster R-CNN!
那么,这个RPN在做什么呢?它充当网络的“注意力”。它旨在生成高质量的先验框,并突出显示可能存在物体的地方。它以任意大小的图像作为输入,使用全卷积网络输出一组矩形边界框,每个框都有一个物体得分。当你想到这一点时,Faster RCNN论文的标题是“Towards Real-Time Object detection with Region Proposal Networks”。
区域提议网络如何使其实现实时性? 通过移除选择性搜索算法并直接在特征图上工作,它消除了大量计算的需求,并实现了零成本的区域提取。RPN在骨干CNN(例如ResNet或VGG)生成的相同卷积特征图上操作,这些特征图已经为目标检测计算完毕。
然后,它使用“锚框”的概念来生成区域。如果你不熟悉锚框的概念,其想法是定义多个纵横比和大小的框,并尝试让物体适应这些框。例如,一个垂直的小锚框是一个远处的行人——一个垂直的大锚框是一个靠近摄像头的行人。
我强烈推荐我的文章《Finally Understand Anchor Boxes in Object Detection》来理解这个概念。
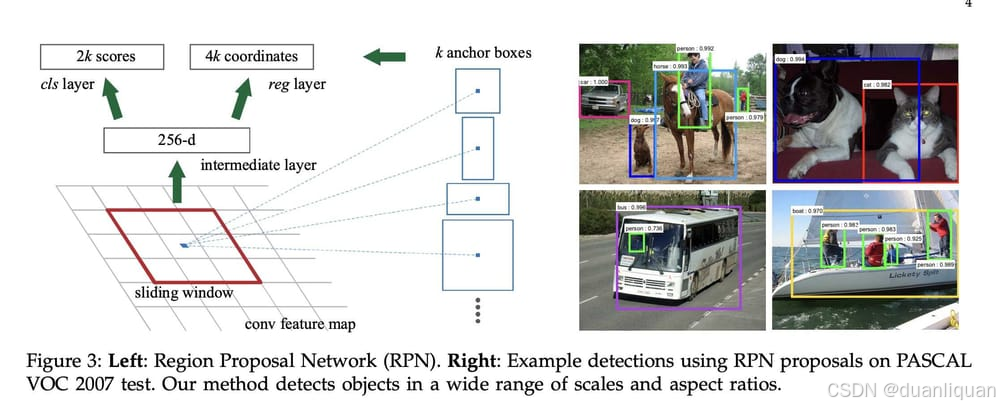
使用Fast R-CNN中的FCN和这个新的RPN,算法可以同时预测物体边界和类别概率。
就是这样!Faster R-CNN论文《Towards Real-Time Object Detection with Region Proposal Networks》非常高效,因为它使用了所有这些想法。作为一个两阶段算法,它功能强大,可以找到小物体和大物体。它有点慢,但对区域提议网络的改进使其更加出色。
现在让我们看一个例子:
Faster R-CNN还在使用吗?它最适合哪些场景?
我不认为今天的人们会将Faster R-CNN作为他们算法的主要选择。现在有许多更强大、更好、更快的目标检测器。然而,如果有一个地方我会使用它,那就是交通灯检测和分类任务。
你经常看到这一点;交通灯有一个专门为它们设计的独立网络。这些网络通常专注于找到较小的物体,检测状态,并使用专注于灯光的远距离摄像头。
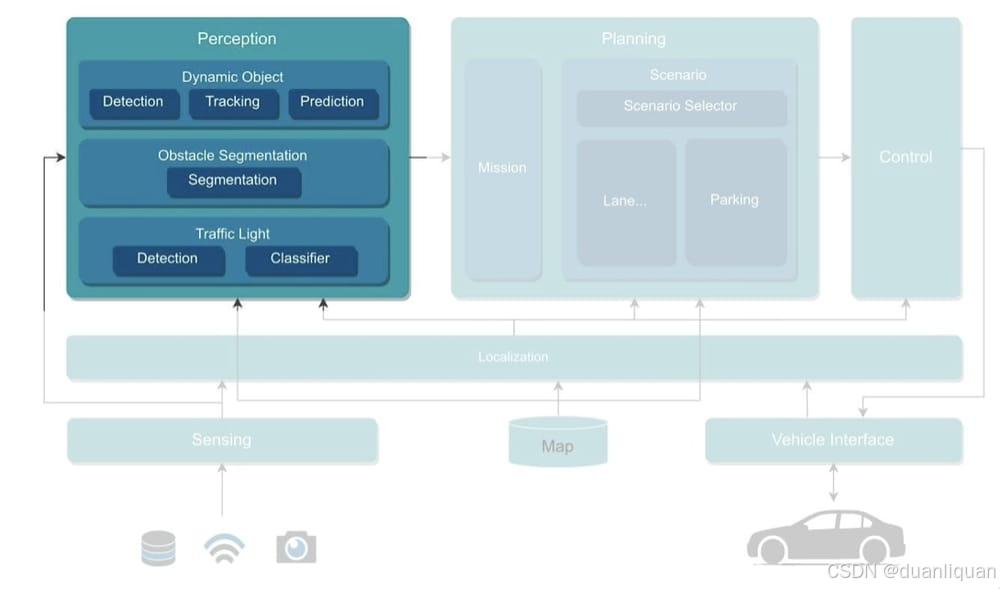
Autoware自动驾驶汽车架构——在这里,Faster RCNN将适用于交通灯检测和分类模块
在这里,你可能会发现Faster R-CNN被使用。可能比其他任何地方都多,因为这个算法准确且在处理小物体时表现良好。
我应该尝试自己重新编写它吗?
如果你从未实现过目标检测,我建议你先学习HOG+SVM传统技术。然后,你可以尝试先运行Faster R-CNN,然后可能实现一些模块。如今,YOLO更为主流,理解这个算法也很有意义。
需要理解的是,目标检测的真正价值不一定是找到物体,而是将其扩展到LiDAR/相机融合或物体跟踪等领域。这才是目标检测器的真正价值所在。
总结与下一步
你已经读完了这篇文章!恭喜!让我们快速总结一下我们学到的一切。首先,你现在可能理解了这张图:
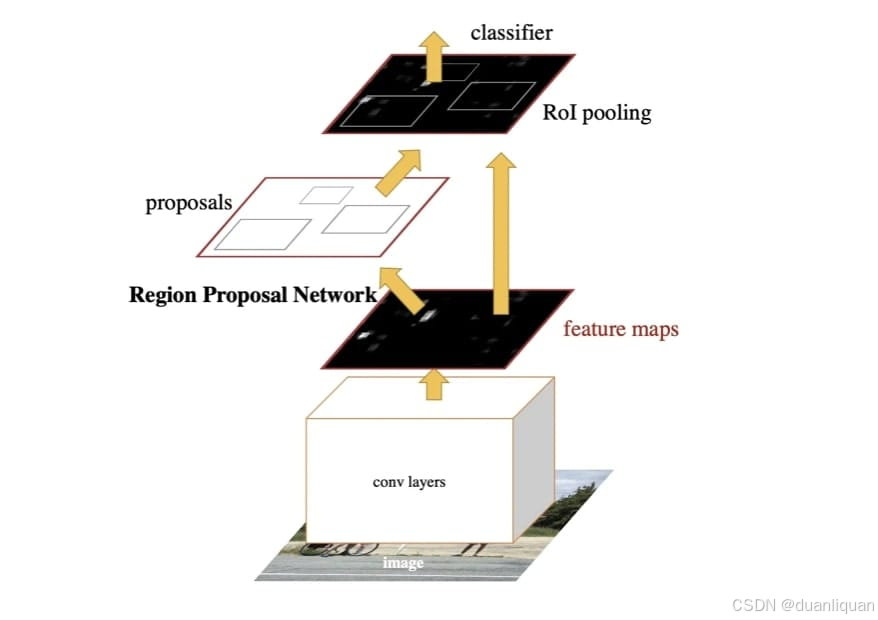
以下是它的内容:
-
Faster R-CNN仍然是目标检测的基准,即使在其引入十年后。该算法以其准确性著称,尤其是对于小物体,并且经常与YOLO和SSD等新模型进行比较。
-
Faster R-CNN从传统技术演变而来,用神经网络取代了每一种技术;从区域提取到特征提取和分类。
-
HOG特征提取在Fast R-CNN中被CNN取代,从而能够构建特征图。
-
空间金字塔池化,以及后来的ROI池化和锚框被添加,以实现更好的提取、提议和理解。
-
区域提议网络(RPN)取代了选择性搜索,使模型能够实时生成高质量的先验框。
-
全连接层取代了SVM进行分类。
-
尽管比一些现代检测器慢,但Faster R-CNN在需要高精度的任务中表现出色,例如交通灯检测。
-
该模型的两阶段过程包括提取区域并对它们进行分类,使其在检测各种大小的物体时非常强大。
下一步
以下是我推荐你接下来学习的几篇文章,以继续你的旅程:
《Finally Understand Anchor Boxes in Object Detection (2D and 3D)》
《Computer Vision for Multi-Object Tracking: Live Example》
《Instance Segmentation: How adding Masks improves Object Detection》
当然,最重要的推荐是:继续深入学习目标检测和相关技术,探索更多实际应用场景!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









