




 本文介绍了awk命令的工作原理,强调其能按字段处理文本的能力,区别于sed。讲解了awk的常用操作,包括按行输出、按字段输出、使用管道和双引号调用Shell命令,以及awk中的数组运用。此外,还提供了awk小实验,涉及数组统计和日志分析等实战案例。
本文介绍了awk命令的工作原理,强调其能按字段处理文本的能力,区别于sed。讲解了awk的常用操作,包括按行输出、按字段输出、使用管道和双引号调用Shell命令,以及awk中的数组运用。此外,还提供了awk小实验,涉及数组统计和日志分析等实战案例。
前言
sed 常用于对整行读取后进行处理;
awk 不仅能逐行处理,也能通过分隔符 获取具体每一列的值;
一、awk 介绍
awk 工作原理:
-
逐行读取文本,默认以 空格 或 tab键 为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
-
sed 命令常用于一整行的处理,而 awk 是将一行根据分隔符分成多个 “字段” 后再进行处理。
-
awk 信息的读入也是逐行读取的,执行结果可以通过
print的功能将字段数据打印显示。
在使用 awk 命令的过程中,可以使用逻辑操作符:
- “&&” 表示 “与”
- “lI” 表示"或"
- “!” 表示 “非”
还可以进行简单的数学运算:
+加-减*乘/除%取余^乘方
命令格式:
awk 选项 '模式或条件 [操作]' 文件1 文件2 ...
awk -f 脚本文件 文件1 文件2 ...
#通过脚本文件多个命令,达到批量操作的目的
awk 常见的内建变量:
FS:列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与选项"-F"作用相同
NF:当前处理的行的字段个数。
NR:当前处理的行的行号(序数)。
$0:当前处理的行的整行内容。
$n:当前处理行的第n个字段(第n列)。
FILENAME:被处理的文件名。
RS:行分隔符。
awk 从文件上读取资料时,将根据RS的定义把资料切割成许多条记录;
而awk一次仅读入一条记录进行处理。默认值是'\n'
awk 是 linux 下的一个命令,他对其他命令的输出,对文件的处理都十分强大,其实他更像一门编程语言,他可以自定义变量,有条件语句,有循环,有数组,有正则,有函数等。
他读取/输出文件的方式是一行一行的读,根据你给出的条件进行查找,并在找出来的行中进行操作,感觉他的设计思想,真的很简单,但是结合实际情况,具体操作起来就没有那么简单了。
有三种形势,awk,gawk,nawk,平时所说的awk其实就是gawk。
二、awk 操作
- print 一定要写在 {} 中 ,即
'{print}',而且外面是单引号,双引号不起作用。 {print}一般放在表达式的最后面- BEGIN 表示开始执行的语句
- END 是当 BEGIN 的语句执行结束后才会执行后面的语句
- ~ 表示包含的意思,如:$1~'abc",表示 第一列包含 字符串 abc
2.1 按行输出文本
#输出文件所有内容,默认输出所有列($0)
awk '{print}' awkfile.txt
awk '{print $0}' awkfile.txt #$0 表示输出整行内容
#输出文件第2列($2)的内容
awk '{print $2}' awkfile.txt
#输出有7列的行
awk 'NF==7 {print}' /etc/passwd
#输出大于等于第一行,小于等于第三行的内容
awk '(NR>=1)&&(NR<=3) {print}' awkfile.txt

我将第一行one 改成了 one first
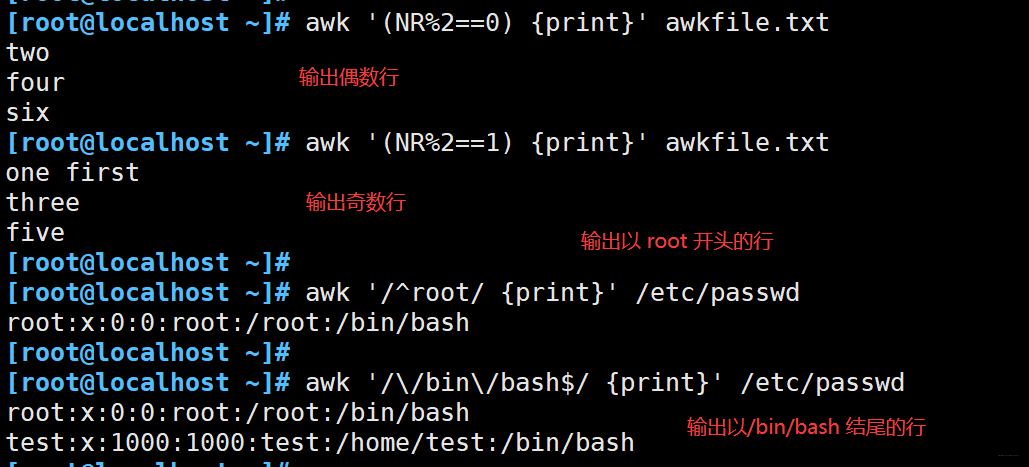
awk '(NR%2==0) {print}' awkfile.txt
awk '/\/bin\/bash$/ {print}' /etc/passwd
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;
awk 在处理指定的文本之后,才回去执行END模式中指定的动作;
END{
}语句块中 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









