




1、性能测试简介
性能测试就是被测系统,在一定的负载在运行,监控系统的各项指标,是否符合需求(响应时间,tps,内存cpu等),如果不符合,说明存在瓶颈。
目的:识别系统的弱点,评估系统的能力,发现系统的瓶颈,提高系统可靠性能和稳定性。
一些概念:每秒事务数:每秒系统处理事务(失败/通过/停止)的数量; 响应时间:从发送一个请求开始计时到接收到从服务器端返回的相应结束的耗时
并发用户数:线程数
系统负载:系统支持的最大并发用户数
吞吐率:系统每秒处理的流量,单位:Kb、Mb
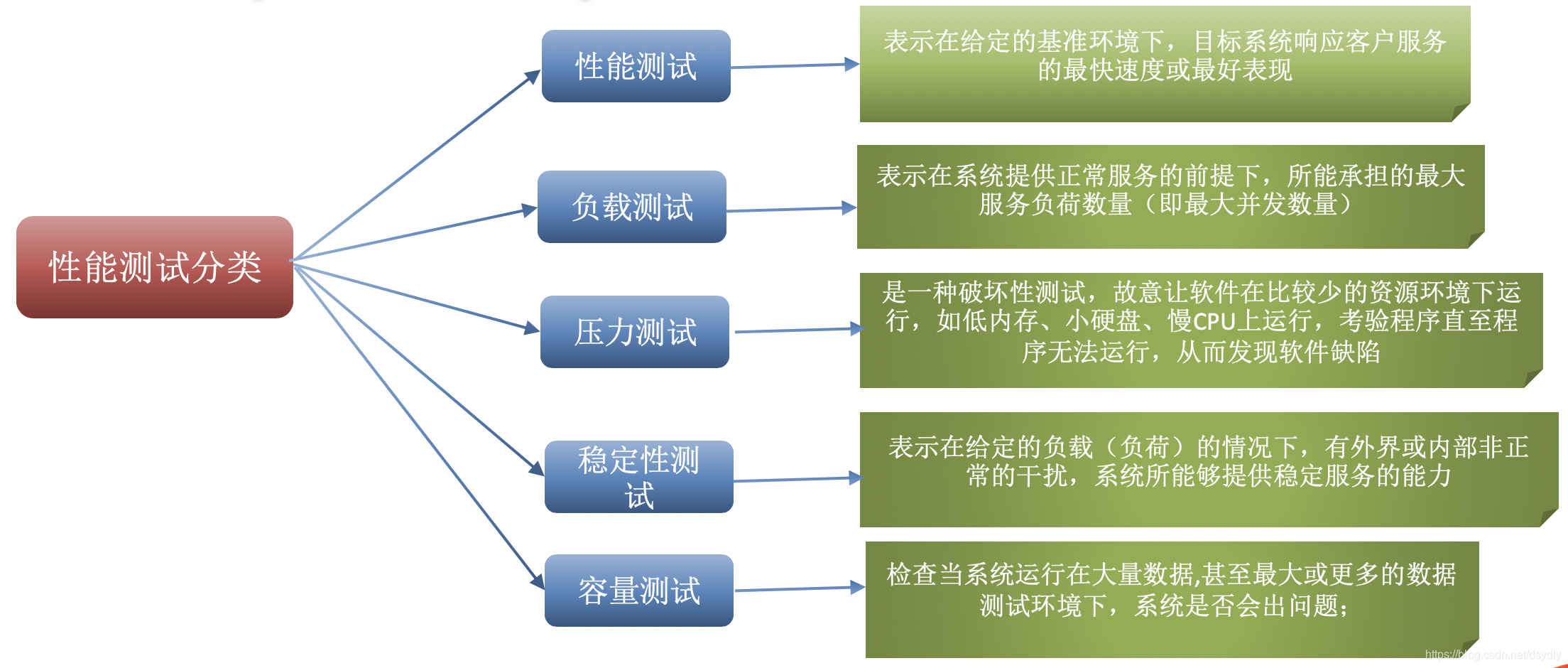
2、性能测试的分类:
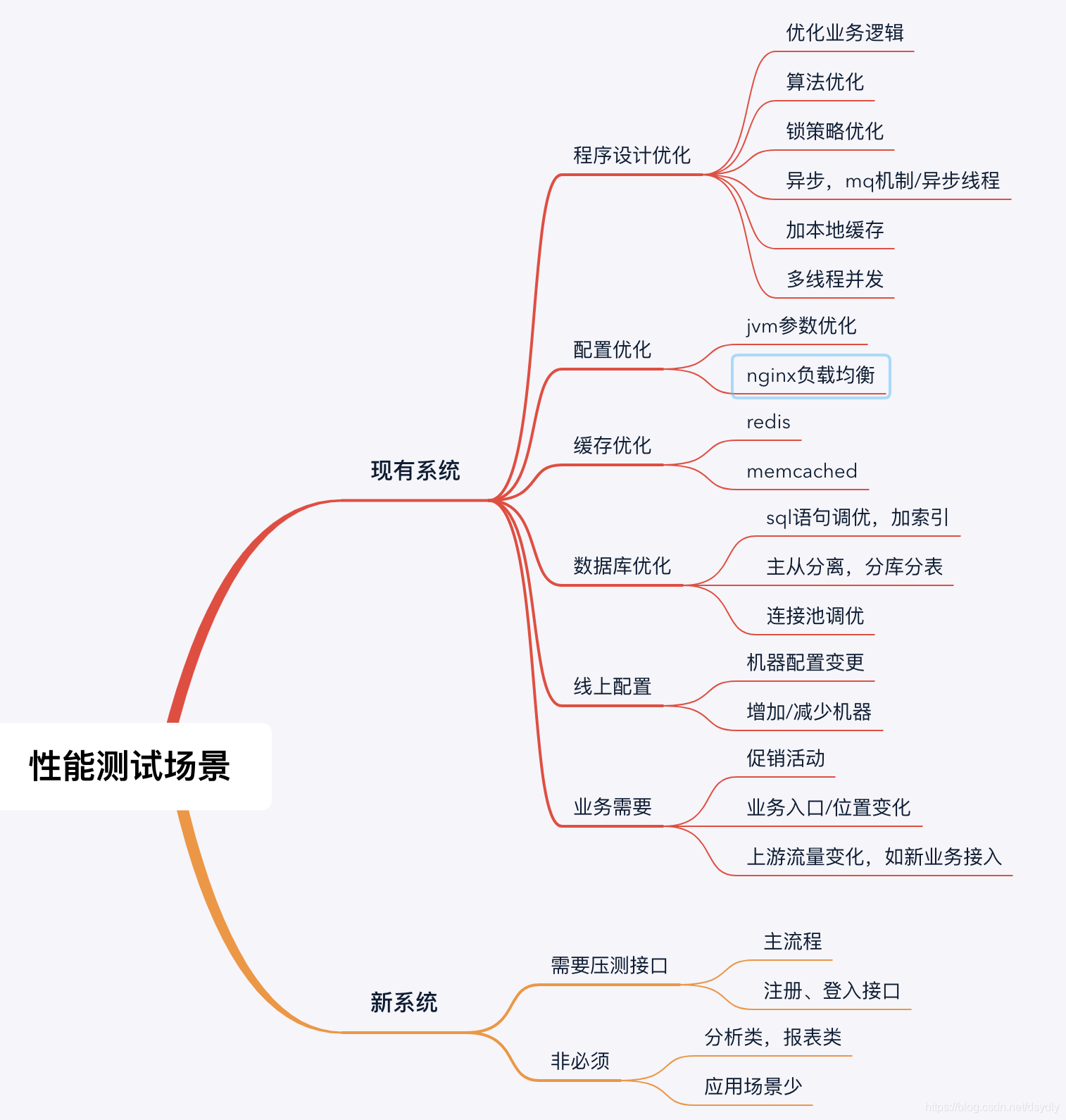
3、什么场景需要性能测试:
4、性能测试流程
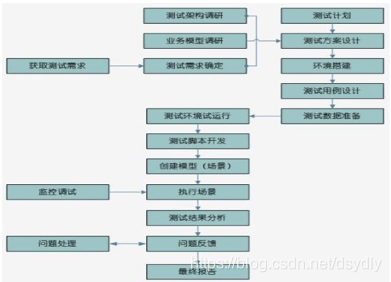
系统架构和业务逻辑调研——测试计划、测试数据准备——测试环境准备(线下OR线上)——测试结果报告分析——修改调优——再次压测
5、压测计划
被测系统定义:系统介绍,为何执行压测,针对哪些系统压测等
性能测试指标:系统的负载能力,响应时间,吞吐率,稳定性等
环境信息:服务器CPU,内存等硬件信息,数据库,缓存情况统计
压测信息:人力成本,压测策略,压测时间,影响服务
6、压测方案
|
模块 |
解释 |
说明 |
|
压测目标 |
Tps,响应时间(平均响应时间,90%响应时间等) |
1. 通过历史信息分析 |
|
链路分析 |
分析请求链路以及响应时间 |
1. 清晰压测边界 |
|
场景分析 |
根据实际业务场景进行压测策略的指定 |
单场景,混合场景,压力策略 |
|
数据分析 |
通过请求,响应数据分析,制定有效的压测数据 |
1.请求的类型,比例
2.下游返回结果的有效率
3.缓存数据是否要做预热,量是多少
|
|
监控报警 |
线上全面监控和报警,保证线上压测的有效措施 |
1.报警指标梳理和确认
2.服务器指标,jvm参数指标监控
3.错误率,异常信息等监控
|
|
压测分析 |
针对压测结果,做梳理分析,并指定 |
1.报警异常产生原因
2.系统瓶颈在哪儿
3.如何改进以及完成时间点,后续压测计划
|
7、线上针对高TPS的方案
|
概念 |
触发原因 |
触发场景 |
处理方案 |
|
熔断 |
某个下游服务不可用 |
当失败的调用到一定阈值,如缺省是5秒内20次调用失败,就会启动熔断机制 |
中断下游服务调用,但是每隔一段时间发请求检查,如果恢复则取消熔断 |
|
降级 |
系统整体响应慢或某个非核心服务响应慢 |
访问量剧增、服务响应慢或非核心服务影响到核心流程的性能 |
进行自动降级或者通过配置实现人工干预
|
|
限流 |
上游流量突增,影响系统线上稳定性 |
流量触发限流设置 |
执行限流,拒绝访问或返回兜底数据 |
8、压测的瓶颈分析
|
瓶颈现象 |
问题方向 |
优化方向 |
|
TPS波动较大 |
一般有网络波动、其他服务资源竞争以及垃圾回收问题 |
1.网络波动问题,可以让运维同事协助解决
2.资源竞争问题:通过命令监控和服务梳理,找出压测时正在运行的其他服务,沟通协调停止
3.垃圾回收问题:通过GC文件分析,如果发现有频繁的FGC,调整JVM的堆内存参数
|
|
高并发下大量报错 |
常见的原因有短连接导致的端口被完全占用以及线程池最大线程数配置较小及超时时间较短导致 |
1.短连接问题:释放TIME_WAIT scoket,提高客户端的链接超时限制,增大端口范围等
2.线程池问题:修改服务节点配置文件中的最大线程数,超时时间等
|
|
负载不均衡 |
可能Ningx或dsf等中间平台分配策有问题 |
调整nginx/dsf 等中间平台分发策略 |
|
线程数不断增加,TPS上不去,CPU使用率低 |
常见的原因有:SQL没有创建索引/SQL语句待优化,高并发时出现锁等待 |
1.建索引,优化sql,库的读写分离设计
2.锁机制优化: 必要不加锁;减少跟锁无关的操作,降低时间间隔;读写锁分离等
|
|
线程数上不去,响应时间很快,服务器资源充足 |
或为压测资源不足 |
1. 检查压测机的资源占用 |
|
前端优化 |
一般前端性能不会通过并发压测的 |
1.前端优化以减少请求次数
2.前端减少请求数据的大小,比如有些图片做压缩处理。
|

















 1970
1970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









