



使用源码阅读工具:vscode、vim
opentenbase学习文档:快速入门 - OpenTenBase Documentation
opentenbase学习资料:开放原子开源基金会学习考试平台 - 开源人才培养和认定。在该平台上有很多免费的学习资源,并且通过学习和测试后可以获取对应的认证证书。其中opentenbase入门课程可以帮助我们快速对opentenbase这个项目有一个初步的了解和认识,掌握编译运行的方法和一些基本操作。通过OFCA-OpenTenBase认证考试,就可以获得初级人才认证证书,该考试有3次作答机会,每次考试时间为1小时,考核内容包括数据库基础知识和opentenbase架构原理、安装部署、应用开发基础知识等。
1.OpenTenBase项目整体概览:
背景:OpenTenBase的出现是为了填补业内基于PostgreSQL的开源分布式OLTP系统的技术空白,为企业数字化转型提供强有力的支撑。OpenTenBase是腾讯云分布式数据库TDSQL PG的开源社区版,并在2023年的开放原子开发者大会上被捐赠给开放原子基金会。其在PostgreSQL基础上,集高扩展性、高SQL兼容度、分布式事务一致性、多级容灾能力以及多维度资源隔离能力于一身,是企业级分布式HTAP开源数据库,已成功应用在金融、政府、电信、医疗等行业的核心业务系统中。
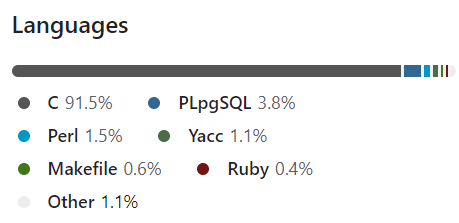
使用的语言:主要使用的C语言实现,包含少部分的PLpgSQL和其他语言
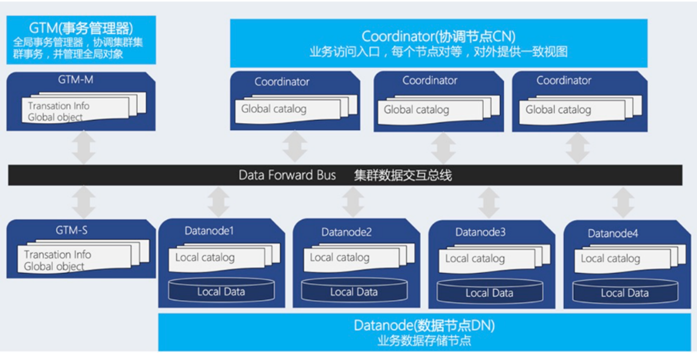
整体架构:
如下图所示,OpenTenBase采用的是无共享的分布式集群架构,节点之间相互独立,各处理单元之间通过网络协议进行通信。整个架构主要由三大部分组成,分别是GTM全局事务管理节点,CN(coordinator)协调节点和DN(datanode)数据节点。其中GTM节点负责管理集群事务信息,同时管理集群的全局对象;CN节点是业务入口节点,多CN节点之间是相互平等的,在执行业务时,CN节点负责对要执行的SQL语句进行分析并生成执行计划,将SQL语句下推给数据节点,CN节点中不存储业务数据,存储的是全局元数据视图和分组信息;DN节点是真正存储业务数据的节点,其执行CN节点推送的SQL语句和执行计划。
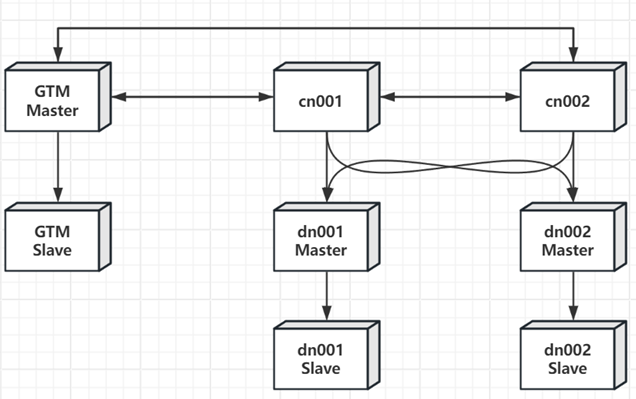
具备容灾能力的最小集群部署如下图所示,包含两台主机,分别作为GTM-M和GTM-S。并且将CN节点和DN节点混合部署在这两台主机上。注意对于同一个DN节点,例如dn001,其主节点和备节点不可以部署在同一台主机上。即dn-Master的顺序为(IP_1,IP_2),那么dn-Slave的顺序就应该为(IP_2,IP_1)。
代码结构:
如下图所示,是OpenTenBase项目下一级目录的结构,包含源码实现目录和多种说明性文件,如项目许可证、版权声明、项目指南、贡献指南、项目历史变更记录、版本发布说明等。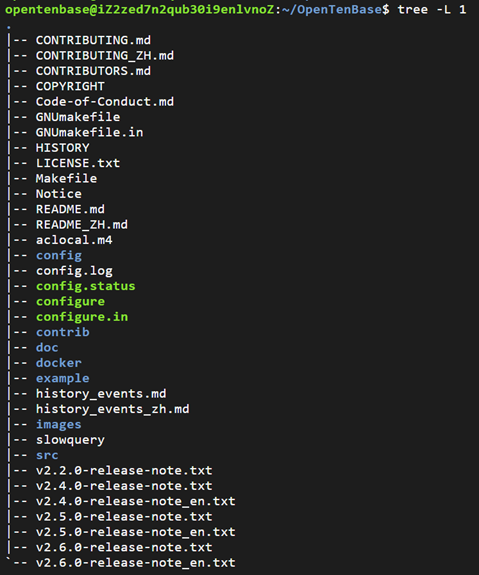
在源码实现目录中,src目录包含OpenTenBse项目实现的核心源代码;contirb目录负责拓展模块;doc目录下包含各种支持文档;docker目录包含容器化部署配置和脚本;config目录存储配置信息;example目录中存储示例代码,即数据库使用场景的示例配置或脚本;images目录下是相关图片资源。
对包含在src核心源码实现目录下的源代码进行分析,根据src目录下一级目录和文件结构,可以整理出如下表格:
| 目录/文件 | 作用 |
| backend | 数据库核心引擎实现,包含查询解析、优化、执行等核心模块 |
| bin | 可执行文件目录,用于数据库初始化和管理 |
| common | 多模块共享的公共工具库 |
| fe_utils | 前端工具 |
| gtm | 全局事务管理器实现,负责分布式事务的全局协调 |
| include | 存储定义数据结构、函数接口等被其他模块引用的头文件 |
| interfaces | 客户端接口库 |
| makefiles | 编译配置文件目录 |
| pl | 过程语言扩展,支持PL/pgSQL,PL/Python等脚本语言 |
| port | 实现平台兼容性,处理不同操作系统的适配 |
| template | 模板文件目录 |
| test | 测试代码,包含单元测试、集成测试的脚本和用例 |
| timezone | 存储和解析时区信息的模块 |
| tools | 辅助工具目录 |
| tutorial | 示例代码目录 |
其中最重要的可以分为以下三个部分:首先是backend和gtm目录,是数据库引擎的核心实现;其次是interfaces和fe_utils目录,包含客户端实现和接口代码;最后是makefiles和test目录,进行构建和测试系统。
项目特点:
商业数据库兼容性:完整兼容SQL2011,支持Oracle语法
PostgreSQL兼容性:高度兼容PostgreSQL语法和生态跟进社区
分布式事务能力:完整的分布式事务ACID能力,保证分布式读一致性
HTAP双引擎:具备高效OLTP和强大OLAP双引擎能力,支持PB级海量数据高效处理高效分布式执行能力
灵活扩展且性能优越:支持灵活扩展,分布式高效弹性扩缩容,支持高并发和高速吞吐
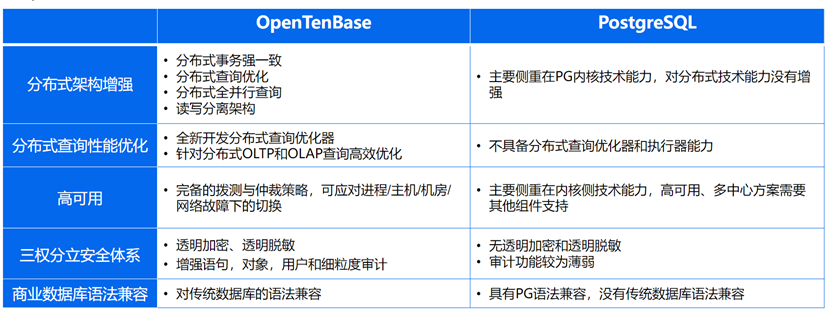
和PostgreSQL相比,OpenTenBase具有更强的分布式架构和安全体系:
2.SQL解析器的源码实现分析
2.1 了解模块功能:
首先根据目录/src/backend/parser/下的README文件,我们可以了解到OpenTenBase数据库SQL解析器的整体结构和各个模块的功能,包括将SQL查询进行分词、解析、以及为优化器和执行器生成复杂查询的Query结构。
parser.c文件是解析SQL查询的入口,驱动整个SQL语法解析流程,scan.l文件对SQL查询进行词法解析处理,生成token,gram.y文件将token解析并生成“原始”语法树,analyze.c文件则是对可以优化的查询进行顶层解析分析。下面的一系列parser_xxx.c文件则是针对于SQL的不同子结构进行专门处理,帮助生成最终的Query结构。
2.2 涉及的数据结构:
词法分析:token结构体,包含类型和值
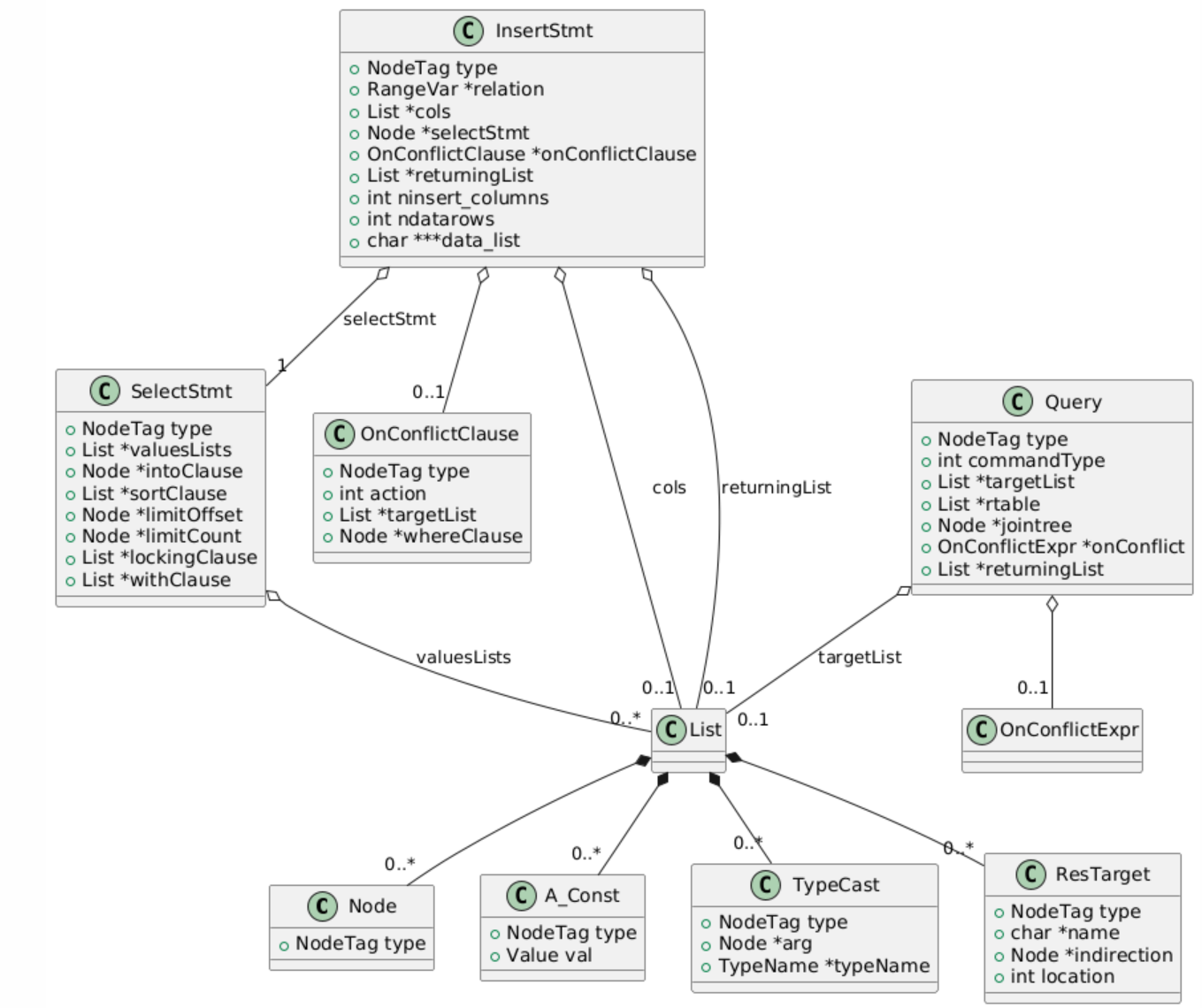
语法树:AST节点(Node为基类,RawStmt/SelectStmt等为子类)
分析后结果:Query结构体,包含所有执行所需信息
中间结果:List链表、ParseState上下文等
部分抽象语法树(AST)的节点类图如下所示:
2.3 主要实现源码分析
parser.c代码文件分析:
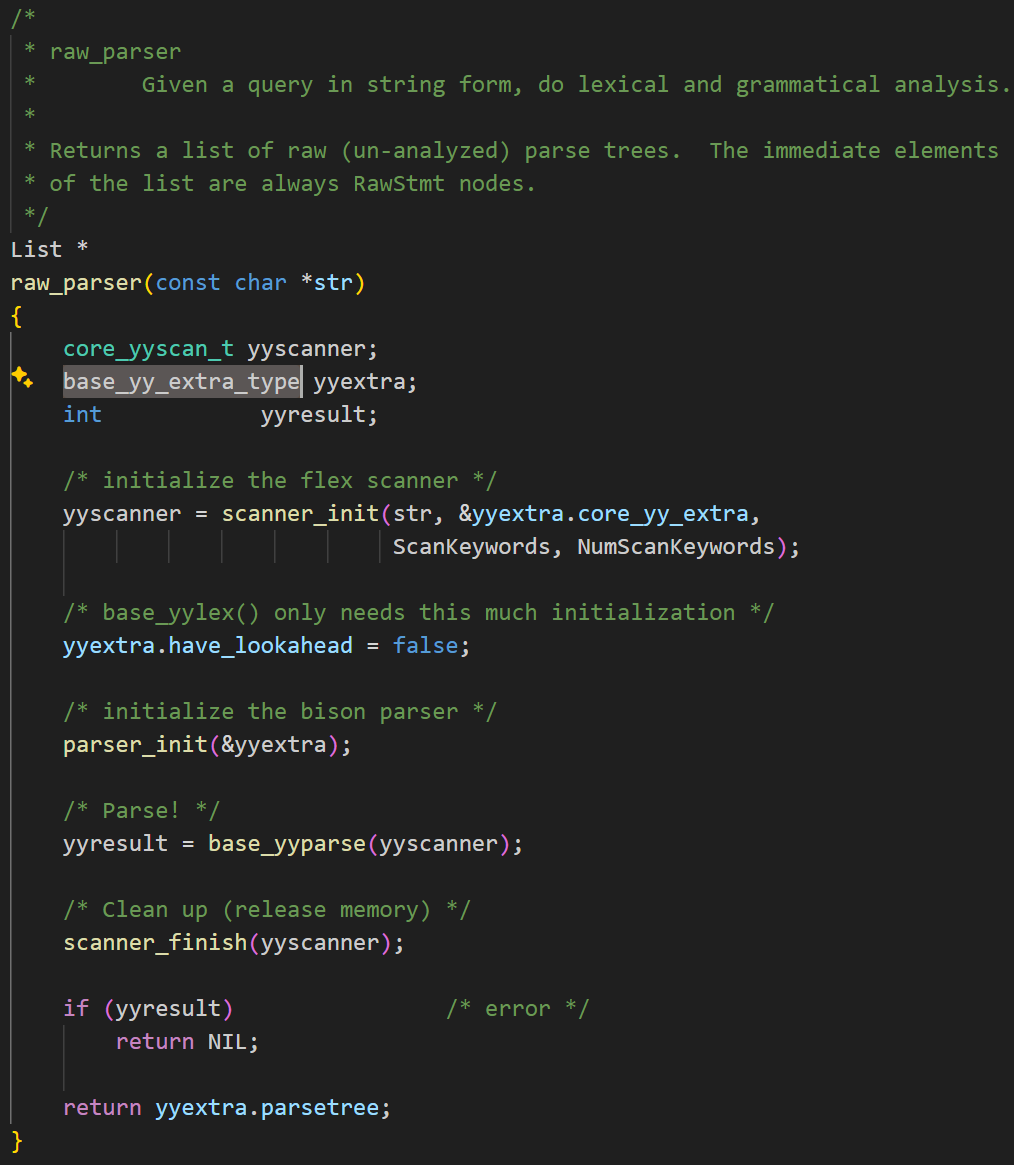
raw_parser函数实现:
该函数是SQL文本解析入口函数,实现了SQL字符串到原始语法树的转换。首先定义了词法分析器对象、存储扫描器和解析器状态的结构体、和解析结果状态。之后初始化Flex词法分析器,并传入SQL文本和关键字表,设置扫描器状态。指定没有lookahead(预读)token,并传递yyextra给Bison语法分析器进行初始化,作为全局状态。然后进行解析,生成RawStmt链表,存储在yyextra.parsetree中,并释放scanner相关内存。
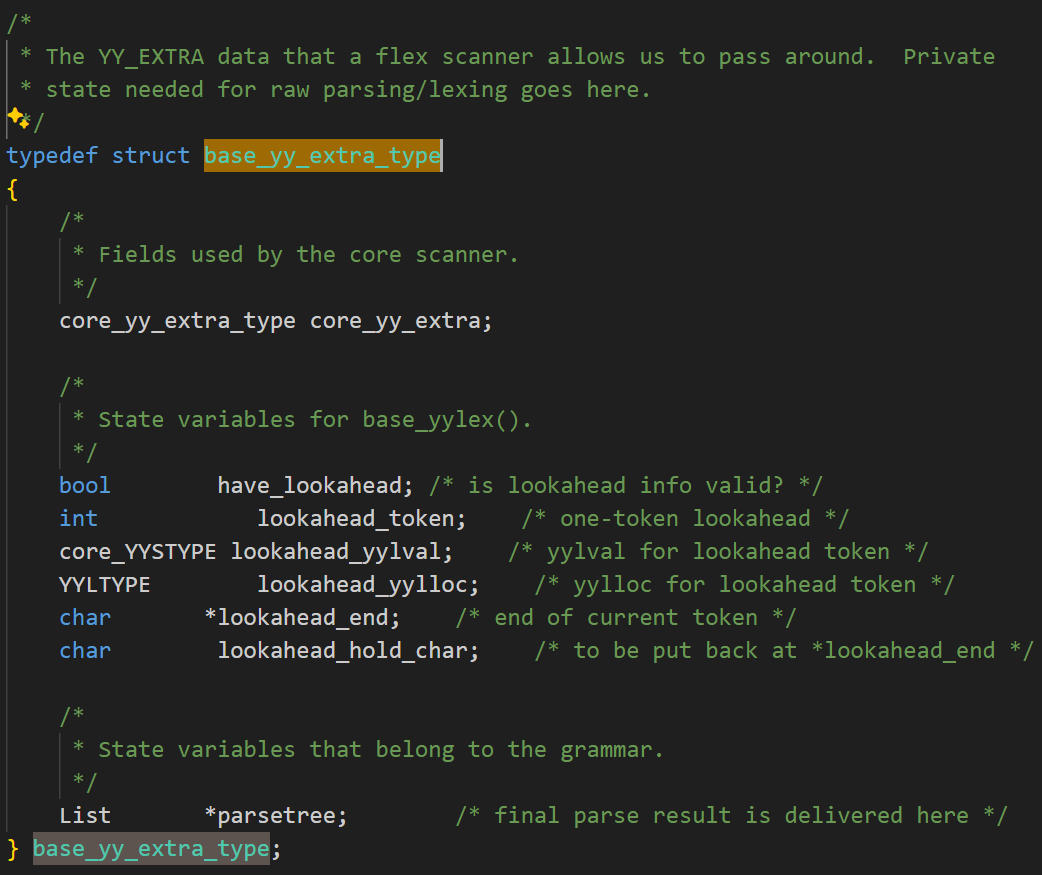
其中yyextra的类型为base_yy_extra_type。base_yy_extra_type 是解析过程中的全局状态结构体,既为词法分析器(scanner)和语法分析器(parser)共享,也保存了解析过程中的中间状态和最终结果。core_yy_extra里面包含的是词法分析器自身状态信息,lookahead_yylval存放的是lookahead的token语义值,lookahead_yylloc中则是lookahead的token位置信息。该结构体SQL解析时会在多个阶段被反复传递和修改,实现了解析全流程中的状态共享和结果传递。结构实现如下图所示:
base_yylex函数实现:
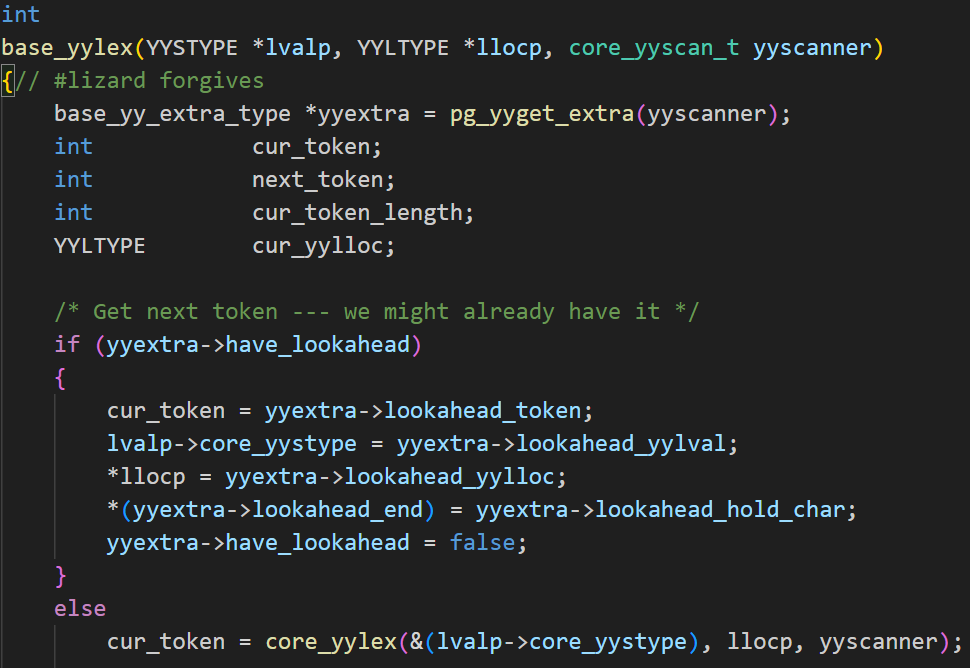
base_yylex是词法分析器和语法分析器之间的中间层,由于Bison语法分析器是LALR(1),即只支持单token前瞻的,该函数可以通过预读下一个token并在当前层处理需要多个token前瞻才能正确解析的特殊情况,是语法分析器仍保持了LALR(1)的特性。
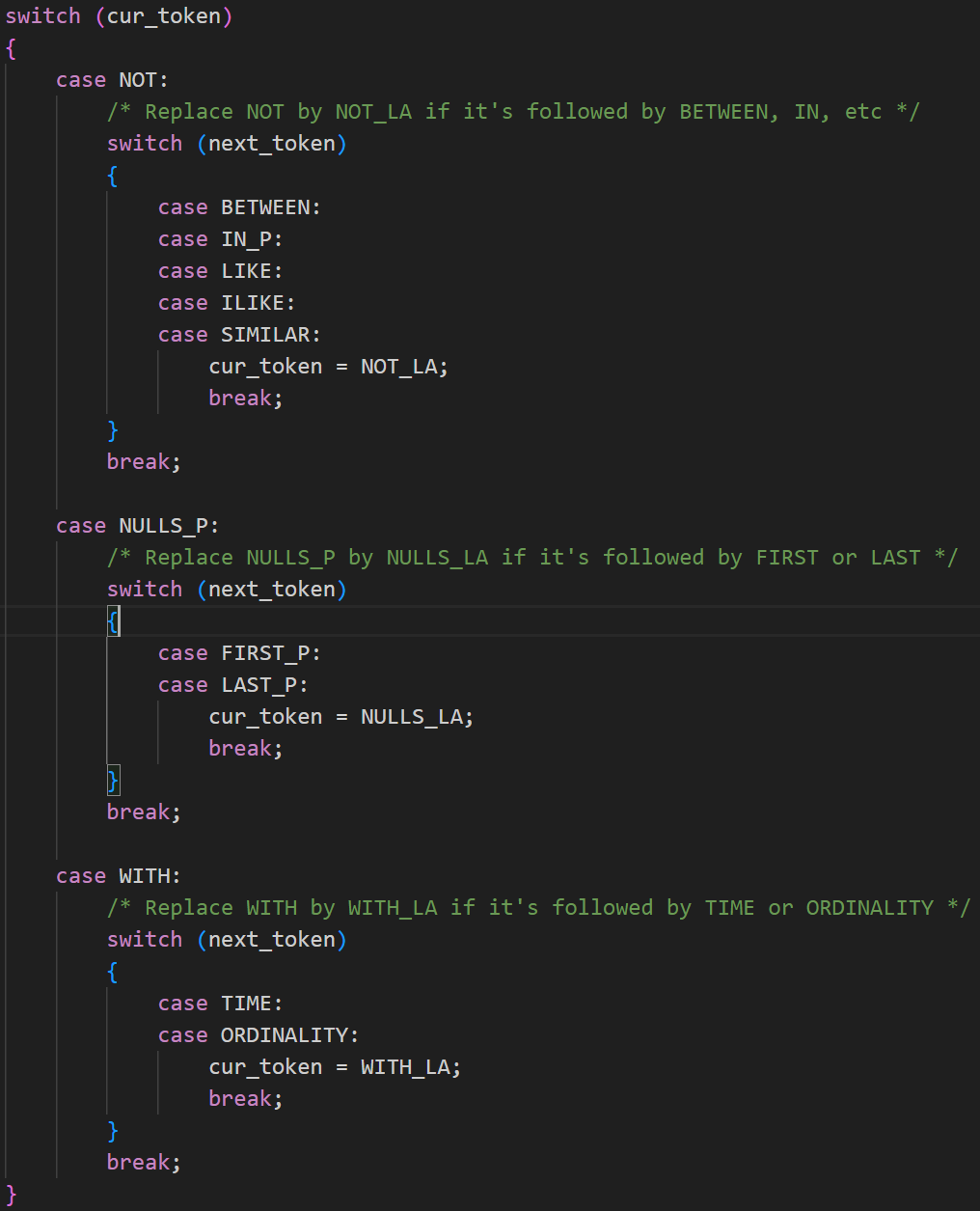
base_yylex函数有三个参数,分别为lvalp(指向当前token语义值的指针),llocp(指向当前token位置信息的指针),和yyscanner(词法分析器状态对象)。首先是获取当前的token,要么使用缓存的前瞻token作为当前token,要么从核心词法分析器中获取新token。根据当前token判断是否需要进行前瞻处理。如果需要,则设置前瞻结束的位置,并保存当前token位置,获取下一个token。下面是特殊token的替换逻辑,在需要前瞻的token后加上_LA。
analyze.c 代码文件分析:
analyze.c是将原始解析树(raw parse tree)转换为查询树(query tree)的关键模块。它处理各种 SQL 语句的语义分析,包括 SELECT、INSERT、UPDATE、DELETE 等 DML 语句,以及 DECLARE CURSOR、EXPLAIN 等特殊语句。
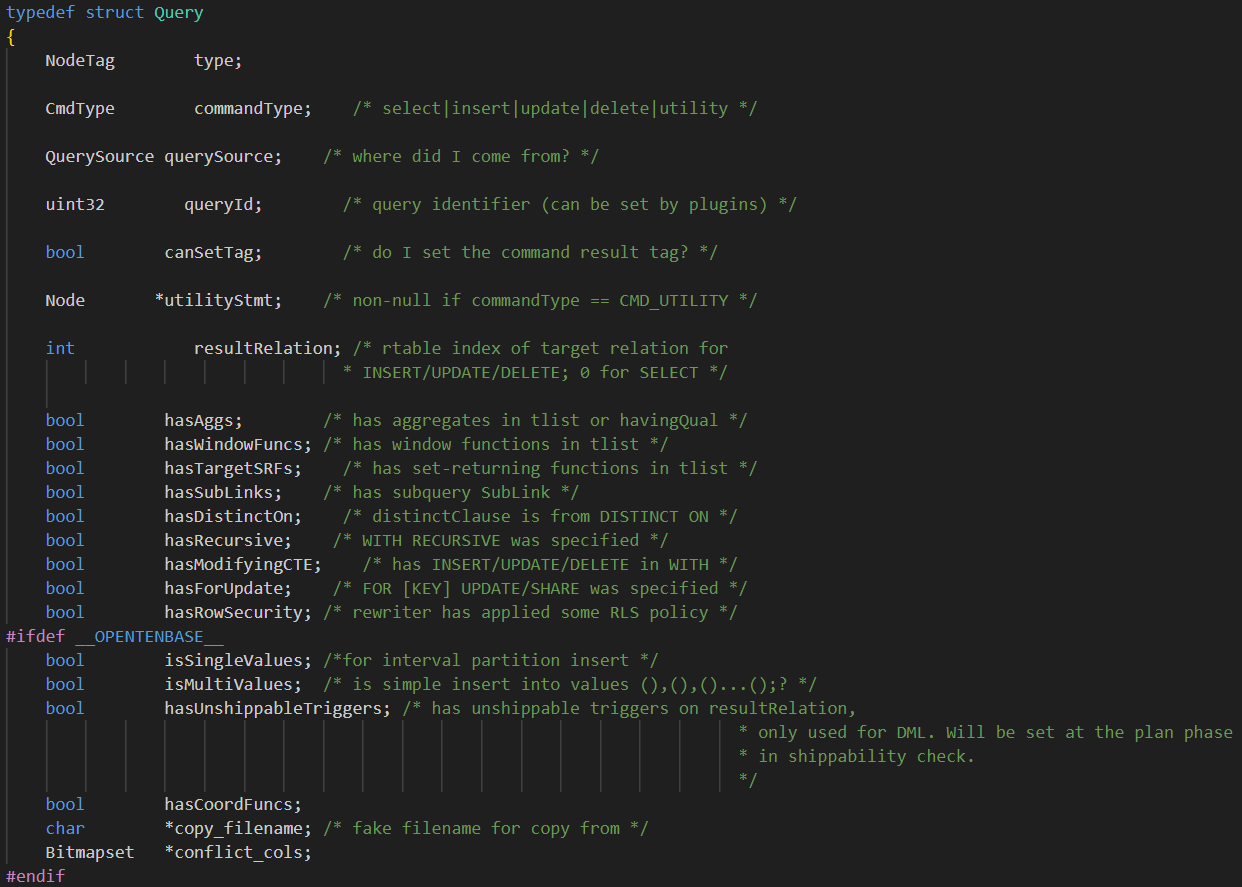
其中的关键数据结构是Query,下面为该数据结构定义:
以核心函数transformInsertStmt的源码实现为例进行分析:
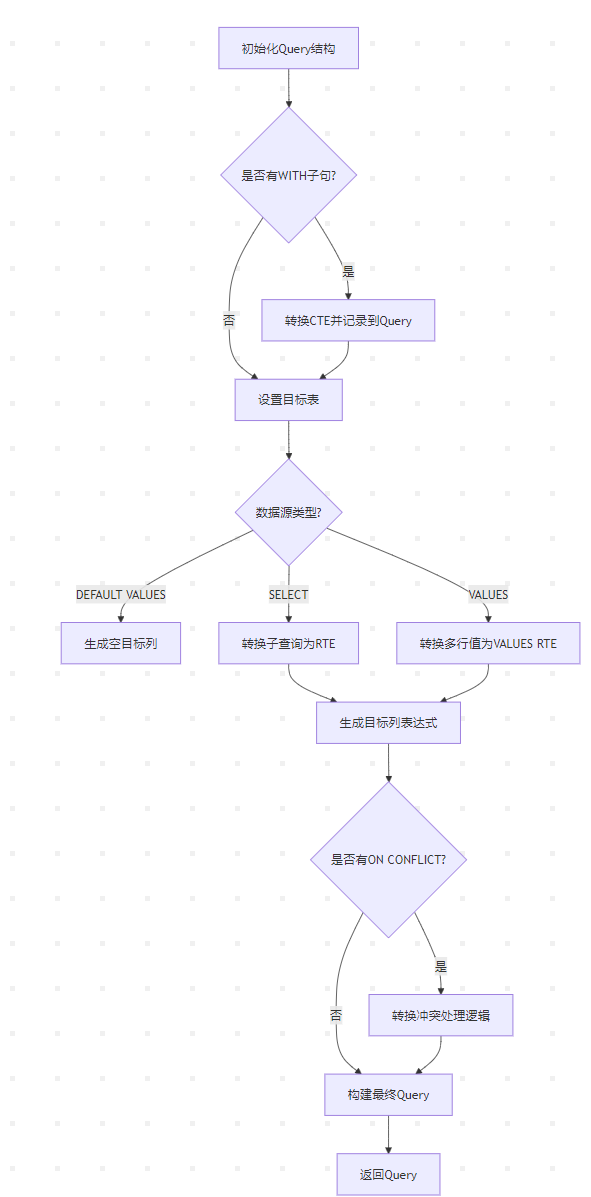
该函数参数有两个,分别是pstate(当前解析状态)和stmt(原始的INSERT语句解析树)。函数首先对Query初始化,创建空的Query节点,标记为INSERT操作并设置解析状态标志。如果存在WITH字句,则使用parse_cte.c文件中的transformWithClause函数进行递归转换,并记录到查询树中。之后,设置目标表,并验证目标列是否合法。
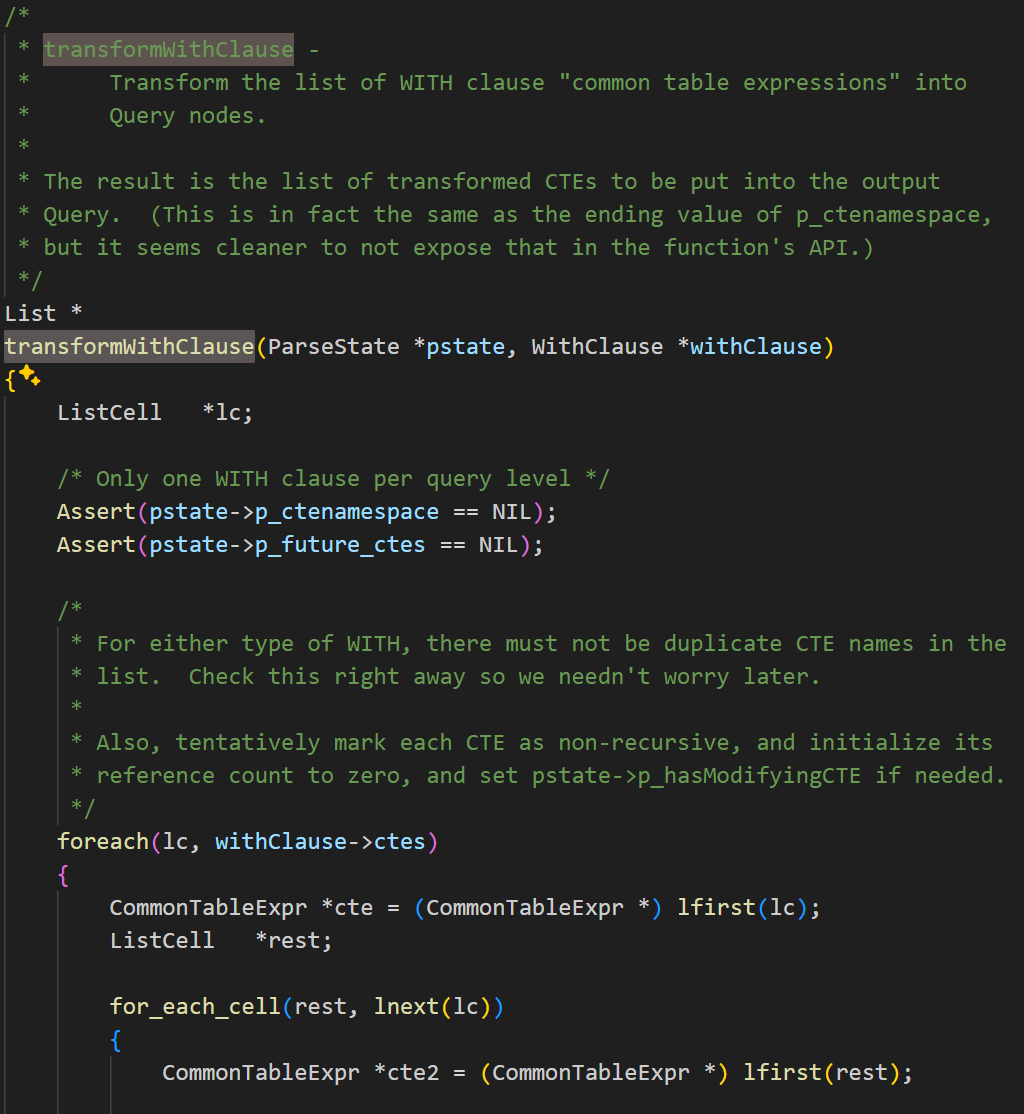
INSERT语句有三种不同的形式,分别为INSERT……DEFAULT VALUES,INSERT……SELECT,和INSERT……VALUES。将这三种形式的INSERT分别处理,第一种情况,生成一个空的目标列列表,当规划器展开目标列列表时,会为所有列自动填充默认值。第二种情况,创建子查询的独立解析环境,转换子查询为Query结构,并将子查询作为范围表项添加到主查询。最后将子查询的列映射为目标列的表达式。第三种情况,需要对多行VALUES进行处理,首先看是否可以使用opentenbase特有的COPY FROM优化,在满足一定条件时(如分布式表、无触发器等),可以尝试将多行VALUES转换为COPY FROM,此时会把所有 VALUES 数据提取到 stmt->data_list,并设置 qry->copy_filename(如图2.3-1)。如果不能进行优化,则进入TRANSFORM_VALUELISTS标签,逐行处理每一个VALUES子列表。对每一行,会调用transformExpressionList函数进行表达式转换,之后调用transformInsertRow函数做列映射和类型转换(如图2.3-2, 2.3-3)。
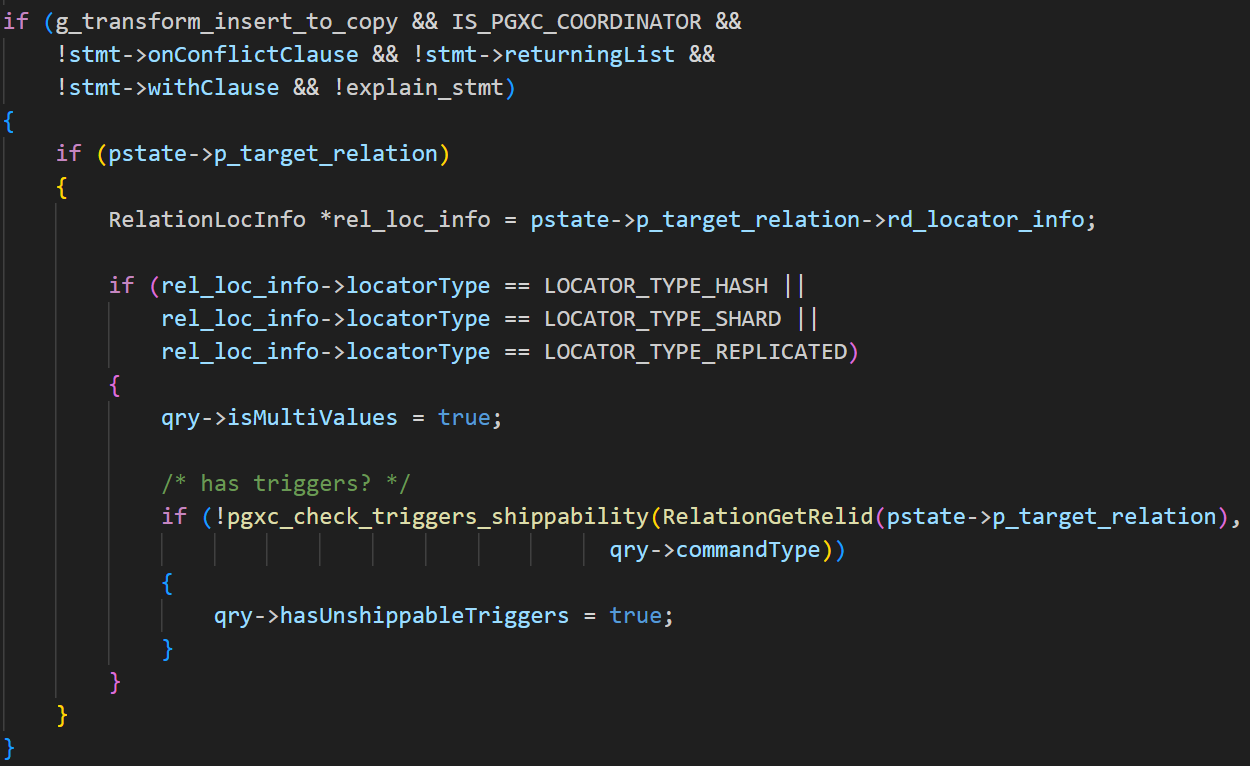
图2.3-1
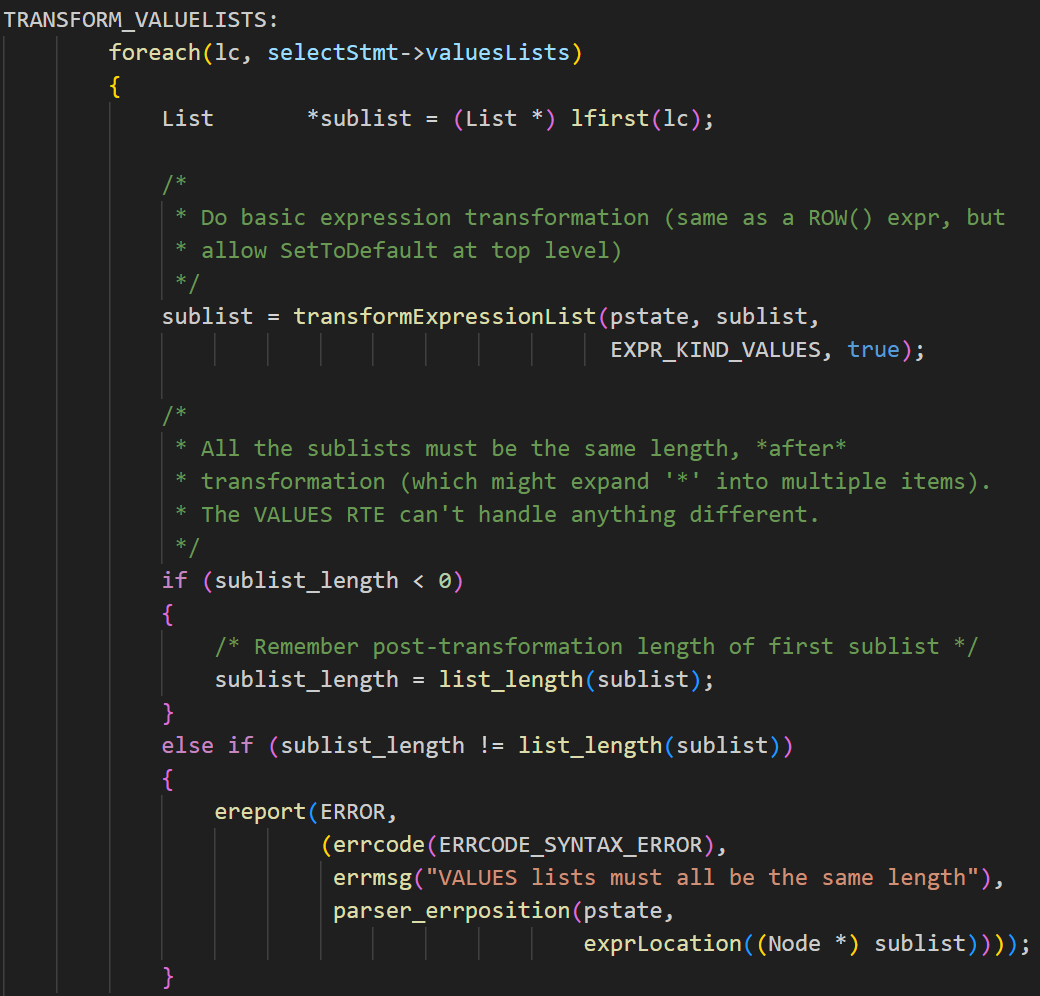
图2.3-2
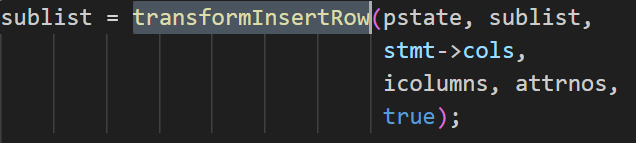
图2.3-3
生成目标列表达式之后,会对ON CONFLICT进行判断处理,最后构建Query并返回构建的Query。transformInsertStmt函数的执行流程图如下所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









