



改进用于手写文本识别的卷积模型,主要观点是:手写体一般都是每行字为一份数据集,因此可以使用一维卷积来降低模型复杂程度,使用SE来获取上下文信息。同时也对数据进行了数据增强(使用TACO技术)
一:环境:
cpu环境下①②③不下载,直接下载tensorflow即可
只需执行pip install tensorflow
gpu环境下:
①tensorflow-gpu=2.10.1
②cuda==11.5
③cudnn为cudnn-windows-x86_64-8.9.6.50_cuda11-archive
opencv-python matplotlib editdistance taco-box tqdm均安装最新版即可
二:模型整体架构
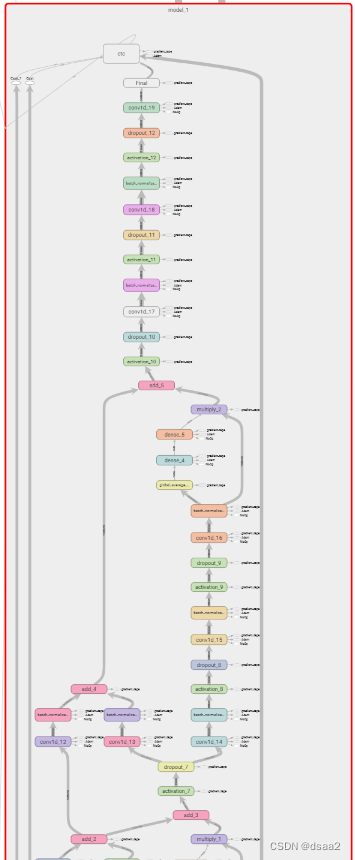
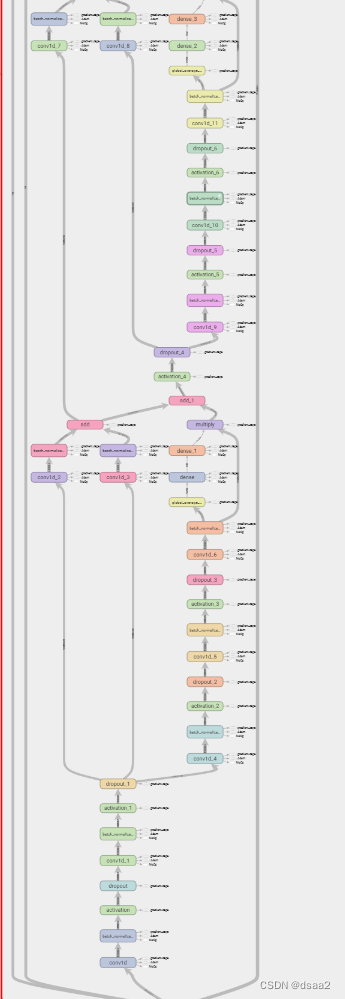
三:技术介绍
①TACo技术:
-
Tiling(平铺):将输入图像切割成多个大小相等的小瓦片(Tw)。这里的Tw指的是瓦片的宽度。
-
Corruption(损坏):在平铺之后,以损坏步骤的形式,用损坏的瓦片替换一部分(Cp)的瓦片。Cp是一个超参数,用于设置损坏概率。
-
Stitching(缝合):最后,将瓦片按照相同的顺序缝合回去,以获得增强后的图像。
-
Tile Width(瓦片宽度):瓦片宽度Tw是从输入图像高度H的10%到最大瓦片宽度参数Tmax之间的均匀分布中采样的。
-
应用方向:TACo增强可以应用于输入图像的高度(H)、宽度(W)或两者。

②SE技术:
- Squeeze: 这个步骤涉及全局池化(通常是平均池化),将特征图转换为一个单一的通道,从而捕获整个特征图的全局信息。
- Excitation: 这个步骤涉及学习一个权重向量,每个权重对应原始特征图中的一个通道。这些权重通过两层全连接(FC)层和ReLU激活函数来计算,并通过Sigmoid函数进行归一化,以生成每个通道的重要性权重。
四:效果对比
论文中的效果图: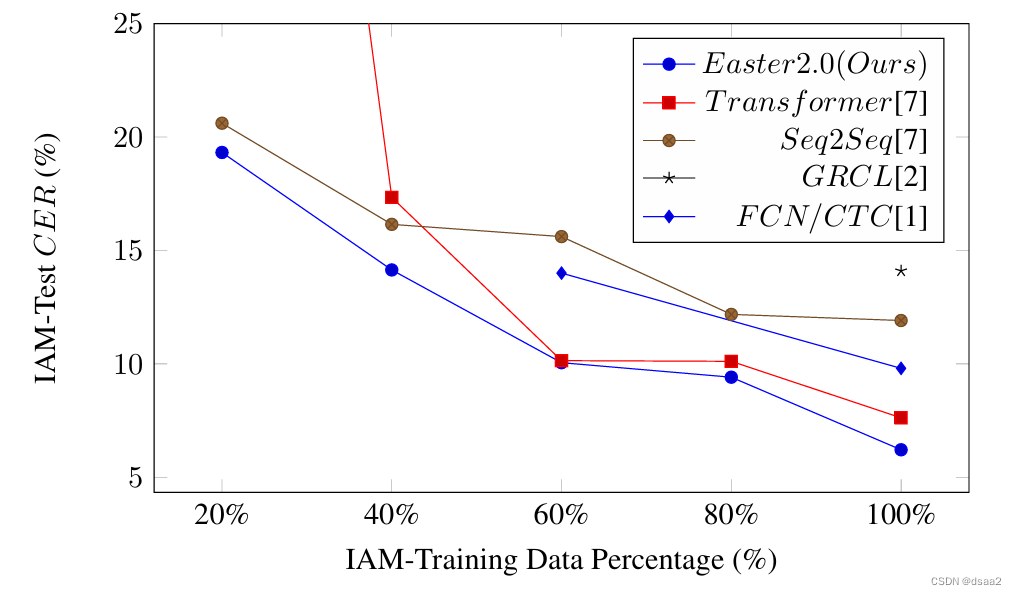
论文中的实际应用效果图:
本人实际运行效果图: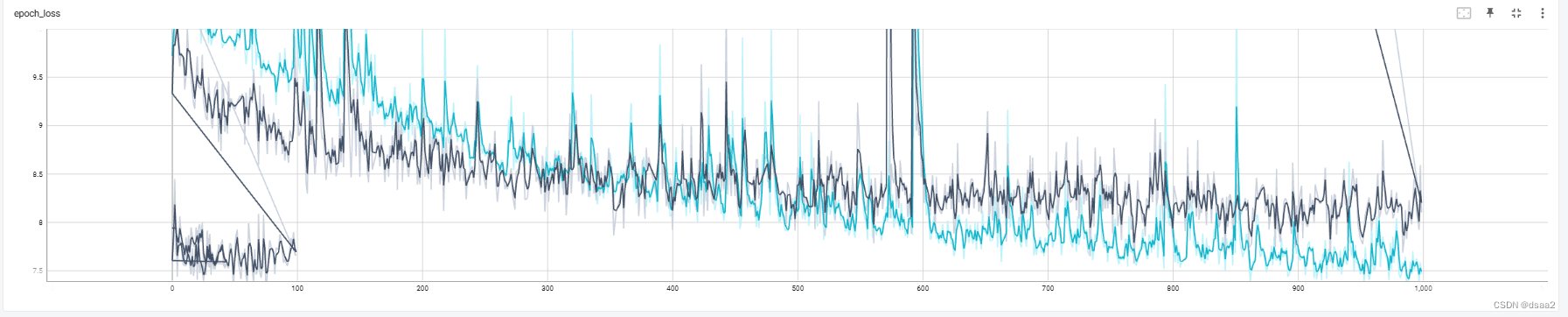
训练结束后执行,即可查看训练效果
python -m tensorboard.main --logdir logs

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









