



 本文围绕C语言展开,介绍了void类型指针的使用,如作为左右值的规则及在函数中的应用;阐述了const、volatile等关键字特性;还提及柔性数组、联合体、enum类型等。此外,讲解了预处理、编译等程序执行步骤,以及宏定义、条件编译等内容,最后强调了内存管理和防止泄漏的要点。
本文围绕C语言展开,介绍了void类型指针的使用,如作为左右值的规则及在函数中的应用;阐述了const、volatile等关键字特性;还提及柔性数组、联合体、enum类型等。此外,讲解了预处理、编译等程序执行步骤,以及宏定义、条件编译等内容,最后强调了内存管理和防止泄漏的要点。
void类型的指针作为左值是可以接收任意类型指针的赋值;作为右值时,需要进行类型强制类型转换。常用于函数接收指针参数时不知道实参为何种类型指针时使用:例如memset()函数:
Memset(void* src,int c,typecount)讲src地址起的typecount个单位设置为c常用于置0,因为memset内部是操作char类型的单个字节赋值,
void Memset(void* src, int n, int length) {
unsigned char* p = (unsigned char*)src //;
for (int i = 0; i < length; i++) {
p[i] = n //只能每个字节依次操作;
}
}
//假如给一个int类型连续地址赋值1:memset(int *,int n(1),int length)
//int类型为32位,memset只能操作8位单字节赋值,则赋值一个之后为:
//00000001 00000001 00000001 00000001 ,这和你想要的赋值结果大相径庭。
const:只读变量,不是常量,只是告诉编译器const变量不能出现在赋值符号的右边:
1、在修饰局部变量时,在栈上分配空间。
2、在修饰全局变量时,在全局的数据区分配空间。
3、在编译时有用,在运行时无用。
const变量可通过指针修改:
const int ci = 5;
printf("ci = %d\n", ci);
int* p = (int*)&ci;
*p = 10;
printf("ci = %d\n", ci);
//当const变量在全局创建的时候,用指针修改会报错,因为全局的const变量会存
//储在全局只读存储区里面--》BCC编译器可修改。
被static 修饰的const变量的生命周期为全局,所以在局部声明时也不可被修改。
总结:具有全局生命周期的const变量会被分配到只读存储区。不可修改。
字符串字面量默认存储在只读存储区,应当用const char*修饰。
volatile:编译器警告指示字,主要用于可能会被许多因素改变的变量,例如多线程程序,警告编译器在每次用该变量时都需要区内存里拿。
柔性数组:
#include<stdio.h>
#include<malloc.h>
struct SoftArray {
int len;
int array[];
};
struct SoftArray* create_s_arr(int size) {
struct SoftArray* sa = NULL;
if (size > 0) {
sa = (struct SoftArray*)malloc(sizeof(struct SoftArray) + sizeof(int) * size);
sa->len = size;
}
else {
printf("柔性数组的大小不能小于0\n");
}
return sa;
}
void calculate(struct SoftArray* p) {
int i;
for (i = 0; i < p->len;i++) {
p->array[i] = i + 1;
}
}
void delete_s_arr(struct SoftArray* sa) {
free(sa);
}
int main()
{
struct SoftArray* s1 = create_s_arr(10);
calculate(s1);
for (int i = 0; i < s1->len; i++) {
printf("%d ", s1->array[i]);
}
}
联合体:union:只会分配内存占比最大成员的空间,受系统大小端影响。
union obj {
int i;
char c;
};
int main()
{
union obj u;
u.i = 1;
printf("%d", u.c); // 输出1; char去低地址区,系统为小端模式。
}
enum类型常规用法:

还可以用来定义真正意义上的常量:
int main()
{
enum {
arr_size = 10
};
printf("%d", arr_size);
}
sizeof()的本质:sizeof非函数,在编译时会把sizeof替换为具体的值;
int fun() {
printf("hello man");
//不会输出该句话,因为fun()函数得不到执行,在编译时会把sizeof替换为4;
return 0;
}
int main()
{
int size = sizeof(fun());
printf("%d", size); //4
}
位运算符:

利用位运算异或操作符交换两个数:

当|| 和 && 在一起使用时:
int i = 0;
int j = 0;
int k = 0;
if (++i || ++j && ++k) { //&&比||优先级高,但是这里在一起使用时,系统会自动补充为true && ++i || ++j && ++k ;
printf("123\n"); //被执行
}
printf("i = %d\nj = %d\nk = %d\n", i, j, k); //1 0 0
++和–混合运算可能结果出乎意料
int main()
{
int i = 0;
int r = 0;
r = (i++) + (i++) + (i++);
printf("i = %d\n", i); //3
printf("r = %d\n", r); //0
r = (++i) + (++i) + (++i);
printf("i = %d\n", i); //6
printf("r = %d\n", r); //18
return 0;
}
三目运算符:a<b?a:b
三目运算符返回a,b,较高类型,char,short转换为int,int类型转换为double,通过隐式类型转换,当不能转换时,报错
short s = 0;
int i = 0;
double d = 0;
char* p = "str";
printf("%d", sizeof(c ? c : s)); //4
printf("%d", sizeof(c ? s : i)); //4
printf("%d", sizeof(c ? i : d)); //8
printf("%d", sizeof(c ? d : p)); //出错
利用三目运算符,一行代码实现strlen(void *s)
#include <stdio.h>
#include<assert.h>
int strlen(const char* s) {
return assert(s),(*s ? strlen(s + 1) + 1 : 0);
}
int main()
{
printf("%d", strlen(NULL));
return 0;
}
程序的一个F5,执行了几步:

预处理:

编译:

汇编:

链接:

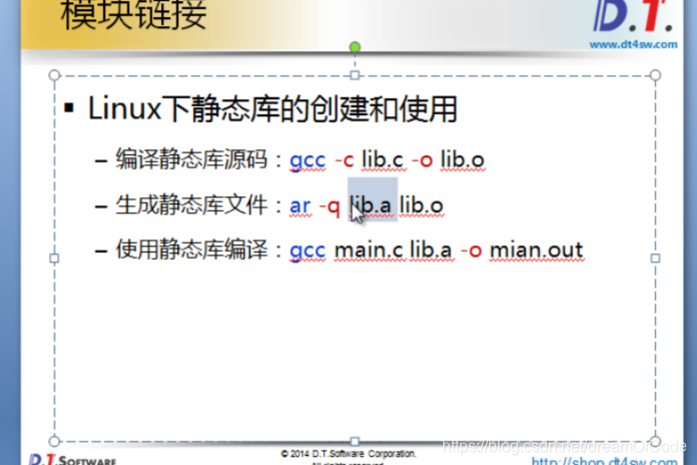


#define定义的宏是字面量,不占用内存。在预编译是会空格替代,代码中的宏会被文本代换。
宏定义求数组大小:
#define LEN_ARR(src) sizeof(src)/sizeof(*src)
int main()
{
int a[10] = { 0 };
printf("%d", LEN_ARR(a));
return 0;
}
宏定义无作用域限制:
#include<stdio.h>
#define LEN_ARR(src) sizeof(src)/sizeof(*src)
void temp() {
#define a 10
}
int main()
{
int i = 0;
i = a;
printf("%d",i); //10
}
系统定义的宏:

宏的强大应用:
#include<stdio.h>
#include<malloc.h>
#define Malloc(type,n) (type*)malloc(sizeof(type)*n)
#define Free(p) (free(p),p = NULL)
#define Foreach(i,m) for(i = 0;i<m;i++)
#define LOG(s) printf("%s\n%s\n%d\n%s\n",__FILE__,__DATE__,__LINE__,s)
#define begin {
#define end }
int main()
{
int i = 0;
int* p = Malloc(int, 5);
LOG("hello world");
Foreach(i,5)
begin
p[i] = i;
end
Foreach(i, 5)
begin
printf("%d ", p[i]);
end
Free(p);
printf("End");
return 0;
}
条件编译:预编译阶段进行分支判断,控制预编译阶段哪一段代码用于编译。保留哪一段,删除哪一段。
格式:#if…#else…#endif
在linux下时,可通过命令行定义一个临时的宏用于改变条件编译时与编译器选择的分支:
格式 : gcc -D宏名字 = value file.c or gcc -D file.c(通常用于#ifdef)
利用条件编译可以避免多文件时代码重复:
#ifndef obj1_flag //加上标志符
#define obj1_flag
#include "obj2.h"
const char * name = "jiang";
int obj1_val = 10;
#endif
#error和#warning的使用:
#error message
#warning message
以上都无双引号,用来输出错误或者警告信息。
#line 从新定义行号和文件名 : #line 1 “test.c”
#pragma预处理器指示字
常用
#pragma message : 在预编译期间的提示字
#pragma once : 告诉编译器文件只编译一次,不是所有编译器都支持,考虑到部分不支持,通常搭配#ifndef一起使用
#pragma pack : 用于指定内存对齐方式,通常用于struct中的内存不对其。
#pragma pack(4) //系统默认pack为4 偏移地址必须要被对其参数或者pack较小的整除
struct a { //对齐参数 偏移地址 大小
char a; //1 0 1
short b; //2 2 2
char c; //1 4 1
int d; //4 8 4
};
#pragma pack()
//把pack修改为1后
/*#pragma pack(1)
struct a { //对齐参数 偏移地址 大小 偏移地址必须要被对其参数或者pack较小的整除
char a; //1 0 1
short b; //2 1 2
char c; //1 3 1
int d; //4 4 4
};
#pragma pack() */
#pragma pack(4)
struct b { //对齐参数 偏移地址 大小
char a; //1 0 1
char b; //1 1 1
short c; //2 2 2
int d; //4 4 4
};
#pragma pack(0)
int main()
{
struct a m;
struct b p;
printf("m = %d\np = %d", sizeof(m), sizeof(p)); //m = 12 p = 8;
return 0;
}
结构体总长度必须为所有对齐参数的整数倍;
结构体成员的对齐参数大小取内部成员长度最大的对齐参数大小 、
#操作符是在预编译阶段处理的,处理结果是将宏#后的参数转换为字符串,
#include<stdio.h>
#define CALL(func_name,func_setting) (printf("Call function is %s\n",#func_name),func_name(func_setting)) //#操作符用于将宏参数转换为字符串
int square(int n)
{
return n * n;
}
int func(int n)
{
return n;
}
int main()
{
int result = 0;
result = CALL(square, 4);
printf("result = %d\n", result);
result = CALL(func, 10);
printf("result = %d\n", result);
return 0;
}
预处理以后,这段代码变为:
# 1 "hello.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 1 "<command-line>" 2
# 1 "hello.c"
int square(int n)
{
return n * n;
}
int func(int n)
{
return n;
}
int main()
{
int result = 0;
result = (printf("Call function is %s\n","square"),square(4));
result = (printf("Call function is %s\n","func"),func(10));
return 0;
}
##将前后字符粘结在一起。
当指针和const一起用时,左数右指,const在*左时数不变,在右边指针不可变。
指针运算:p+n 《–》 (unsigned int)p + sizeof(*p)*n
指针之间只支持减法:p1-p2;(只有在指向同一数组时可以使用)
小知识点:a[n] = n[a] ->> *(a+n) == *(n+a)
当数组在外部程序时,想要使用数组名获得数组地址是不合理的,因为程序会去数组里面取4个字节,然而这4个字节是数组的值。
数组名不是指针,知识看起来像指针;
a+1 ->> (unsigned int)a+sizeof(a)
&a+1 ->> (unsigned int)&a+sizeof(&a)
->> (unsigned int)&a+sizeof(a) 这里,它跨过了整个数组,如下印证。
#include<stdio.h>
int main()
{
int a[5] = { 1,2,3,4,5 };
int* p = &a[1];
int* q = &a[4];
q++;
printf("%p\n", p); //00BFF71C
printf("%p\n", a+1); //00BFF71C
printf("%p\n", &a+1); //00BFF72C
printf("%p\n", q); //00BFF72C
return 0;
}
下面是一个地址如果被int转化+1后的结果
#include<stdio.h>
int main()
{
int a[5] = { 5,6,7,8,9 }; //内存:50006000700080009000
int* p = a;
p = (unsigned int*)((int)p + 1); //读取:0006 转化为地址就是0x06000000
printf("%d", *p); //输出06000000的十进制数;
}
字符串存储在只读存储区中。
无名字符数组“”abc“【0】 = ”a“
(“123”+1) = 2
int("") = 0 //’\0’的ASCLL码是0
字符串右移动代码:
#include<stdio.h>
#include<string.h>
void right_shift(const char* src, char* result, int num) {
const unsigned int len = strlen(src);
for (int i = 0; i < len; i++) {
result[(num+i)%len] = src[i];
}
result[len] = '\0';
}
int main()
{
char* temp = "abcdef";
char result[255] = {0};
right_shift(temp, result, 3);
printf("%s", result);
return 0;
}
数组指针:
#include<stdio.h>
#include<string.h>
typedef int(AINT5)[5]; //数组类型重命名
typedef float(AFLOAT10)[10];
int main()
{
AINT5 arr5;
AINT5* p = &arr5;
printf("%p\n%d", p,sizeof(arr5));
int(*pi)[5] = &arr5; //定义一个数组指针,它指向一个int型5个元素的数组;
// 等价于AINT5 *pi;
for (int i = 0; i < 5; i++) {
*(p)[i] = i;
}
for (int i = 0; i < 5; i++) {
printf("%d ", *p[i]);
}
}
指针数组:存放指针的数组
格式:int*a[5].
利用指针数组查找字符串代码实例:
#include<stdio.h>
#include<string.h>
#define STRLEN(src) sizeof(src)/sizeof(*src)
int find_str(char* src, char* keyword[],int len) {
int ret = -1;
for (int i = 0; i < len;i++) {
if (strcmp(src,keyword[i]) == 0) {
ret = i;
break;
}
}
return ret;
}
int main()
{
char* keyword[] = {
"doing",
"jiang",
"yuan",
"switch",
"window",
"yellow"
};
char* s1 = "jiang";
char* s2 = "window";
printf("%d", find_str(s2, keyword,STRLEN(keyword)));
}
main函数的可用参数:


在gcc中,main函数可能不是系统第一个调用的函数,他可以用__attribute__关键字改变系统的调用顺序。
在linux下运行一下代码:
#include<stdio.h>
#ifndef __GNUC__
#define __attribute(x)
#endif
__attribute__((constructor)) //在main之前执行
void before_main() {
printf("%s\n", "before_function");
}
__attribute__((destructor)) //在main之后执行
void before_main() {
printf("%s\n", "after_function");
}
int main()
{
printf("%s\n", "main");
return 0;
}
//输出 before_main
main
after_main
动态修改内存空间的大小的代码:二维指针的应用
#include<stdio.h>
#include<malloc.h>
void reset(char** p, int size, int new_size) { //p为二维指针
char* new_p = (char*)malloc(new_size);
char* temp = NULL; //移动指针
temp = new_p;
char* pp = *p; //移动指针
int i;
if ((p != NULL) && new_size > 0) {
int len = size < new_size ? size : new_size;
for (i = 0; i < len; i++) {
*temp++ = *pp++;
}
}
free(*p);
*p = new_p;
}
int main()
{
char* p = (char*)malloc(5);
printf("%p\n", p);
reset(&p, 5, 10);
printf("%p\n", p);
return 0;
}
二维数组的打印于指针输出格式:强化指针概念
#include<stdio.h>
#include<malloc.h>
int main()
{
int sec_arr[3][3] = {
{1,2,3},
{4,5,6},
{7,8,9}
};
int b[] = { 1,2,3 };
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
printf("%d", *(*(sec_arr + i) + j)); //*(*(sec_arr + i) + j = a[i][j
}
printf("\n");
}
printf("%d", *(b + 1));
}
在a[3][3]里a即是a[0]的地址又是a[0][0]的地址,即a不是一个指针,是一个常量a[0][0]的值,所以a不是一个二级指针,但是他又是一个指向a[0]的地址,它指向了一个数组,它是一个数组指针 int()[3];
利用二维指针模拟二维数组:
#include<stdio.h>
#include<malloc.h>
int** twicepoint(int row, int col) {
int** ret = NULL;
if ((row > 0) && (col > 0)) {
ret = (int**)malloc(sizeof(int*) * row);
int* p = NULL;
p = (int*)malloc(sizeof(int) * row * col);
if ((ret != NULL) && (p != NULL)) {
int i;
for (i = 0; i < row; i++) {
ret[i] = p + i * col;
}
}
else {
free(ret);
free(p);
ret = NULL;
}
}
return ret;
}
void free_po2(int** p) {
if ((*p) != NULL) {
free(p);
}
free(p);
}
int main()
{
int** my_arr = twicepoint(3, 3);
int i, j;
for (i = 0; i < 3; i++) {
for (j = 0; j < 3; j++) {
my_arr[i][j] = i * j;
}
}
for (i = 0; i < 3; i++) {
for (j = 0; j < 3; j++) {
printf("%d ", my_arr[i][j]);
}
printf("\n");
}
return 0;
}

C语言可以利用一个函数指针,给它一个函数地址,他就可以直接跳转到这哥地方执行
回调函数:函数指针实现–funtype(*)()
一个打怪demo的回调函数使用:
#include<stdio.h>
#include<malloc.h>
typedef int(*weapon)(int);
void fight(weapon wp, int n) { //回调函数入口
int sum;
sum = wp(n);
printf("Boss loss : %d\n", sum);
}
int knife(int n) { //回调函数
int power = 1;
int ret = 0;
for (int i = 0; i < n; i++) {
printf("attack : %d\n", power);
ret++;
}
return ret;
}
int sword(int n) { //回调函数
int power = 5;
int ret = 0;
for (int i = 0; i < n; i++) {
printf("attack : %d\n", power);
ret+=5;
}
return ret;
}
int gun(int n) { //回调函数
int power = 10;
int ret = 0;
for (int i = 0; i < n; i++) {
printf("attack : %d\n", power);
ret+=10;
}
return ret;
}
int main()
{
fight(knife, 5);
return 0;
}
关于复杂指针利用typedef简化可读性:
#include <stdio.h>
int main()
{
int (*p1)(int*, int (*f)(int*));
p1为指针,指向一个函数,函数类型为int(int*, int(*)(int*))
typedef int(funtype)(int*, int(*)(int*))
typedef functype* p;
int (*p2[5])(int*);
p2为数组,数组元素为指针,指向函数,函数类型为int(int*)
typedef int(functype)(int*)
typedef int(p2)[5]
typedef functype*p2
int (*(*p3)[5])(int*);
p3为指针,指向一个5个元素的数组,数组类型为指针,指向函数,函数类型为int(int*)
typedef int(functype)(int*)
typedef functype*arraytype[5]
typedef arraytype*p3
int* (*(*p4)(int*))(int*);
p4为指针,指向参数为(int*)的函数,返回值为指针,指向一个类型为int*(int*)的函数
typedef int*(functype)(int*)
typedef functype*insidefunction(int*)
typedef insidefunction*p4
int(*(*p5)(int*))[5];
p5为指针,指向函数,函数返回值为指针,指向数组,数组类型为int[5]
typedef int(arraytype)[5]
typedef arraytype*functype(int*)
typedef *p5
return 0;
}
内存泄漏检测模块源码,输出内存泄漏的信息:
#include<stdio.h>
#include "mleak.h"
void f() {
MALLOC(10);
}
int main()
{
MALLOC(100);
MALLOC(50);
f();
PRINTF_LEAD_INFO();
return 0;
}
// mleak.h
#ifndef MLEAK_H
#define MLEAK_H
#include<malloc.h>
#define MALLOC(n) mallocEx(n,__FILE__,__LINE__)
#define FREE(p) freeEx(p)
void* mallocEx(int size, const char* file, const int line);
void freeEX(void* p);
void PRINTF_LEAD_INFO();
#endif
//mleak.c
#include "mleak.h"
#include<stdio.h>
#define arr_size 256
typedef struct {
void* pointer;
int size;
int line;
const char* file;
} M_info;
static M_info INFO_RECORD[arr_size];
void* mallocEx(int size, const char* file, const int line) {
void* ret = malloc(size);
if (ret != NULL) {
int i;
for (i = 0; i < arr_size; i++) {
if ((INFO_RECORD[i].pointer) == NULL) {
INFO_RECORD[i].pointer = ret;
INFO_RECORD[i].size = size;
INFO_RECORD[i].file = file;
INFO_RECORD[i].line = line;
break;
}
}
}
return ret;
}
void freeEX(void* p) {
if (p != NULL) {
int i;
for (i = 0; i < arr_size; i++) {
if (INFO_RECORD[i].pointer == p) {
INFO_RECORD[i].pointer = NULL;
INFO_RECORD[i].size = 0;
INFO_RECORD[i].file = NULL;
INFO_RECORD[i].line = 0;
break;
}
}
}
free(p);
}
void PRINTF_LEAD_INFO() {
int i;
for (i = 0; i < arr_size; i++) {
if (INFO_RECORD[i].pointer != NULL) {
printf("Address = %p, size = %d, file = %s, line = %d\n", INFO_RECORD[i].pointer, INFO_RECORD[i].size, INFO_RECORD[i].file, INFO_RECORD[i].line);
free(INFO_RECORD[i].pointer);
}
}
}

malloc,calloc,realloc的比较:
#include<stdio.h>
#include<malloc.h>
#define SIZE 5
int main()
{
int* PI_MAL = (int*)malloc(SIZE * sizeof(int));
int* PI_CAL = (int*)calloc(SIZE,sizeof(int));
int i;
for (i = 0; i < SIZE; i++) {
printf("PI_MAL[%d] = %d,PI_CLA[%d] = %d\n", i, PI_MAL[i], i, PI_CAL[i]); //PI_MAL里的值为随机数,PI_CAL里的值为0;
}
printf("PI_ADRESS = %p\n", PI_MAL);
printf("What is address for PI_MAL after realloc force up\n");
PI_MAL = (int*)realloc(PI_MAL, 2 * SIZE * sizeof(int));
printf("PI_ADRESS = %p\n", PI_MAL);
for (i = 0; i < 10; i++) {
printf("PI_MAL[%d] = %d\n", i, PI_MAL[i]); //扩大的内存的值也是随机值
}
return 0;
}
在函数运行过程中,主要依靠栈内存执行函数的,它用来实施函数的调用y于使用,当一个函数执行完毕之后,就会释放函数在栈上的局部变量以及一切临时变量的地址,但是这是变量还是在栈上面的,但是如果接着又有其他函数执行,那么这片空间将会被覆盖。
堆区主要是用来动态内存申请和归还
静态存储区用于保存全局变量和静态局部变量,内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在





全局变量和局部静态变量都是存储在静态存储区,但是未初始化的全局变量是放在.bss段里,初始化的变量是放在.data端里的,这样做的原因是可以让操作系统处理更快,它可以在.bss文件里快速的把变量设置为0,在.data里还需要做到相应的变量和值的映射。

防止内存泄漏的习惯
1、在动态分配内存之后,应该判断指针是否我为空。
2、free释放内存后,应当讲指针赋值为NULL。
3、在哪个函数里申请的内存,就在哪个函数释放。
4、使用关于操作内存的函数时,应当加上长度信息。
5、在申请空间后,应当进行初始化
函数的实参求值顺序时依赖编译器的。有的左到右,有的右到左
;,&&,!!,?,:都是顺序点,顺序点是内存修改的最晚时机

在c语言里,有可变参数的函数,在头文件stdarg.h里;有几个关键字:
-va_list,va_arg,va_start,va_end
#include<stdio.h>
#include<stdarg.h>
float average(int n, ...) {
va_list args;
int i;
float sum = 0;
va_start(args, n);
for (i = 0; i < n; i++) {
sum += va_arg(args, int);
}
va_end(args);
return sum / n;
}
int main()
{
printf("%f", average(5, 2, 8, 9, 13, 22)); //10.8
return 0;
}

















 1279
1279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









