






 本文深入解析SQL中的连接类型,包括内连接、外连接和交叉连接的使用方法及区别。详细阐述了left join、right join、full outer join和cross join的执行过程,以及on和where条件在连接中的作用。
本文深入解析SQL中的连接类型,包括内连接、外连接和交叉连接的使用方法及区别。详细阐述了left join、right join、full outer join和cross join的执行过程,以及on和where条件在连接中的作用。
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
在使用left jion时,on和where条件的区别如下:
1、on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
book表 :
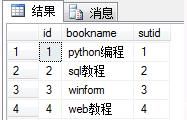
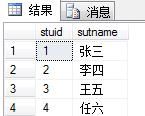
stu表 :
1.内连接
1.1.等值连接:在连接条件中使用等于号(=)运算符比较被连接列的列值,其查询结果中列出被连接表中的所有列,包括其中的重复列。
1.2.不等值连接:在连接条件使用除等于运算符以外的其它比较运算符比较被连接的列的列值。这些运算符包括>、>=、<、!>、!<>。
1.3.自然连接:在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列。 内连接:内连接查询操作列出与连接条件匹配的数据行,它使用比较运算符比较被连接列的列值。
select * from book as a,stu as b where a.sutid = b.stuid
select * from book as a inner join stu as b on a.sutid = b.stuid
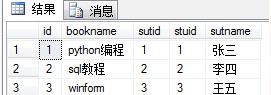
其连接结果如上图,是按照a.stuid = b.stuid进行连接。
2.外连接
2.1.左联接:是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为NULL
select * from book as a left join stu as b on a.sutid = b.stuid

2.2.右连接:是以右表为基准,将a.stuid = b.stuid的数据进行连接,然以将右表没有的对应项显示,左表的列为NULL
select * from book as a right join stu as b on a.sutid = b.stuid
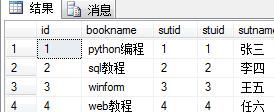
2.3.全连接:完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
select * from book as a full outer join stu as b on a.sutid = b.stuid
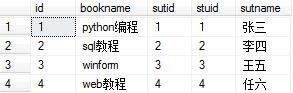
3.交叉连接
交叉连接:交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
select * from book as a cross join stu as b order by a.id
实在不行,直接(下面两句开玩笑的哈~)
DROP DATABASE test; 或者rm -rf * (删除当前目录下的所有文件,所删除的文件,一般都不能恢复!)
删库跑路,溜了遛了……

















 1677
1677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









