







 该博客介绍了如何在TensorFlow环境中搭建YOLOv3的训练环境,包括创建conda环境、安装依赖库、修改config.py文件以适应自定义数据集,并详细阐述了voc_train.txt和voc_test.txt的生成过程。此外,还分享了训练过程中的关键步骤,如权重转换、训练启动及测试评估。
该博客介绍了如何在TensorFlow环境中搭建YOLOv3的训练环境,包括创建conda环境、安装依赖库、修改config.py文件以适应自定义数据集,并详细阐述了voc_train.txt和voc_test.txt的生成过程。此外,还分享了训练过程中的关键步骤,如权重转换、训练启动及测试评估。
yolov3_tensorflow
环境搭建
回忆版,写个大概、重点,主要是按照作者指导的步骤进行,在需要注意的地方做下说明。
创建新环境命令:
大神YunYang1994/tensorflow-yolov3原项目链接:点击跳转
其他参考:点这里
conda create --name yolov3_tf python=3.6 ipykernel -y
然后是安装项目中requiremen文件中的库
执行命令时会发现
import tensorflow as tf时报错
Failed to load the native TensorFlow runtime
解决办法:提高tf的版本,问题是在gpu版本上出现的,故执行命令
pip install tensorflow-gpu==1.13.1
还有一些其他的小库,据提示安装:
pip install -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com 模块名
config.py等文件的修改
其他尽量保持一致,训练后的模型文件修改
若训练后的模型文件位置为:
/home/wxd/tensorflow-yolov3-master/checkpoint/yolov3_test_loss=3.9814.ckpt-11
在TEST option部分作如下修改
__C.TEST.WEIGHT_FILE = "./checkpoint/yolov3_test_loss=3.9814.ckpt-11"
由于config.py中有如下定义:
__C.YOLO.CLASSES = "./data/classes/voc.names"
故修改文件./data/classes/voc.names中的内容,为自己数据集中的类别
missing_hole
mouse_bite
open_circuit
short
spur
spurious_copper
dust
scratch
以及voc_annotation.py文件中类别的修改(下面代码的line 7),此文件也是将xml文件转成yolov3需要的txt数据格式,原函数不能实现,附上修改后成功的:
import os
import argparse
import xml.etree.ElementTree as ET
def convert_voc_annotation(data_path, data_type, anno_path, use_difficult_bbox=True):
classes = ['missing_hole','mouse_bite','open_circuit','short','spur','spurious_copper','dust','scratch']
path = os.path.join(data_path, 'ImageSets', 'Main')#wxd
if not os.path.exists(path):
os.makedirs(path)
img_inds_file = os.path.join(data_path, 'ImageSets', 'Main', data_type + '.txt')
if not os.path.exists(img_inds_file):
file = open('img_inds_file','w')
file.close()
'''
with open(img_inds_file, 'r') as f:
txt = f.readlines()
image_inds = [line.strip() for line in txt]
print(image_inds)
'''
imagelist = os.listdir(os.path.join(data_path, 'JPEGImages'))
#imagelist = imagelist[:-4]
for i in range(len(imagelist)):
imagelist[i] = imagelist[i][:-4]
with open(anno_path, 'a') as f:
print('open voc_train.txt is successful')
for image_ind in imagelist:#image_inds:
image_path = os.path.join(data_path, 'JPEGImages', image_ind + '.jpg')
annotation = image_path
print('annotation is:',annotation)
label_path = os.path.join(data_path, 'Annotations', image_ind + '.xml')
root = ET.parse(label_path).getroot()
objects = root.findall('object')
for obj in objects:
'''
difficult = obj.find('difficult').text.strip()
if (not use_difficult_bbox) and(int(difficult) == 1):
continue
'''
bbox = obj.find('bndbox')
class_ind = classes.index(obj.find('name').text.lower().strip())
xmin = bbox.find('xmin').text.strip()
xmax = bbox.find('xmax').text.strip()
ymin = bbox.find('ymin').text.strip()
ymax = bbox.find('ymax').text.strip()
annotation += ' ' + ','.join([xmin, ymin, xmax, ymax, str(class_ind)])
print(annotation)
f.write(annotation + "\n")
return len(imagelist)#image_inds
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--data_path", default="/home/wxd/jupyter/FPN_Tensorflow-master/data")
parser.add_argument("--train_annotation", default="./data/dataset/voc_train.txt")
parser.add_argument("--test_annotation", default="./data/dataset/voc_test.txt")
flags = parser.parse_args()
#if os.path.exists(flags.train_annotation):os.remove(flags.train_annotation)
#if os.path.exists(flags.test_annotation):os.remove(flags.test_annotation)
num1 = convert_voc_annotation(os.path.join(flags.data_path, 'VOC_PCB_test'), 'voc_test', flags.train_annotation, False)
#num2 = convert_voc_annotation(os.path.join(flags.data_path, 'train/VOCdevkit/VOC2012'), 'trainval', flags.train_annotation, False)
#num3 = convert_voc_annotation(os.path.join(flags.data_path, 'VOC_PCB_test'), 'test', flags.test_annotation, False)
print('=> The number of image for train is: %d\tThe number of image for train is',num1)# is:%d' %(num1 )+ num2, num3
生成voc_train.txt
line 65处改为
num1 = convert_voc_annotation(os.path.join(flags.data_path, 'VOC_PCB_train'), 'voc_train', flags.train_annotation, False)
进入到项目目录下,执行命令:
python3 scripts/voc_annotation.py
生成voc_test.txt
注意倒数第二个参数为flags.test_annotation
num1 = convert_voc_annotation(os.path.join(flags.data_path, 'VOC_PCB_test'), 'voc_test', flags.test_annotation, False)
train
解压原始权重文件:
cd checkpoint
tar -xvf yolov3_coco.tar.gz
转换权重:
python3 convert_weight.py --train_from_coco
数据集更改后,voc_train.txt和voc_test.txt这两个文件要删掉重新生成!!!
开始训练:
python3 train.py
训练时间较长,,,
训练完一个epoch时的截图
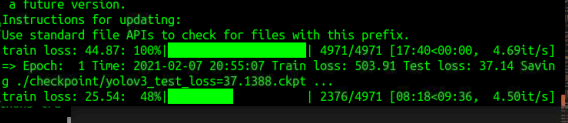
约14个小时,按CTRL + C 停止训练了 ,最终训练了23个epoch,选择第23个保存的模型进行测试,第23个保存的模型截图
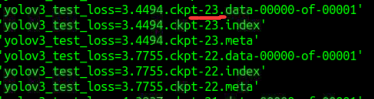
然后在 core/config.py中修改模型的路径:
_C.TEST.WEIGHT_FILE = "./checkpoint/yolov3_test_loss=3.4494.ckpt-23"
项目设置默认保存最新的10个模型,想保存更多,点击
训练一个模型时间较长,建议不要用删除的方式,可以移动到其他路径
自己的数据集图片大小为600*600的,还有哪里要修改?
test
测试时注意查看label是不是自己数据集的:
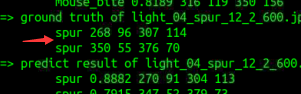
执行下列命令,生成测试报告
eval时间也较长,,,
python3 evaluate.py
cd mAP
python3 main.py -na
然后自动弹出来了mAP图。
__C.TRAIN.FISRT_STAGE_EPOCHS = 20
__C.TRAIN.SECOND_STAGE_EPOCHS = 30
进入第二阶段的epoch,即从epoch=21时开始,损失值较低,

















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









