




 本文探讨了使用Logistic回归和XGBoost在下采样后的Criteo广告点击率预测任务中的表现。通过对比两种模型的精度指标,发现XGBoost在AUC和召回率上显著优于Logistic回归,达到81.5%的高精度。
本文探讨了使用Logistic回归和XGBoost在下采样后的Criteo广告点击率预测任务中的表现。通过对比两种模型的精度指标,发现XGBoost在AUC和召回率上显著优于Logistic回归,达到81.5%的高精度。
SuperCTR
评估指标
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
def eval_model(y_pred, y_true):
print(f"accuracy_score = {accuracy_score(y_true, y_pred)}")
print(f"precision_score = {precision_score(y_true, y_pred)}")
print(f"recall_score = {recall_score(y_true, y_pred)}")
print(f"f1_score = {f1_score(y_true, y_pred)}")
print(f"auc = {roc_auc_score(y_true, y_pred)}")
LR
1.导包
import time
import numpy as np
import pandas as pd
import seaborn as sns
import xgboost as xgb
import matplotlib.pyplot as plt
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
2.导入数据
train_df = pd.read_csv("../input/criteo-dataset/dac/train.txt", sep='\t', names=train_df_cols, nrows=1000000)
train_df.head()
test_df = pd.read_csv("../input/criteo-dataset/dac/test.txt", sep='\t', names=test_df_cols)
数据共40个特征,其中特征连续型的有13个(I1-I13),类别型的26个(C1-C26),一个标签(Label)。
3.对类别型的数据编码
因为只有编码之后才能用于模型的训练
continuous_variable = [f"I{i}" for i in range(1, 14)]
discrete_variable = [f"C{i}" for i in range(1, 27)]
train_df_cols = ["Label"] + continuous_variable + discrete_variable
test_df_cols = continuous_variable + discrete_variable
print(f"train_df has {train_df.shape[0]} rows and {train_df.shape[1]} columns.")
print(f"test_df has {test_df.shape[0]} rows and {test_df.shape[1]} columns.")

将类别型的每一列用factorize方法进行编码,并用均值填补空缺值
for col in train_df.columns:
if train_df[col].dtypes == "object":
train_df[col], uniques = pd.factorize(train_df[col])
train_df[col].fillna(train_df[col].mean(), inplace=True)
train_df.head()
train_df.info()
结果如下,没有空值了。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 40 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Label 1000000 non-null int64
1 I1 1000000 non-null float64
2 I2 1000000 non-null int64
3 I3 1000000 non-null float64
4 I4 1000000 non-null float64
5 I5 1000000 non-null float64
6 I6 1000000 non-null float64
7 I7 1000000 non-null float64
8 I8 1000000 non-null float64
9 I9 1000000 non-null float64
10 I10 1000000 non-null float64
11 I11 1000000 non-null float64
12 I12 1000000 non-null float64
13 I13 1000000 non-null float64
14 C1 1000000 non-null int64
15 C2 1000000 non-null int64
16 C3 1000000 non-null int64
17 C4 1000000 non-null int64
18 C5 1000000 non-null int64
19 C6 1000000 non-null int64
20 C7 1000000 non-null int64
21 C8 1000000 non-null int64
22 C9 1000000 non-null int64
23 C10 1000000 non-null int64
24 C11 1000000 non-null int64
25 C12 1000000 non-null int64
26 C13 1000000 non-null int64
27 C14 1000000 non-null int64
28 C15 1000000 non-null int64
29 C16 1000000 non-null int64
30 C17 1000000 non-null int64
31 C18 1000000 non-null int64
32 C19 1000000 non-null int64
33 C20 1000000 non-null int64
34 C21 1000000 non-null int64
35 C22 1000000 non-null int64
36 C23 1000000 non-null int64
37 C24 1000000 non-null int64
38 C25 1000000 non-null int64
39 C26 1000000 non-null int64
dtypes: float64(12), int64(28)
memory usage: 305.2 MB
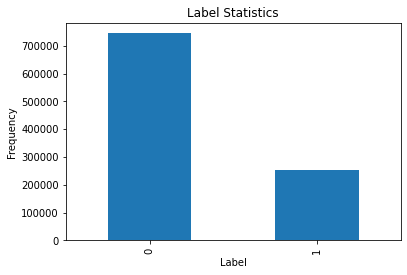
画一下标签的频率直方图(0表示未点击,1表示点击)
count_label = pd.value_counts(train_df["Label"], sort=True)
count_label.plot(kind="bar") # 条形图
plt.title("Label Statistics")
plt.xlabel("Label")
plt.ylabel("Frequency")
算一下具体的正负样本比例
#负样本:正样本 = 2.92:1(scale_pos_weight=2.92)
pd.value_counts(train_df["Label"], sort=True)

下采样
# 下采样
number_of_click = len(train_df[train_df.Label == 1]) # 统计点击的数据量
click_indices = np.array(train_df[train_df.Label == 1].index) # 点击的数据索引
no_click_indices = np.array(train_df[train_df.Label == 0].index) # 正常数据索引
# 在正常数据中随机选择与未点击数据量相等的正常数据的索引
random_no_click_indices = np.array(np.random.choice(no_click_indices, number_of_click, replace=False))
# 将所有点击的数据索引和未点击的等量数据索引合并
under_sample_indices = np.concatenate([click_indices, random_no_click_indices])
# 从原始数据中取出下采样数据集
under_sample_train_df = train_df.iloc[under_sample_indices, :]
X_under_sample = under_sample_train_df.iloc[:, under_sample_train_df.columns != "Label"]
Y_under_sample = under_sample_train_df.iloc[:, under_sample_train_df.columns == "Label"]
# 看一下下采样数据集的长度
print("Total number of under_sample_train_df =", len(under_sample_train_df))
print("Total number of no_click =", len(under_sample_train_df[train_df.Label == 0]))
print("Total number of click =", len(under_sample_train_df[train_df.Label == 1]))
结果如下,正负样本比例已经均衡。
Total number of under_sample_train_df = 509898
Total number of no_click = 254949
Total number of click = 254949
X_under_sample.head()
Y_under_sample
X_under_sample_train,X_under_sample_test,y_under_sample_train,y_under_sample_test = train_test_split(X_under_sample,Y_under_sample,test_size=0.3)
# 对下采样数据进行测试
lr = LogisticRegression(solver="liblinear")
lr.fit(X_under_sample, Y_under_sample)
lr.score(X_under_sample_test, y_under_sample_test)
得到结果:0.6450088252598549
看一下各项评价指标
y_predict_lr = lr.predict(X_under_sample_test)
eval_model(y_predict_lr, y_under_sample_test)

其实效果并不算好,总体才60%多。接下来试试xgboost跑出来的效果。
xgboost
做k折交叉验证
# 下采样后做交叉验证
def kfold_scores(x_train_data, y_train_data):
start_time = time.time()
fold = KFold(3, shuffle=True) # 3折交叉验证
#c_param_range = [0, 0.5, 1] # 惩罚力度,正则化惩罚项的系数
# 做可视化展示
results_table = pd.DataFrame(index=range(2),
columns=["C_parameter", "Mean recall scores", "Mean auc socres"])
index = 0
print('--------------------------------------------------------------------------------')
# 做交叉验证
recall_accs = []
auc_scores = []
# 可以加入scale_pos_weight=2.92参数,如果使用下采样就不加入scale_pos_weight以免互相影响
xgb_model = XGBClassifier(objective="binary:logistic", n_jobs=-1, n_estimators=1000, max_depth=16,
eval_metric="auc",
colsample_bytree=0.8, subsample=0.8, learning_rate=0.2, min_child_weight=6)
for iteration, indices in enumerate(fold.split(x_train_data)):
# 拟合训练数据
# lr.fit(x_train_data.iloc[indices[0], :], y_train_data.iloc[indices[0], :].values.ravel())
xgb_model.fit(x_train_data.iloc[indices[0], :], y_train_data.iloc[indices[0], :].values.ravel(),
eval_metric="logloss",
eval_set=[(x_train_data.iloc[indices[0], :], y_train_data.iloc[indices[0], :]),
(x_train_data.iloc[indices[1], :], y_train_data.iloc[indices[1], :])], verbose=True,
early_stopping_rounds=10)
# 使用验证集得出预测数据
# 最适合的迭代次数,然后预测的时候就使用stop之前训练的树来预测。
print(f"最佳迭代次数为:{xgb_model.best_iteration}")
limit = xgb_model.best_iteration
# y_predicted_undersample = lr.predict(x_train_data.iloc[indices[1], :])
y_predicted_undersample = xgb_model.predict(x_train_data.iloc[indices[1], :], ntree_limit=limit)
# 计算recall
recall_acc = recall_score(y_train_data.iloc[indices[1], :], y_predicted_undersample)
recall_accs.append(recall_acc)
auc_score = roc_auc_score(y_train_data.iloc[indices[1], :], y_predicted_undersample)
auc_scores.append(auc_score)
print('\tIteration ', iteration, ': recall score = ', recall_acc)
print('\tIteration ', iteration, ': auc score = ', auc_score)
index += 1
# 计算recall的平均值
results_table.loc[index, "Mean recall scores"] = np.mean(recall_accs)
results_table.loc[index, "Mean auc scores"] = np.mean(auc_scores)
print('Mean recall score = ', results_table.loc[index, "Mean recall scores"], end="\n\n")
print('Mean auc score = ', results_table.loc[index, "Mean auc scores"], end="\n\n")
print('--------------------------------------------------------------------------------')
return xgb_model
# 对下采样数据进行测试
xgb = kfold_scores(X_under_sample, Y_under_sample)
训练结果如下
--------------------------------------------------------------------------------
[0] validation_0-logloss:0.65029 validation_1-logloss:0.66628
[1] validation_0-logloss:0.61773 validation_1-logloss:0.64819
[2] validation_0-logloss:0.59209 validation_1-logloss:0.63575
[3] validation_0-logloss:0.57027 validation_1-logloss:0.62659
[4] validation_0-logloss:0.55167 validation_1-logloss:0.62060
[5] validation_0-logloss:0.53649 validation_1-logloss:0.61567
[6] validation_0-logloss:0.52190 validation_1-logloss:0.61203
[7] validation_0-logloss:0.50868 validation_1-logloss:0.60933
[8] validation_0-logloss:0.49658 validation_1-logloss:0.60661
[9] validation_0-logloss:0.48651 validation_1-logloss:0.60501
[10] validation_0-logloss:0.47802 validation_1-logloss:0.60350
[11] validation_0-logloss:0.46839 validation_1-logloss:0.60220
[12] validation_0-logloss:0.46043 validation_1-logloss:0.60108
[13] validation_0-logloss:0.45288 validation_1-logloss:0.60091
[14] validation_0-logloss:0.44480 validation_1-logloss:0.60020
[15] validation_0-logloss:0.43958 validation_1-logloss:0.60004
[16] validation_0-logloss:0.43263 validation_1-logloss:0.59916
[17] validation_0-logloss:0.42796 validation_1-logloss:0.59871
[18] validation_0-logloss:0.42143 validation_1-logloss:0.59718
[19] validation_0-logloss:0.41582 validation_1-logloss:0.59657
[20] validation_0-logloss:0.41130 validation_1-logloss:0.59631
[21] validation_0-logloss:0.40725 validation_1-logloss:0.59608
[22] validation_0-logloss:0.40239 validation_1-logloss:0.59571
[23] validation_0-logloss:0.39832 validation_1-logloss:0.59539
[24] validation_0-logloss:0.39447 validation_1-logloss:0.59505
[25] validation_0-logloss:0.39110 validation_1-logloss:0.59487
[26] validation_0-logloss:0.38895 validation_1-logloss:0.59436
[27] validation_0-logloss:0.38441 validation_1-logloss:0.59404
[28] validation_0-logloss:0.38127 validation_1-logloss:0.59416
[29] validation_0-logloss:0.37733 validation_1-logloss:0.59403
[30] validation_0-logloss:0.37380 validation_1-logloss:0.59427
[31] validation_0-logloss:0.37197 validation_1-logloss:0.59412
[32] validation_0-logloss:0.36929 validation_1-logloss:0.59381
[33] validation_0-logloss:0.36792 validation_1-logloss:0.59378
[34] validation_0-logloss:0.36600 validation_1-logloss:0.59374
[35] validation_0-logloss:0.36452 validation_1-logloss:0.59383
[36] validation_0-logloss:0.36155 validation_1-logloss:0.59420
[37] validation_0-logloss:0.35944 validation_1-logloss:0.59413
[38] validation_0-logloss:0.35899 validation_1-logloss:0.59409
[39] validation_0-logloss:0.35702 validation_1-logloss:0.59423
[40] validation_0-logloss:0.35486 validation_1-logloss:0.59396
[41] validation_0-logloss:0.35240 validation_1-logloss:0.59411
[42] validation_0-logloss:0.35000 validation_1-logloss:0.59412
[43] validation_0-logloss:0.34818 validation_1-logloss:0.59408
最佳迭代次数为:34
/opt/conda/lib/python3.7/site-packages/xgboost/core.py:104: UserWarning: ntree_limit is deprecated, use `iteration_range` or model slicing instead.
UserWarning
Iteration 0 : recall score = 0.6809424858239707
Iteration 0 : auc score = 0.6823219983343968
/opt/conda/lib/python3.7/site-packages/xgboost/sklearn.py:1146: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/opt/conda/lib/python3.7/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
[0] validation_0-logloss:0.65061 validation_1-logloss:0.66599
[1] validation_0-logloss:0.61815 validation_1-logloss:0.64769
[2] validation_0-logloss:0.59309 validation_1-logloss:0.63531
[3] validation_0-logloss:0.57095 validation_1-logloss:0.62661
[4] validation_0-logloss:0.55278 validation_1-logloss:0.62015
[5] validation_0-logloss:0.53753 validation_1-logloss:0.61507
[6] validation_0-logloss:0.52324 validation_1-logloss:0.61146
[7] validation_0-logloss:0.51051 validation_1-logloss:0.60895
[8] validation_0-logloss:0.49835 validation_1-logloss:0.60653
[9] validation_0-logloss:0.48860 validation_1-logloss:0.60473
[10] validation_0-logloss:0.47981 validation_1-logloss:0.60401
[11] validation_0-logloss:0.47103 validation_1-logloss:0.60256
[12] validation_0-logloss:0.46264 validation_1-logloss:0.60144
[13] validation_0-logloss:0.45640 validation_1-logloss:0.60092
[14] validation_0-logloss:0.44830 validation_1-logloss:0.60041
[15] validation_0-logloss:0.44047 validation_1-logloss:0.59898
[16] validation_0-logloss:0.43539 validation_1-logloss:0.59905
[17] validation_0-logloss:0.43033 validation_1-logloss:0.59883
[18] validation_0-logloss:0.42509 validation_1-logloss:0.59805
[19] validation_0-logloss:0.41953 validation_1-logloss:0.59732
[20] validation_0-logloss:0.41452 validation_1-logloss:0.59687
[21] validation_0-logloss:0.40779 validation_1-logloss:0.59526
[22] validation_0-logloss:0.40325 validation_1-logloss:0.59515
[23] validation_0-logloss:0.39959 validation_1-logloss:0.59504
[24] validation_0-logloss:0.39437 validation_1-logloss:0.59415
[25] validation_0-logloss:0.39129 validation_1-logloss:0.59403
[26] validation_0-logloss:0.38813 validation_1-logloss:0.59418
[27] validation_0-logloss:0.38452 validation_1-logloss:0.59421
[28] validation_0-logloss:0.38126 validation_1-logloss:0.59379
[29] validation_0-logloss:0.37753 validation_1-logloss:0.59386
[30] validation_0-logloss:0.37584 validation_1-logloss:0.59387
[31] validation_0-logloss:0.37175 validation_1-logloss:0.59363
[32] validation_0-logloss:0.36911 validation_1-logloss:0.59344
[33] validation_0-logloss:0.36628 validation_1-logloss:0.59371
[34] validation_0-logloss:0.36368 validation_1-logloss:0.59380
[35] validation_0-logloss:0.36148 validation_1-logloss:0.59360
[36] validation_0-logloss:0.35812 validation_1-logloss:0.59368
[37] validation_0-logloss:0.35587 validation_1-logloss:0.59382
[38] validation_0-logloss:0.35382 validation_1-logloss:0.59387
[39] validation_0-logloss:0.35260 validation_1-logloss:0.59375
[40] validation_0-logloss:0.35016 validation_1-logloss:0.59354
[41] validation_0-logloss:0.34815 validation_1-logloss:0.59372
最佳迭代次数为:32
/opt/conda/lib/python3.7/site-packages/xgboost/core.py:104: UserWarning: ntree_limit is deprecated, use `iteration_range` or model slicing instead.
UserWarning
Iteration 1 : recall score = 0.6808235901770202
Iteration 1 : auc score = 0.6835137790937945
/opt/conda/lib/python3.7/site-packages/xgboost/sklearn.py:1146: UserWarning: The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. To remove this warning, do the following: 1) Pass option use_label_encoder=False when constructing XGBClassifier object; and 2) Encode your labels (y) as integers starting with 0, i.e. 0, 1, 2, ..., [num_class - 1].
warnings.warn(label_encoder_deprecation_msg, UserWarning)
/opt/conda/lib/python3.7/site-packages/sklearn/utils/validation.py:72: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
return f(**kwargs)
[0] validation_0-logloss:0.65044 validation_1-logloss:0.66610
[1] validation_0-logloss:0.61792 validation_1-logloss:0.64771
[2] validation_0-logloss:0.59264 validation_1-logloss:0.63498
[3] validation_0-logloss:0.57097 validation_1-logloss:0.62585
[4] validation_0-logloss:0.55261 validation_1-logloss:0.61955
[5] validation_0-logloss:0.53678 validation_1-logloss:0.61493
[6] validation_0-logloss:0.52250 validation_1-logloss:0.61141
[7] validation_0-logloss:0.50931 validation_1-logloss:0.60843
[8] validation_0-logloss:0.49780 validation_1-logloss:0.60593
[9] validation_0-logloss:0.48695 validation_1-logloss:0.60404
[10] validation_0-logloss:0.47770 validation_1-logloss:0.60325
[11] validation_0-logloss:0.46977 validation_1-logloss:0.60226
[12] validation_0-logloss:0.46171 validation_1-logloss:0.60099
[13] validation_0-logloss:0.45432 validation_1-logloss:0.60052
[14] validation_0-logloss:0.44628 validation_1-logloss:0.59974
[15] validation_0-logloss:0.43920 validation_1-logloss:0.59892
[16] validation_0-logloss:0.43217 validation_1-logloss:0.59798
[17] validation_0-logloss:0.42623 validation_1-logloss:0.59718
[18] validation_0-logloss:0.41996 validation_1-logloss:0.59606
[19] validation_0-logloss:0.41392 validation_1-logloss:0.59542
[20] validation_0-logloss:0.40929 validation_1-logloss:0.59504
[21] validation_0-logloss:0.40538 validation_1-logloss:0.59497
[22] validation_0-logloss:0.40013 validation_1-logloss:0.59454
[23] validation_0-logloss:0.39680 validation_1-logloss:0.59428
[24] validation_0-logloss:0.39408 validation_1-logloss:0.59417
[25] validation_0-logloss:0.39081 validation_1-logloss:0.59376
[26] validation_0-logloss:0.38750 validation_1-logloss:0.59376
[27] validation_0-logloss:0.38438 validation_1-logloss:0.59282
[28] validation_0-logloss:0.38091 validation_1-logloss:0.59292
[29] validation_0-logloss:0.37594 validation_1-logloss:0.59296
[30] validation_0-logloss:0.37254 validation_1-logloss:0.59232
[31] validation_0-logloss:0.36862 validation_1-logloss:0.59233
[32] validation_0-logloss:0.36653 validation_1-logloss:0.59235
[33] validation_0-logloss:0.36366 validation_1-logloss:0.59235
进行预测
y_predict_xgb = xgb.predict(X_under_sample_test,ntree_limit=xgb.best_iteration)
eval_model(y_predict_xgb, y_under_sample_test)

即
accuracy_score = 0.8150748512780284
precision_score = 0.8165117163425604
recall_score = 0.8132910152423495
f1_score = 0.8148981835313827
auc = 0.8150766723050388
嗯,好,这效果就非常地、大大地好!
n_0-logloss:0.36366 validation_1-logloss:0.59235
进行预测
y_predict_xgb = xgb.predict(X_under_sample_test,ntree_limit=xgb.best_iteration)
eval_model(y_predict_xgb, y_under_sample_test)
即
accuracy_score = 0.8150748512780284
precision_score = 0.8165117163425604
recall_score = 0.8132910152423495
f1_score = 0.8148981835313827
auc = 0.8150766723050388
嗯,好,这效果就非常地、大大地好!


















 8708
8708








 到【灌水乐园】发言
到【灌水乐园】发言









