




 本文详细介绍了Factorization Machines(FM)的工作原理及其在处理稀疏数据方面的优势,并通过实例展示了FM的数学表达和代码实现过程。此外,还探讨了结合深度学习的DeepFM模型如何有效利用FM来挖掘低阶特征,而通过深层神经网络来捕捉高阶特征。
本文详细介绍了Factorization Machines(FM)的工作原理及其在处理稀疏数据方面的优势,并通过实例展示了FM的数学表达和代码实现过程。此外,还探讨了结合深度学习的DeepFM模型如何有效利用FM来挖掘低阶特征,而通过深层神经网络来捕捉高阶特征。
背景
Rendle S. Factorization machines[C]//2010 IEEE International Conference on Data Mining. IEEE, 2010: 995-1000.
FM 原理
W=[143283277208206]{\bf{W}} = \left[ {\begin{matrix}{} {14}&{32}&8\\ {32}&{77}&{20}\\ 8&{20}&6 \end{matrix}} \right]W=143283277208206
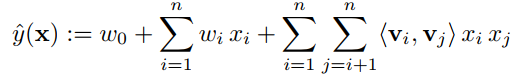

这种写法可以直接用下述代码中的two写法。
#######one#######
X=np.matrix([1,2,3])
V=np.matrix([[1,2,3],[4,5,6],[1,2,1]])
XX=X.T*X
W=V*V.T
#减号后面的部分相当于取W对角线元素与x相乘,numpy的取法.diagonal()
res = np.multiply(XX,W).sum() - np.multiply(sum(np.multiply(V,V).T),np.multiply(X,X)).sum()
print(res)
#######two#######
dataMatrix=np.matrix([1,2,3])
v=np.matrix([[1,2,3],[4,5,6],[1,2,1]])
inter_1 = dataMatrix * v
inter_2 = np.multiply(dataMatrix, dataMatrix) * np.multiply(v, v) #二阶交叉项的计算
interaction = sum(np.multiply(inter_1, inter_1) - inter_2).sum()
print(interaction)
one表示的写法和two表示的写法是一样的。
这里的xix_ixi表示单个一行元素中的一个值。
为什么用FM, 例如豆瓣上有20000部电影,但是小王只看了200部,那么如果对小王所看的电影进行构建一行向量,那么将有很多是0,也就是one-hot编码。所以通过引入隐向量可以进行更少的编码。
数据集描述
https://blog.youkuaiyun.com/weixin_33669611/article/details/112111571
对于上述公式,通过和的形式表现为三项,第一项可以看做为bais(用来防止过拟合),第二项和第一项合起来可以看做一个线性模型,第三项包含了特征与特征之间的关系。
对第三项进行化简,然后得到:
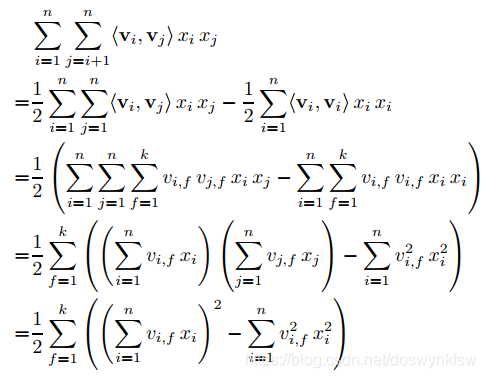
代码实现
- 数据归一化处理
- 初始化偏置,一维向量,二维向量V(n,k)k的维度可以自己设定,这也是为什么使用FM的原因, nnn表示单个样本特征的个数。
- 进行for循环迭代,设置迭代次数
- 在for循环里面计算损失,并依据损失求导计算偏执
参考资料
https://www.cnblogs.com/wkang/p/9588360.html
可以使用的代码:
https://www.jianshu.com/p/610dff83f709
代码实现
https://github.com/ChenaniahMe/codes/tree/main/FM
DeepFM
https://blog.youkuaiyun.com/qq_15111861/article/details/94194240
论文来源:
Guo H, Tang R, Ye Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction[J]. arXiv preprint arXiv:1703.04247, 2017.
算法实现和代码讲解
https://github.com/princewen/tensorflow_practice/blob/master/recommendation/Basic-DeepFM-model/DeepFM-StepByStep.ipynb
实现代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DeepFM(nn.Module):
def __init__(self, field_dims, embed_dim, mlp_dims, dropout):
super(DeepFM, self).__init__()
self.num_fields = len(field_dims)
self.embedding = nn.Embedding(sum(field_dims), embed_dim)
# Initialize FM component
self.linear = nn.Embedding(sum(field_dims), 1)
self.bias = nn.Parameter(torch.zeros((1,)))
# Initialize DNN component
input_dim = self.num_fields * embed_dim
layers = []
for dim in mlp_dims:
layers.append(nn.Linear(input_dim, dim))
layers.append(nn.ReLU())
layers.append(nn.Dropout(dropout))
input_dim = dim
layers.append(nn.Linear(input_dim, 1))
self.mlp = nn.Sequential(*layers)
# Field offsets for embedding lookup
self.offsets = torch.tensor((0, *torch.cumsum(torch.tensor(field_dims[:-1]), dim=0)), dtype=torch.long)
def forward(self, x):
# FM component
x = x + self.offsets.to(x.device)
linear_part = torch.sum(self.linear(x), dim=1) + self.bias
# Embedding lookup
embeddings = self.embedding(x)
# FM interaction term
square_of_sum = torch.sum(embeddings, dim=1) ** 2
sum_of_square = torch.sum(embeddings ** 2, dim=1)
fm_part = 0.5 * torch.sum(square_of_sum - sum_of_square, dim=1, keepdim=True)
# DNN component
dnn_input = embeddings.view(-1, self.num_fields * embeddings.size(2))
dnn_part = self.mlp(dnn_input)
# Final output
output = linear_part + fm_part + dnn_part
return torch.sigmoid(output.squeeze(1))
# Example usage:
# field_dims = [3, 4, 5] # Example field dimensions
# model = DeepFM(field_dims, embed_dim=10, mlp_dims=[32, 16], dropout=0.2)
# x = torch.randint(0, 3, (2, len(field_dims))) # Example input
# output = model(x)
# print(output)
Embedding Layer: 用于将每个特征字段映射到一个密集的向量空间。nn.Embedding用于创建嵌入矩阵。
FM Component:
Linear Term: 使用nn.Embedding来实现线性部分。
Interaction Term: 用于计算特征之间的二阶交互,公式为0.5 * (square_of_sum - sum_of_square)。
DNN Component:
使用多层感知机(MLP)来捕捉高阶特征交互。
nn.Sequential用于堆叠全连接层、激活函数和Dropout。
Forward Method: 将输入数据通过FM组件和DNN组件,最后将结果相加并通过sigmoid激活函数输出。
请根据您的数据集和任务需求调整模型参数和结构。
总结
DeepFM中,FM用来挖掘低阶特征,Deep用来挖掘高阶特征。所谓的低阶特征和高阶特征。

https://blog.youkuaiyun.com/renzhentinghai/article/details/81204169
代码实现
https://github.com/ChenaniahMe/codes/tree/main/DeepFM

















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









