




 本文提出了一种新型网络架构——密集协同注意网络,用于视觉问答(VQA)。核心是密集的共同注意层,通过在视觉和语言表示之间进行双向密集交互来提高答案预测的准确性。网络可以通过堆叠该层执行多步图像问题交互,实现在VQA任务上的出色性能。
本文提出了一种新型网络架构——密集协同注意网络,用于视觉问答(VQA)。核心是密集的共同注意层,通过在视觉和语言表示之间进行双向密集交互来提高答案预测的准确性。网络可以通过堆叠该层执行多步图像问题交互,实现在VQA任务上的出色性能。
读论文:Improved Fusion of Visual and Language Representations by Dense Symmetric Co-Attention for Visual Question Answering
一、概述
本文的贡献是提出了一种注意力机制,可在两种模态之间进行密集的双向交互,以此来提高答案预测的准确性。具体来说,作者提出了一种在视觉和语言表示之间完全对称的体系结构,其中每个问题词都关注图像区域,而每个图像区域都涉及问题词。堆叠形成一个层次结构,用于图像问题对之间的多步交互。
二、网络结构
下图为本文的整体模型,其中使用了堆叠的密集交互注意层(其内部细节在下面再做详细解释),通过对图像和问题的密集交互注意来进行答案预测。

三、相关工作
1.首先对问题和答案进行表征


2.图像表征
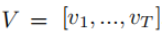
3.密集注意层Dense Co-Attention Layer
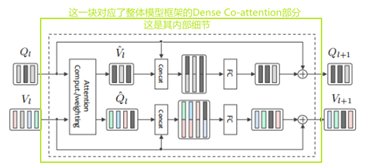
4. 密集共同注意机制Dense Co-attent
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 843
843




 到【灌水乐园】发言
到【灌水乐园】发言







