



 本文详细介绍使用Flume进行日志采集的过程,包括环境搭建、配置文件解析及自定义拦截器实现。通过具体步骤指导如何从日志生成、Flume采集、Kafka中转到最终存储至HDFS。
本文详细介绍使用Flume进行日志采集的过程,包括环境搭建、配置文件解析及自定义拦截器实现。通过具体步骤指导如何从日志生成、Flume采集、Kafka中转到最终存储至HDFS。
准备
zookeeper,flume,kafka安装,详见博客:https://blog.youkuaiyun.com/dontlikerabbit/article/details/112673880
把/opt/software/spark/flume190/lib下的guava-11.0.2.jar删掉
在 /opt下新建applog文件夹,把logmaker-2.0.jar包(需要自己写,带后续上传jar内容)放在下面
执行jar包:
nohup java -jar logmaker-2.0.jar /opt/applog/log >/dev/null 2>&1 &
#停止悬挂 nohup
#日志导向黑洞 >/dev/null
#将异常日志也导向黑洞 2>&1
#后台启动 &
然后/opt/applog下会生成log文件夹,文件夹下生成有sg_app开头的文件,作为后续的flume采集日志的source
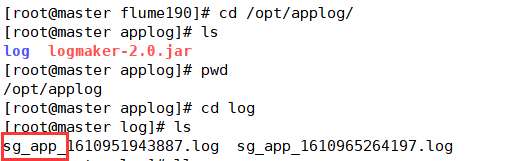
自定义拦截器
pom文件配置
<dependencies>
<!-- flume-ng-core -->
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<!---scope:provided maven打jar包会排除该jar包-->
<scope>provided</scope>
</dependency>
<!-- fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.73</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 指定编译期版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
拦截器的代码:
package cn.kgc.flume.interceptor;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.io.UnsupportedEncodingException;
import java.util.Iterator;
import java.util.List;
public class LogInterceptor implements Interceptor {
@Override
public void initialize() {
}
private boolean isJson(String log){
try {
JSON.parse(log);
return true;
}catch (Exception e){
return false;
}
}
@Override
public Event intercept(Event event) {
try{
String log = new String(event.getBody(),"utf-8") ;
if( isJson(log) ) {
return event;
}
}catch (UnsupportedEncodingException e){
e.printStackTrace();
}
return null;
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> it = list.iterator();
while(it.hasNext()){
if (null== intercept(it.next())) {
it.remove();
}
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
把写好的类打成jar包:
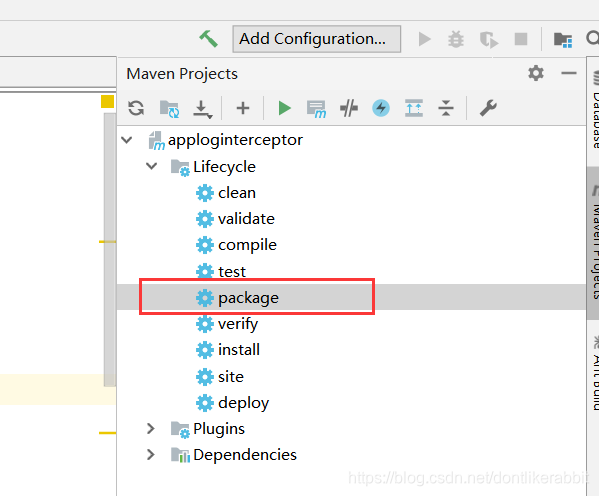
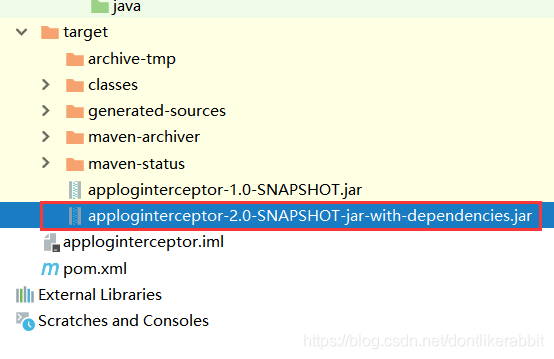
打成jar包存入flume的lib目录下

kafka创建topic
先集群开启zookeeper和kafka的服务
[root@master kafka241]# zkServer.sh start
[root@master kafka241]# bin/kafka-server-start.sh -daemon config/server.properties
创建topic
kafka-topics.sh --zookeeper master:2181/kafka --create --topic sgapp122_log --partitions 3 --replication-factor 2
查看topic
[root@master kafka241]# kafka-topics.sh --zookeeper master:2181/kafka --list
出现了之前创建的topic:sgapp122_log

配置flume
在把/opt/software/spark/flume190下新建文件夹jobs,在jobs下新建文件sgapp_taildir_kafka.conf,并写入:
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type =TAILDIR
#—个组就是一个正则表达式
a1.sources.r1.filegroups =f1
a1.sources.r1.filegroups.f1 = /opt/applog/log/sg_app_.*
#该文件自动生成,无须手动创建
a1.sources.r1.positionFile = /opt/software/spark/flume190/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.kgc.flume.interceptor.LogInterceptor$Builder
#配置Channel Producer or Consumer
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = master:9092,slave03:9092
a1.channels.c1.kafka.topic = sgapp122_log
a1.channels.c1.parseAsFlumeEvent = false
#绑定Source/channel & channel/ sink的关系
a1.sources.r1.channels=c1
启动一台机器作为kafka消费端输出,当flume端没有开启时是没有信息输出的
[root@slave01 spark]# kafka-console-consumer.sh --bootstrap-server master:9092,slave03:9092 --topic sgapp122_log
启动另一台机器作为flume生产者收集日志信息:观察kafka消费端的消息输出
[root@master flume190]# bin/flume-ng agent -n a1 -c conf -f jobs/sgapp_taildir_kafka.conf -Dflume.root.logger=info,console
/opt/software/spark/flume190/jobs下新建文件sgapp-kafka-hdfs.conf
#每个组件命令
a1.sources = r1
a1.channels = c1
a1.sinks = s1
#配置Source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 3000
a1.sources.r1.batchDurationMillis = 60000
a1.sources.r1.kafka.bootstrap.servers = master:9092,slave03:9092,slave01:9092,slave02:9092
a1.sources.r1.kafka.topics = sgapp122_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.kgc.flume.interceptor.TimeStampInterceptor$Builder
#配置Channel Consumer
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/software/spark/flume190/checkpoint/sgact1
a1.channels.c1.dataDirs = /opt/software/spark/flume190/data/sgact1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
#配置Sink
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path = /flume/events/sgapp/%Y-%m-%d
a1.sinks.s1.hdfs.filePrefix = sg-events-
a1.sinks.s1.hdfs.fileSuffix = .log
a1.sinks.s1.hdfs.round = false
#put操作配置
a1.sinks.s1.hdfs.rollInterval = 30
a1.sinks.s1.hdfs.rollSize = 4096
a1.sinks.s1.hdfs.rollCount = 0
#控制文件类型
a1.sinks.s1.hdfs.fileType = CompressedStream
a1.sinks.s1.hdfs.codeC = Lz4Codec
#绑定
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1
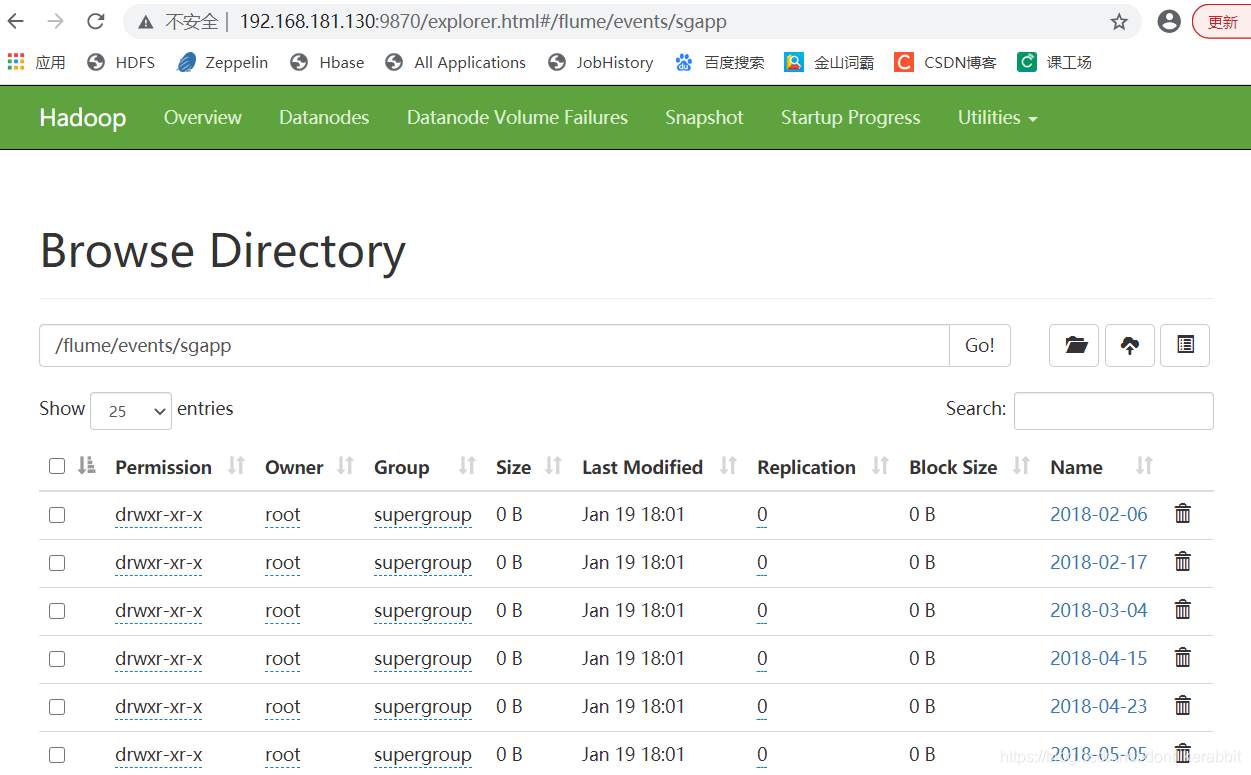
在生产者所在的机器上在HDFS上新建文件路径/flume/events/sgapp
启动一台机器作为flume生产者收集kafka消费端的消息,并输出到HDFS上
[root@master flume190]# bin/flume-ng agent -n a1 -c conf -f jobs/sgapp-kafka-hdfs.conf -Dflume.root.logger=info,console

















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









