




 本文介绍如何手动下载并加载Fashion-MNIST数据集,该数据集包含10类服装图像,用于多类图像分类任务。文章详细说明了数据集的组成、图像特征及标签类型,并提供了图像展示和小批量读取的代码实现。
本文介绍如何手动下载并加载Fashion-MNIST数据集,该数据集包含10类服装图像,用于多类图像分类任务。文章详细说明了数据集的组成、图像特征及标签类型,并提供了图像展示和小批量读取的代码实现。
在介绍softmax回归的实现前我们先引入一个多类图像分类数据集。它将在后面的章节中被多次使用,以方便我们观察比较算法之间在模型精度和计算效率上的区别。图像分类数据集中最常用的是手写数字识别数据集MNIST。但大部分模型在MNIST上的分类精度都超过了95%。为了更直观地观察算法之间的差异,我们将使用一个图像内容更加复杂的数据集Fashion-MNIST。
1.4.1 获取数据集

下面,我们通过Gluon的data包来下载这个数据集。第一次调用时会自动从网上获取数据。我们通过参数train来指定获取训练数据集或测试数据及(testing data set)。测试数据集也叫测试集(testing set),只用来评价模型的表现,并不用来训练模型。
![]()
通过上面的方法,需要先下载数据集。但是本人尝试很多次后,数据集下载不了,因此改用手动下载后再读取数据的方式获取数据。
- 首先从http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz、http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz、http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz、http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz
分别下载压缩数据集:1)训练集 train-images-idx3-ubyte.gz、train-labels-idx1-ubyte.gz;
2)测试集 t10k-images-idx3-ubyte.gz、t10k-labels-idx1-ubyte.gz;
- 接下来按如下方式获取数据


训练集中和测试集中的每个类别的图像数分别为6000和1000。因为有10个类别,所以训练和测试集的样本数分别为6000和1000

我们可以通过方括号[]来访问任意一个样本,下面获取第一个样本的图像和标签。
![]()
变量feature对应高和宽均为28像素的图像。每个像素的数值为0到255之间8位无符号整数(uint8)。它使用三维的NDArray存储。其中的最后一维是通道数。因为数据集中是灰度图像,所以通道数为1。为了表述简洁,我们将高和宽分别为或(h,w)。

图像的标签使用NumPy的标量表示。它的类型为32位整数(int32)。

Fashion-MNIST中一共包括了10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。以下函数可以将数值标签转换成相应的文本标签。

下面定义一个可以在一行里画出多张图像和对应标签的函数。

现在,我们可以看一下训练数据集中前9个样本的图像内容和文本标签。
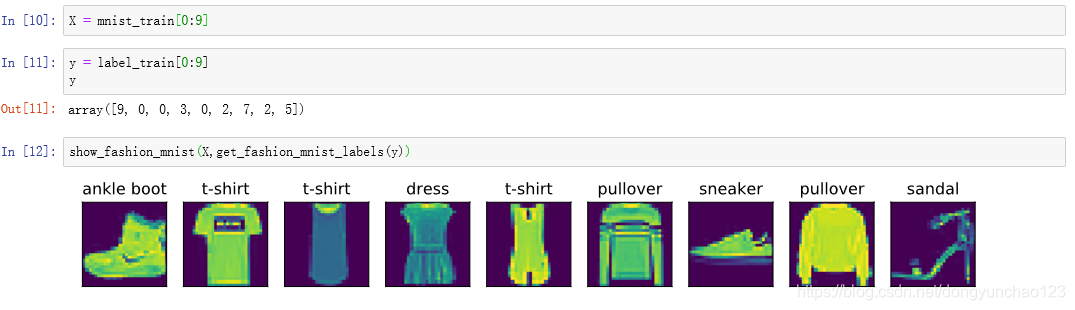
1.4.2 读取小批量
在实践中,数据读取经常是训练的性能瓶颈,特别当模型较简单或者计算硬件性能较高时。Gluon的DataLoader中一个很方便的功能是允许使用多进程来加速数据读取(暂不支持Windows操作系统)。这里我们通过参数num_workers来设置4个进程读取数据。 此外,我们通过ToTensor实例将图像数据从uint8格式变换成32位浮点数格式,并除以255使得所有像素的数值均在0到1之间。ToTensor实例还将图像通道从最后一维移到最前一维来方便之后介绍的卷积神经网络计算。通过数据集的transform_first函数,我们将ToTensor的变换应用在每个数据样本(图像和标签)的第一个元素,即图像之上。

最后我们查看读取一遍训练数据需要的时间。


















 3324
3324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









