 全局内存复用:移除推理模型中的动态内存操作
全局内存复用:移除推理模型中的动态内存操作








 超级会员免费看
超级会员免费看
 本文介绍了如何通过全局内存复用技术优化深度学习模型推理,消除C++实现Resnet50中的动态内存分配。通过预分配3块内存,分别用于输入、输出和残差连接数据,实现了模型中无动态内存申请的目标。优化后,模型的性能在追求极致速度时有所提升。
本文介绍了如何通过全局内存复用技术优化深度学习模型推理,消除C++实现Resnet50中的动态内存分配。通过预分配3块内存,分别用于输入、输出和残差连接数据,实现了模型中无动态内存申请的目标。优化后,模型的性能在追求极致速度时有所提升。
动态申请内存的影响,前两节已经介绍过了,细心的朋友可能会发现,在使用 C++实现的 resnet50 代码中,还存在一处动态申请内存的操作。
那就是对于每一层的输入或输出 feature map 数据进行内存申请,比如在 3rd_preload/ops/conv2d.cc 文件中,卷积的计算中存在对于输出 feature map 的 malloc 行为。
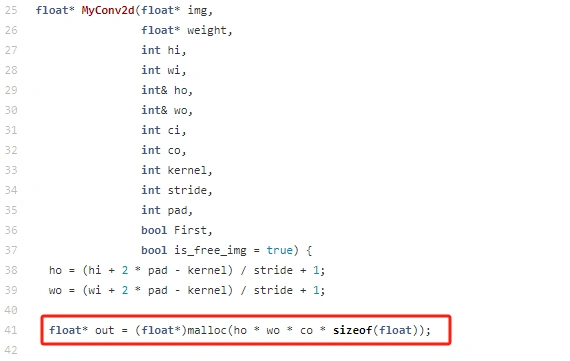
本节就使用一种全局内存复用的方法,来将每一层动态分配内存的操作删除掉,从而使得整个推理模型中,不存在任何动态申请内存的操作。
优化
由于 feature map 的数据有一个特点,那就是上一层的输出是会连接到下一层作为输入。
因此对于一个计算(比如卷积计算)而言,至少要存在两块内存,一个放输入 feature map, 一个放输出 feature map。
而 resnet50 中还存在残差连接,在残差的结构(如下图)中,高速公路的原始输入是会一直驻留,等待左侧F(x)

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2522
2522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











