







 本文介绍使用Python进行数据分析的过程,包括数据读取、操作、处理与分析、结果显示等步骤,并提供了实际案例。涉及pandas、numpy、scipy、matplotlib等多个库。
本文介绍使用Python进行数据分析的过程,包括数据读取、操作、处理与分析、结果显示等步骤,并提供了实际案例。涉及pandas、numpy、scipy、matplotlib等多个库。
目录
本文总结了一下Python数据分析的流程,并梳理了一下所用到的库的框架(就是这个库里大致有哪些模块,这些模块下大致有哪些函数)
1 数据分析流程——Python

通过这pandas、numpy、scipy、matplotlib几个库Pyhton可以替代Matlab进行数据分析。
2 数据读取——pandas
数据读取指的是读取txt、excel等文件里面的数据。采用pandas库里的函数来实现。
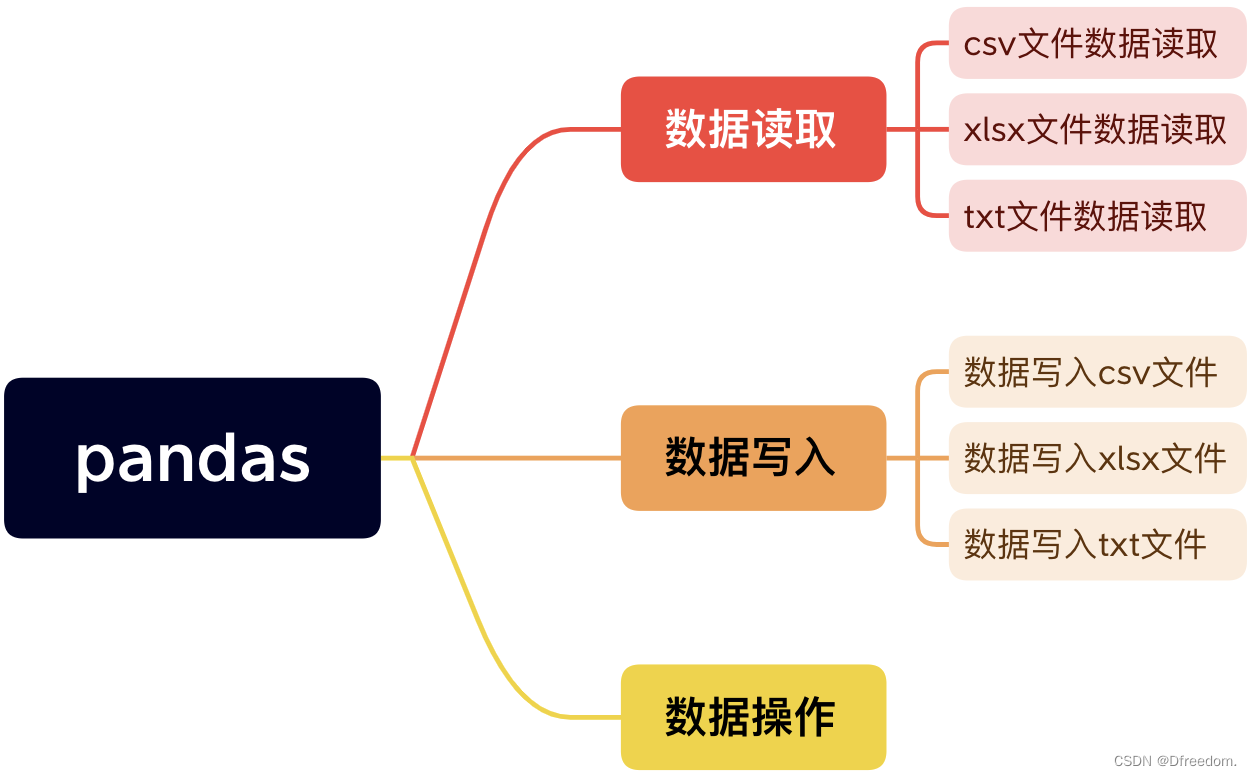
本文主要采用pandas库来读取数据或者写入数据,因此只关注数据读取和写入部分。常用函数如下:
| 函数 | 具体说明 |
| pd.read_excel('path',sheetname,header,names) |
读取xlsx、xls文件 |
| pd.read_csv('path',sheetname,header,names) |
读取csv文件 |
| data = pd.read_table('path', sep = '\t', header , names) |
读取txt文件 |
| data.to_excel( my_new_file.csv , index=None) |
数据写入xlsx、xls文件 |
| data.to_csv( my_new_file.csv , index=None) |
数据写入csv、txt文件 |
函数的详细讲解见:
pandas读取文件_小白学习记录的博客-优快云博客_pandas读取文件
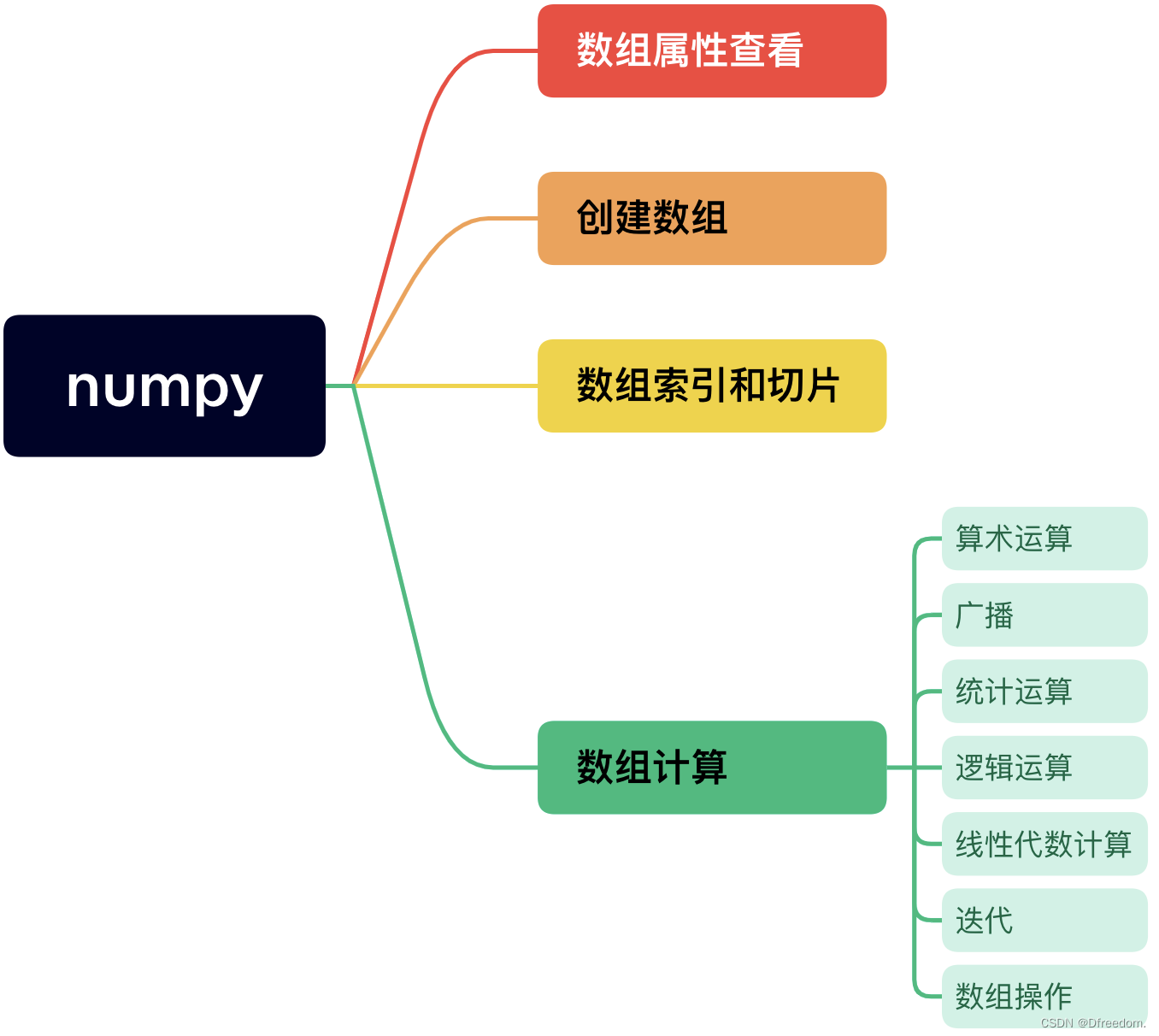
3 数据操作——numpy
读取到的数据在python里面是数组的形式,数据操作实际上就是将读取到的数据(数组)变成【数据处理和分析函数】的输入参数所需要的形式。采用numpy里面的函数实现。
numpy框架图如下:
3.1 数组属性查看
| 属性 | 具体说明 |
| ndarray.ndim | 轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | 数组对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
3.2 创建数组
| 函数 | 具体说明 |
| np.empty() | 创建空数组 |
| np.zeros() | 创建零数组 |
| npones() | 创建1数组 |
| np.eye() | 创建对角矩阵 |
| np.arange() | 根据间隔创建等差数列数组 |
| np.linspace() | 根据元素个数创建等差数列数组 |
| np.logspace() | 创建等比数列数组 |
| np.random.randn() | 创建标准正态分布数组 |
| np.random.normal() | 创建正态分分布数组,可设置均值和标准差 |
| np.random.rand() | 创建在区间[0,1]的均匀分布数组 |
| np.random.uniform() | 创建均匀分布数组,可设置最大值、最小值 |
3.3 数组索引和切片
一维数组切片通用规则如下:
A[i:j]
① A[i]表示索引第i-1个元素;
② 当i不写时,索引第一个元素到第j个元素;
③ 当j不写时,索引第i-1个元素到最后一个元素;
④ 当i和j都不写时,索引全部元素。
二维数组切片通用规则如下:
A[i:j,m:n]
① 当i不写时,索引第一行到第j行;
② 当j不写时,索引第i-1行到最后一行;
③ 当i和j都不写时,索引全部的行;
④ 列的规则和行的规则一样。
详细讲解见:
Python列表、数组切片(索引)_Dfreedom.的博客-优快云博客
3.4 数组计算
3.4.1 算术运算
数组的"+"、"-"、"*"、"/"、"\"、"**"等运算。
3.4.2 广播
当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制,对size小的数组自动进行填补。
3.4.3 统计运算
| 函数 | 具体说明 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











