









通常数据开发的总体流程包括数据产生、数据收集与存储、数据分析与处理、数据提取和数据展现与分享。
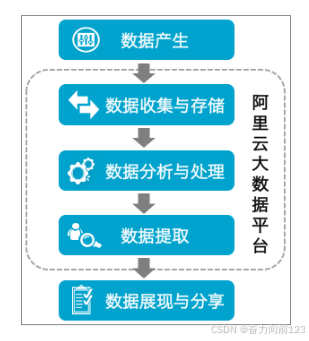
数据开发的流程如下所示:
1.ODS表命名规范:o(ds)_业务板块_源库缩写_源表表名_{全/增量标识}
全量:df 增量:di
注:目前默认全量不加后缀df
Stg增量表:stg_数据库名_源表表名_di
2. ODS建表规范
1) 建表示例
CREATE TABLE if not exists o_upc_dim_ye_df (
caiwuyear bigint comment '财务年',
y_wkm bigint comment '财务年',
y_from_dt datetime comment '财务年',
w_from_dt datetime comment '财务年',
w_end_dt datetime comment '财务年',
y_end_dt datetime comment '财务年',
yoy_caiwuyear bigint comment '财务年',
yoy_y_wkm bigint comment '财务年',
yoy_y_from_dt datetime comment '财务年',
yoy_w_from_dt datetime comment '财务年',
yoy_w_end_dt datetime comment '财务年',
yoy_y_end_dt datetime comment '财务年'
)
Comment 'year财务表'
PARTITIONED BY (dt STRING COMMENT 'yyyymmdd');
2)ods表存储类型
| 数据表类型 | 数据范围描述 | 存储方式 | 生命周期管理(默认) |
|---|---|---|---|
| Ods全量表 | 从历史到当天所有的数据 | 按天存放从历史到当天所有的数据 | 999 |
| ODS增量表 | 按时间戳天存放的增量数据 | 按天存放流水时间戳的数据 | 无 |
| Stg增量表 | 抽取增量变动的数据 | 30 | |
3)关系型数据库与odps数据类型同步对应参考
| SQL SERVER数据类型 | Maxcomputor数据类型 |
|---|---|
| char/varchar/nchar/nvarchar | String |
| Int/smallint/tinyint/bigint | Bigint |
| decimal(m,n) | decimal(38,5) |
| Decimal/float | double |
| MYSQL数据类型 | Maxcomputor数据类型 |
|---|---|
| char/varchar/boolean | string |
| int/smallint/tinyint/bigint | bigint |
| decimal(m,n) | decimal(38,5) |
| datetime | datetime |
3. ODS数据同步规范
1)命名规范 :表名
2)重跑次数 : 默认设置3,间隔2分钟
3) 生成实例方式 :T+1 次日生成
4)第一优先选择源表
4. ods源数据库同步方式
1)全量同步
2)全量同步+增量合并
增量数据放在stg_开头的表中
3)纯增量数据的同步
5. 其他同步方式
数据库日志binlog同步方式
6. ods抽取数据脱敏规范
ods敏感信息采用数据脱敏方式处理
ods一律不抽取敏感数据到数据平台
- 数据产生:业务系统每天会产生大量结构化的数据,存储在业务系统所对应的数据库中,包括MySQL、Oracle和RDS等类型。
- 数据收集与存储:您需要同步不同业务系统的数据至MaxCompute中,方可通过MaxCompute的海量数据存储与处理能力分析已有的数据。
DataWorks提供数据集成服务,可以支持多种数据源类型,根据预设的调度周期同步业务系统的数据至MaxCompute。
- 数据分析与处理:完成数据的同步后,可以对MaxCompute中的数据进行加工(MaxCompute SQL、MaxCompute MR)、分析与挖掘(数据分析、数据挖掘)等处理,从而发现其价值。
- 数据提取:分析与处理后的结果数据,需要同步导出至业务系统,以供业务人员使用其分析的价值。
- 数据展现与分享:数据提取成功后,可以通过报表、地理信息系统等多种展现方式,展示与分享大数据分析、处理后的成果。
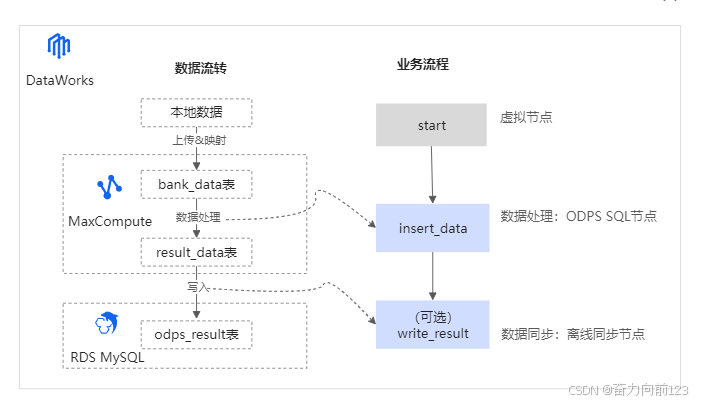
- 模型架构层次划分:
-
分大三层:
- 操作贴源数据层(分为stg和ods)
- 数据仓库层 (分为dwd+dws)
- 应用数据层(分为dm+st)
- 操作数据层:Operational Data Store,操作数据层,在结构上其与源系统的增量或者全量数据基本保持一致。它相当于一个数据准备区,同时又承担着基础数据的记录以及历史变化。其主要作用是把基础数据引入到MaxCompute。
Stg:缓冲层,抽取增量数据或者原始敏感数据存放区
Ods:存放最终脱敏后的数据或者经增量合并后的最终数据 - DW:DataWare house,数据仓库中间层,又细分为DWD和DWS。它的主要作用是完成数据加工与整合、建立一致性的维度、构建可复用的面向分析和统计的明细事实表以及汇总公共粒度的指标。
DWD:Data Warehouse Detail,明细数据层。
DWS:Data Warehouse Summary,轻度汇总数据层。 - ADS:Application Data Service,应用数据层。可以细分为st、dm等层次
DM : 数据集市层,为cube准备的表
ST : 报表应用层表,单一数据应用表
三、公共规范
1. 层次调用规范
1) Ods层数数据只能被dw层的dwd调用
2)DWD只允许调用ods层的数据
3)Dws 只允许调用dwd层的数据,原则上dw层的数据不允许相互调用
4)Ads 应用层的数据可以调用DWS,DWD的数据,不允许直接访问ods的数据
2. 除特殊维表外,所有的表都需要用分区表
3. 字段命名规范:使用英文、下划线、小写、数字、避免使用拼音
4. 分区字段规范:
按天分区(yyyymmdd):dt
小时分区(hh): ht
月分区(yyyymm):mt
周分区(yyyyww): wt
天小时分区(yyyymmddhh):dht
5. Maxcomputor数据类型规范
Bigint
Datetime
String
Decimal(38,5)
Double
timestamp
Date 使用string代替
四、数据同步规范
2. 数据模型构建步骤
1)数仓规划(业务域板块划分)
2)数据规范定义
以业务视角进行数据统一和标准定义,确保计算的口径一致,算法一致,命名规范且统一的实现: 以维度建模作为理论基础,构建总线矩阵,划分和定义数据域、业务过程、维度、度量/院子指标、修饰类型、修饰词、时间指标、派生指标
3)指标规范定义
区分业务过程、原子指标、维度,构建总线矩阵
数据模型建设定义
a. 事实表设计
1)事务型事实表 (dwd)
2)轻度汇总事实表 (dws)
3)数仓表命名规范
dwd_业务板块_数据域_自定义_全量/增量
dws_业务板块_数据域_自定义_全量/增量
b. 维度表设计
数据开发规范(dataworks)
解决方案为可选,可以由多个业务过程自动组成解决方
1.业务流程命名规范
- 业务流程规范
业务流程按照业务板块、数据架构层次划分,即按照ODS、DW、ADS划分
业务板块_层次_数据域
例1:ods_iedu_edus
例2:dw_iedu_class ,数据域较少情况下可以合并,如dw_iedu_class
3. 脚本规范
INSERT OVERWRITE TABLE dwd_iedu_agr_contract PARTITION(dt='${bizdate}')
SELECT order_form_id AS contract_id
,pk_school AS stu_dept_id
,pk_stu AS student_id
,create_date AS src_cre_dtm
,update_date AS src_upd_dtm
,zd_of_type AS contract_kind
,start_date AS contract_start_dt
,end_date AS contract_end_dt
,all_money AS contract_amt_total
,must_pay_money AS contract_amt_real
,STATUS AS contract_sta
,pk_result_type AS contract_type
,pk_organ_school_1 AS contract_dept_id
,new_all_money_time AS feeall_dt
FROM o_iedu_order_form
WHERE dt = '${bizdate}';
4. 时间戳字段规范
dw建表需要加时间戳upd_dtm
5.临时表规范
临时表用完后,删除7天以前的临时表
6.严禁使用视图
7.表和字段必须有注释
8.数据量较大的表,需要设置生命周期
9.脚本需要考虑可以多次跑的
七、调度规范 - 调度时间设置:根据各业务数据库时间戳相应的结束时间统一设置
- 业务流程与业务流程之间的task可以相互依赖
-
- 方法 1)数据模型层命名:业务名_层次名 如upc_dw层次名枚举:ods、dw、ads
- 方法 2)ads_自定义 ads: 应用层 如dm_salar全部小写
- 除ods层及第一层外,必须要有依赖,禁止估算
- 出错重跑和间隔设置
Ods: 3次+ 2分钟间隔
DW/ADS : 2次+ 2分钟
八、命名规范



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











