







在机器学习中,降维是一种至关重要的技术,它能够帮助我们降低数据的维度,从而更好地理解和分析数据。随着技术的发展,智能写作工具如百度智能云文心快码(Comate)也为撰写这类技术文档提供了极大的便利。本文将详细介绍四种常用的降维方法:主成分分析(PCA)、线性判别分析(LDA)、潜在语义分析(LSA)和t-分布邻域嵌入算法(t-SNE)。
一、主成分分析(PCA)
PCA是最常用的线性降维方法之一。它的核心目标是找到一个低维度的表示,同时尽可能保留原始数据中的方差。PCA通过将数据投影到一个低维空间来实现降维,这一投影过程依赖于一个正交矩阵,该矩阵能够最大化投影数据的方差。PCA在数据压缩、特征提取和可视化等领域有着广泛的应用。
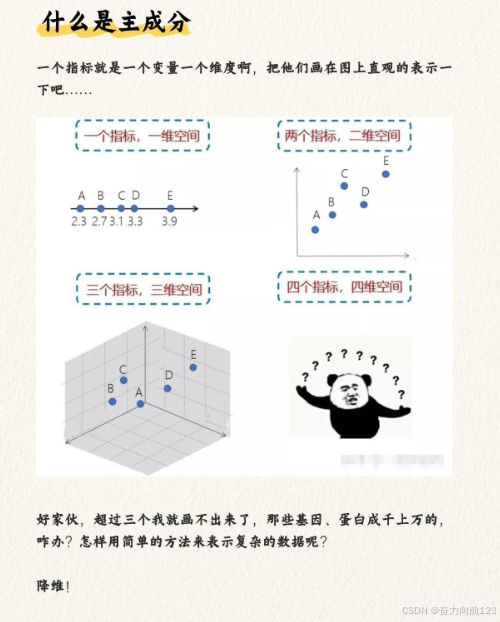

PCA的步骤如下:
- 标准化数据:将数据标准化为均值为0,标准差为1的分布。
- 计算协方差矩阵:基于标准化后的数据集,计算其协方差矩阵。
- 计算特征值和特征向量:求解协方差矩阵的特征值和特征向量。
- 选择主成分:选取前k个最大的特征值对应的特征向量,作为降维后的数据基础。
- 投影数据:将原始数据投影到这些选定的特征向量上,得到降维后的数据。
二、线性判别分析(LDA)
LDA是一种监督学习的降维方法,其目标在于找到一个低维度的表示,使得同类别的数据点尽可能接近,而不同类别的数据点尽可能远离。LDA在分类问题中,尤其是特征维度较高时,具有显著的优势。
线性判别分析是一种经典的线性学习方法,在二分类问题上最早由Fisher在1936年提出,亦称Fisher线性判别。线性判别的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异样样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别。 [2]
LDA与方差分析(ANOVA)和回归分析紧密相关,这两种分析方法也试图通过一些特征或测量值的线性组合来表示一个因变量。然而,方差分析使用类别自变量和连续数因变量,而判别分析连续自变量和类别因变量(即类标签)。逻辑回归和概率回归比方差分析更类似于LDA,因为他们也是用连续自变量来解释类别因变量的。
LDA的基本假设是自变量是正态分布的,当这一假设无法满足时,在实际应用中更倾向于用上述的其他方法。LDA也与主成分分析(PCA)和因子分析紧密相关,它们都在寻找最佳解释数据的变量线性组合。LDA明确的尝试为数据类之间不同建立模型。 另一方面,PCA不考虑类的任何不同,因子分析是根据不同点而不是相同点来建立特征组合。判别的分析不同因子分析还在于,它不是一个相互依存技术:即必须区分出自变量和因变量(也称为准则变量)的不同。在对自变量每一次观察测量值都是连续量的时候,LDA能有效的起作用。当处理类别自变量时,与LDA相对应的技术称为判别反应分析。
LDA的步骤如下:
(继续步骤编号,从LDA开始)
- 标准化数据:同样,将数据标准化为均值为0,标准差为1的分布。
- 计算类内散度矩阵:计算每个类别的均值向量和协方差矩阵。
- 计算类间散度矩阵:评估不同类别均值向量之间的差异。
- 计算判别式矩阵:结合类内散度矩阵和类间散度矩阵,形成判别式矩阵。
- 计算特征值和特征向量:求解判别式矩阵的特征值和特征向量。
- 选择主成分:选取前k个最大的特征值对应的特征向量。
- 投影数据:将原始数据投影到这些选定的特征向量上。
三、潜在语义分析(LSA)
LSA是一种基于矩阵分解的降维方法,旨在找到一个低维度的表示,同时保留原始数据中的语义信息。LSA在文本挖掘和信息检索等领域有着广泛的应用。
LSA的步骤如下:
(继续步骤编号)
- 构建文档-词矩阵:将文档集合表示为词袋模型的向量形式,形成矩阵。
- 对角线化矩阵:对文档-词矩阵进行奇异值分解(SVD)。
- 降维处理:选取对角线矩阵中前k个最大的奇异值对应的奇异向量。
- 投影数据:将原始的文档-词矩阵投影到这些选定的奇异向量上。
四、t-分布邻域嵌入算法(t-SNE)
t-SNE是一种非线性降维方法,其目标在于找到一个低维度的表示,同时保留原始数据中的局部结构和非线性关系。t-SNE在高维数据的可视化方面表现出色。
t-SNE的步骤如下:
(继续步骤编号)
- 初始化:在低维空间中随机初始化点。
- 计算概率:为原始数据中的每个点计算其与低维空间中其他点的概率分布。
- 更新坐标:根据概率分布更新低维空间中点的坐标。
- 迭代优化:重复步骤18和19,直至达到收敛条件。
- 可视化结果:将低维空间中的点进行可视化,展示数据的低维表示。


















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











