 Android侧tokenizer的实现与封装
Android侧tokenizer的实现与封装




Android侧对tokenizer的实现
引言
- 背景介绍:最近一直在专注于解决端侧大模型的构建,发现端侧的大模型处理绕不开的一个核心点就是tokenizer。
- 我们在对模型进行包装构建端侧可用的结构(如onnx、tflite、qnn等)时通常采取以下方式,我们发现主要的输入为input_ids、attention_mask、position_ids。其中attention_mask和position_ids相对很好构建,其中最主要核心input_ids就是tokenizer构建出的文本ID集合。
class ModelWrapper(torch.nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, input_ids, attention_mask, position_ids):
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
use_cache=True,
return_dict=True
)
return outputs.logits
一、tokenizer基础概念
Tokenizer(分词器)是将文本拆分为更小单元(如单词、子词或字符)的工具,是自然语言处理(NLP)任务的基础组件。其核心目标是将原始文本转换为模型可处理的数值形式。
主要功能
-
文本拆分
将句子或段落拆分为词、子词或字符,例如:- 英文分词结果:
"Hello world"→["Hello", "world"] - 中文分词结果:
"你好世界"→["你好", "世界"]
- 英文分词结果:
-
词汇表映射
为每个词汇单元分配唯一ID,构建词汇表(Vocabulary)。例如:{"hello": 1, "world": 2, "<unk>": 0} -
特殊标记处理
添加预定义的符号(如[CLS]、[SEP]),用于模型控制或句子边界标识。
常见类型
- 词级别(Word-based)
以空格或语言规则分割单词,但难以处理未登录词(OOV)。 - 子词级别(Subword-based)
通过算法(如BPE、WordPiece)将单词拆分为更小子单元,平衡词汇表大小与OOV问题。 - 字符级别(Character-based)
按字符分割,词汇表极小但序列长度显著增加。
典型流程
-
标准化(Normalization)
统一大小写、去除无效字符、Unicode规范化等。 -
预分词(Pre-tokenization)
按空格或标点初步拆分文本,生成候选单元。 -
分词算法应用
调用BPE、WordPiece等算法进一步处理,生成最终分词结果。 -
编码与解码
- 编码:文本 → Token ID序列
- 解码:Token ID序列 → 文本
代码示例
from transformers import AutoTokenizer
# 加载预训练分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# 编码文本
text = "Hello, world!"
encoded = tokenizer(text, return_tensors="pt")
print(encoded.input_ids) # 输出:tensor([[ 101, 7592, 1010, 2088, 999, 102]])
# 解码
decoded = tokenizer.decode(encoded.input_ids[0])
print(decoded) # 输出:"[CLS] hello, world! [SEP]"
二、Android平台上的Tokenizer实现封装
static {
System.loadLibrary("android_tokenizer");
}
方式一
利用vocab.json(词表文件)和merges.txt(合并文件),底层采用BPE分词算法,分词前会先根据空格进行预分词,然后根据词表进行分词。(PS:适用于采用BPE算法分词的模型,如clip)
handle = nativeCreate(vocabPath, mergesPath);
Log.d(TAG, "Tokenizer: handle= " + handle);
if (handle == 0) {
Log.d(TAG, "Tokenizer: Failed to create tokenizer");
}
方式二
直接加载模型的tokenizer.json文件(PS:适用于LLM,如qwen、deepseek、llama等)
接口描述
提供了两个核心功能
- Tokenizer.java(主要用于tokenizer相关功能的处理)
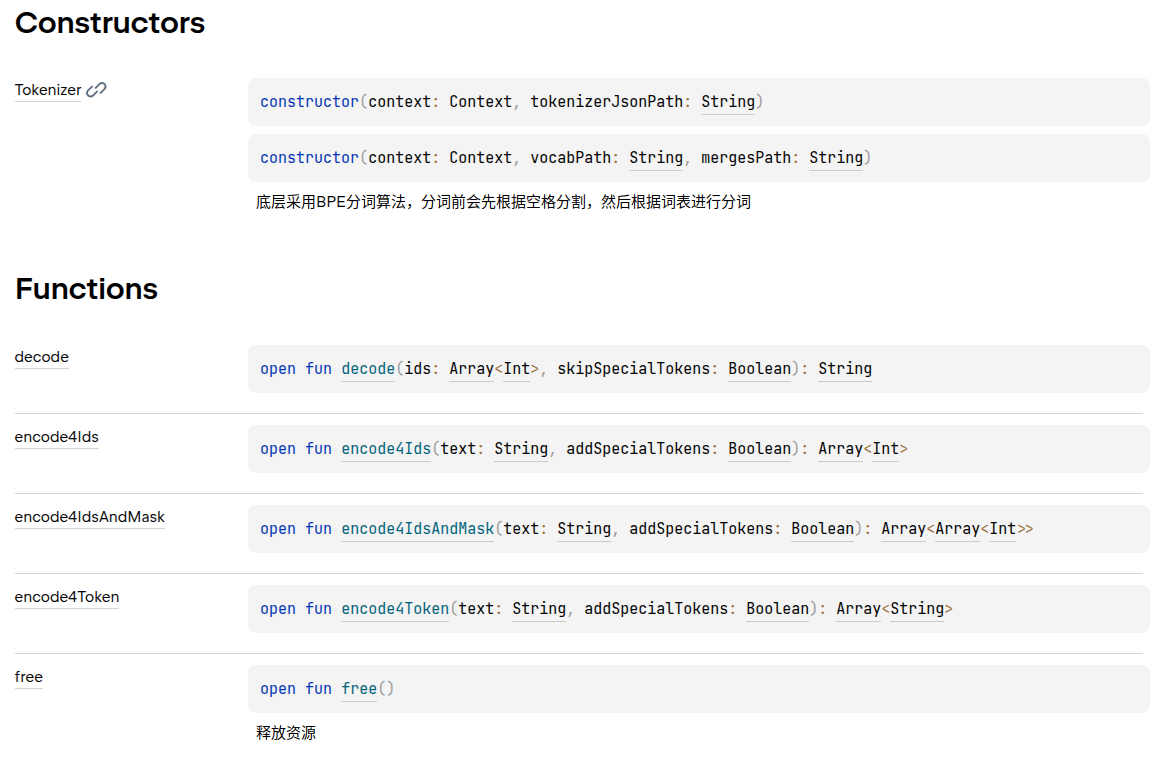
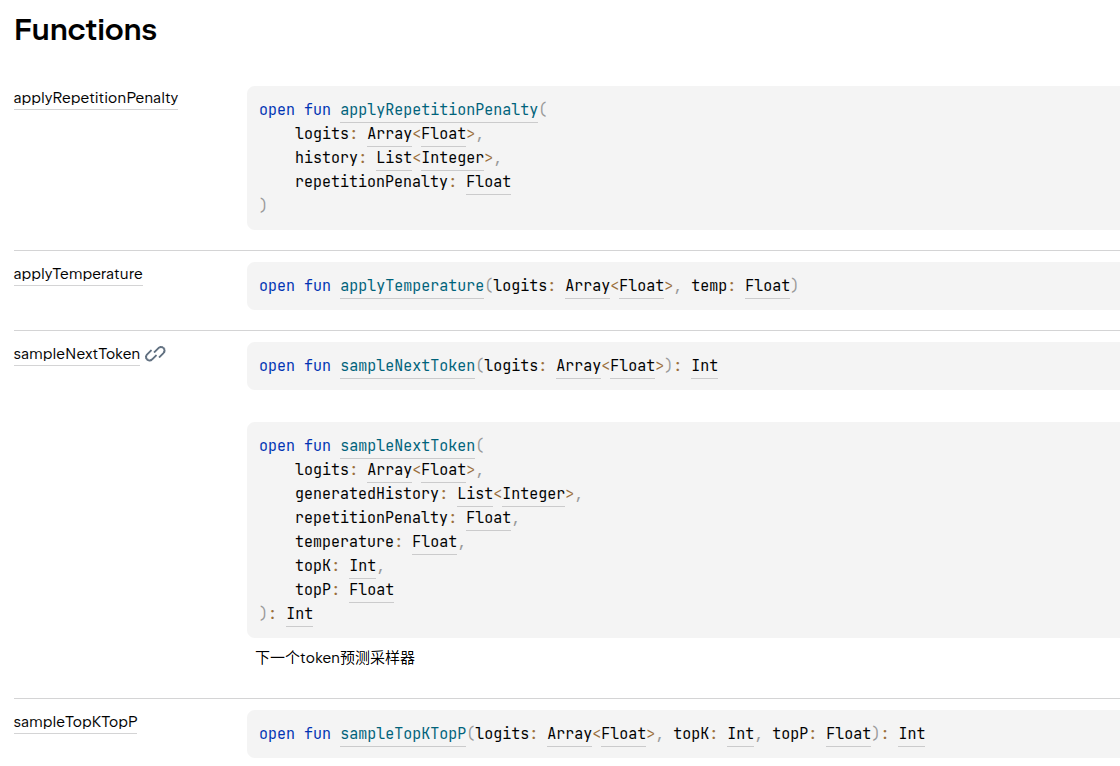
- TokenSampler.java(主要用于对模型生成的logits进行采样处理,取值对应模型的generation_config.json)
- 重复惩罚
- 温度控制
- top-k&top-p采样
示例(qwen2.5-1.5B onnx端侧推理)
模型转换时采用kv缓存,每步推理无需输入每层的kv张量


















 1460
1460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









