



Transformer 通俗直白理解
我对于transformer的理解,他可以处理很长的一组输入向量,能够捕获各元素之间的关系,能够看到全局信息,可以实现从每一个细节逐步捕获到全局特征。为什么transformer 能够做到,而RNN和CNN 无法做到,RNN循环神经网络,每个元素的计算结果会传递给下一个元素,计算是串行的,计算效率低,并且随着信息的增加会遗忘之前的信息,造成模型性能下降。CNN 他的滑动窗口是有限的,模型只能都学习到当前元素和周围元素之间的关系,距离位置太远的关系基本无法学习到的。考虑到这一点,于是transformer 出现了,它提出了注意力机制的概念,对于输入的信息他会学习分析每一个元素之间的关系。这样做到不漏掉任何细节,能够捕捉到任意关系,为大模型的出现奠定了基础。那具体是怎样实现的那?
Transformer 算法原理
算法流程
整个算法流程如图所示,首先对输入向量进行向量化并且向量当中保留位置信息,然后经过多头注意力机制、归一化、前向网络、归一化,完成输入数据的编码,这个模块有NX组,随后,对输出向量进行类似的操作,最有将输入和输出经过交叉注意力机制,前向神经网络归一化等操作,输出一个置信度分数。
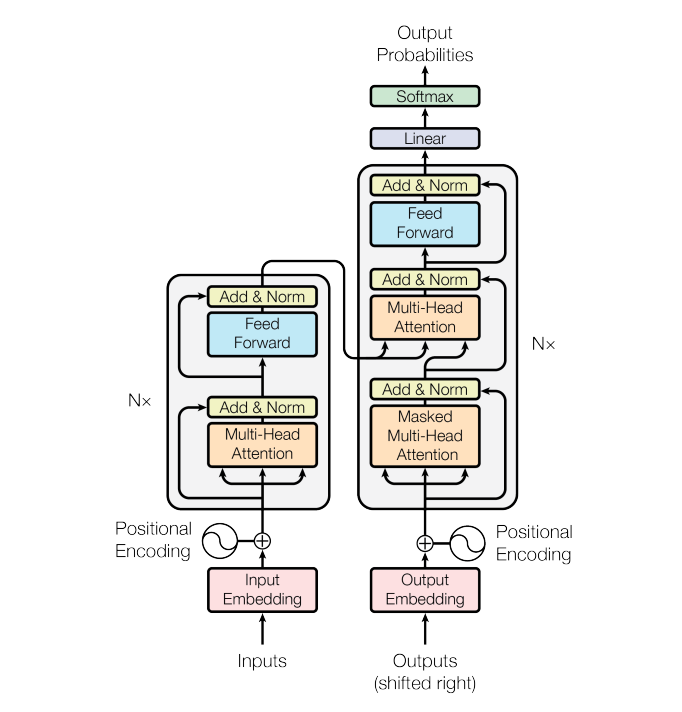
算法结构
自注意力机制
对于每一个输入语句,首先进行单词分割,将每一个单词进行向量化处理,随后逐词分析每一个单词和其他单词之前的关系。最后,在每一个单词的位置,生成和其他单词关系的语义信息。使得单词的信息不再孤立。
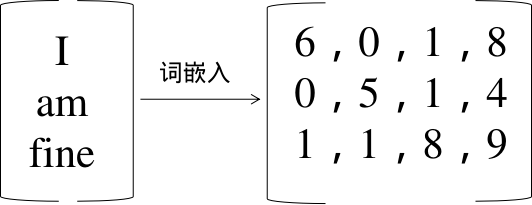
通过举例说明:I am fine 自注意力机制的形成。
首先对I am fine语句进行分词
x1 代表 I,x2代表 am ,x3 代表fine。
在这儿引入三个矩阵分别是Q、K、V。
Q代表查询 ,比如 I和am 的关系是什么?
K代表键,比如第一个位置和第二个位置的数据的关系是什么?
V代表值,比如第一个位置和第二个位置的数据的关系的数值。
随后进行注意力分数的计算
输入向量 I q1=x1*wq1 k1=x1*wk1 v1=x1*wv1
输入向量 am q2=x2*wq2 k2=x2*wk2 v2=x2*wv2
输入向量 fine q3= x3*wq3 k3=x3*wk3 v3=x3*wv3
q1*k1 代表 I和I之间的关系,q1*k2代表I和am 之间的关系,q1*k3 代表 1 和 fine 之间的关系。
即:score 1,1=q1*k1 score1,2=q1*k2 score1,3=q1*k3
计算出来的数值为了稳定梯度,需要进行点积缩放 ,我们将分数除以 Key 向量维度的平方根,随后对分数应用softmax,将权重系数压缩到0~1之间。
最后加权求和
y1 = weight1*v1+weight2*v2+weight3*v3。y2和y3 计算方法相同,在此就不再赘述了。
y1 相比与 x1 不再简单的代表I的语义信息的向量,而是考虑到各单词之间的关系的向量。
计算方式是通过矩阵运算实现,提高了执行效率
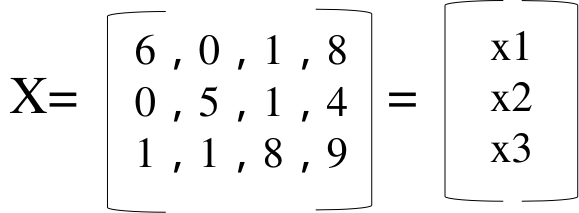
在这儿引入三个矩阵分别是Q、K、V。
Q阵代表查询 ,比如 I和am 的关系是什么?
K阵代表关键字,比如第一个位置和第二个位置的数据的关系是什么?
V阵代表分数,比如第一个位置和第二个位置的数据的关系的数值。
计算步骤,首先让输入和Q,K,V三个矩阵分别相乘
随后带入公式
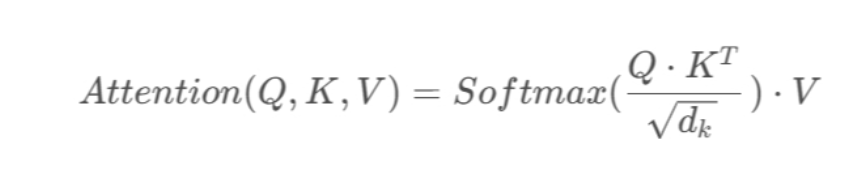
其中,dk 代表输入数据的维度,本例等于3, 应用softmax,将系数归一化到0到1之间。最后乘以V矩阵,得到最后的输出。得到的输出是考虑到和所有单词的关系。
多头自注意力机制
输入多组 Wq、Wk、Wv矩阵进行并行计算,将计算结果进行拼接,最后通过一个线性层进行融合。针对不同的注意力机制产生不同的关注点,能够更加全面的捕获语义关联。
mask multi head attention
通过加入掩码机制,可以使得模型在计算时可以屏蔽不关注的信息。比如在语句生成过程当中,当前生成的单词只需分析当前位置和之前位置的语义关系。Q,K,V 参数矩阵是下三角矩阵。
编解码器注意力机制 encode-decoder
编码器的输出为 K,V矩阵,解码器的输出作为 Q 矩阵。通过多头注意力计算目标序列和输入序列的注意力得分,生成加权表示。
下一篇讲述在CV 领域里面的应用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









