



 本文深入解析了Spark中reduceByKey操作符的功能与实现原理。通过一个wordcount实例,演示了如何使用reduceByKey对相同键的值进行聚合计算。reduceByKey利用hash-based shuffle机制,将相同键的值发送到同一个reducer,通过用户自定义的reduce函数进行合并。
本文深入解析了Spark中reduceByKey操作符的功能与实现原理。通过一个wordcount实例,演示了如何使用reduceByKey对相同键的值进行聚合计算。reduceByKey利用hash-based shuffle机制,将相同键的值发送到同一个reducer,通过用户自定义的reduce函数进行合并。
一、reduceByKey作用
reduceByKey将RDD中所有K,V对中,K值相同的V进行合并,而这个合并,仅仅根据用户传入的函数来进行,下面是wordcount的例子。
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class WordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("spark WordCount!").setMaster("local[*]");
JavaSparkContext javaSparkContext = new JavaSparkContext(conf);
List<Tuple2<String, Integer>> list = Arrays.asList(new Tuple2<String, Integer>("hello", 1),
new Tuple2<String, Integer>("word", 1), new Tuple2<String, Integer>("hello", 1),
new Tuple2<String, Integer>("simple", 1));
JavaPairRDD<String, Integer> listRDD = javaSparkContext.parallelizePairs(list);
/**
* spark的shuffle是hash-based的,也就是reduceByKey算子的两个入参一个是来源于hashmap,一个来源于从map端拉取的数据,对于wordcount例子而言,进行如下运行
* hashMap.get(Key)+ Value,计算结果重新put回hashmap,循环往复,就迭代出了最后结果
*/
JavaPairRDD<String, Integer> wordCountPair = listRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordCountPair.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println(tuple._1 + ":" + tuple._2);
}
});
}
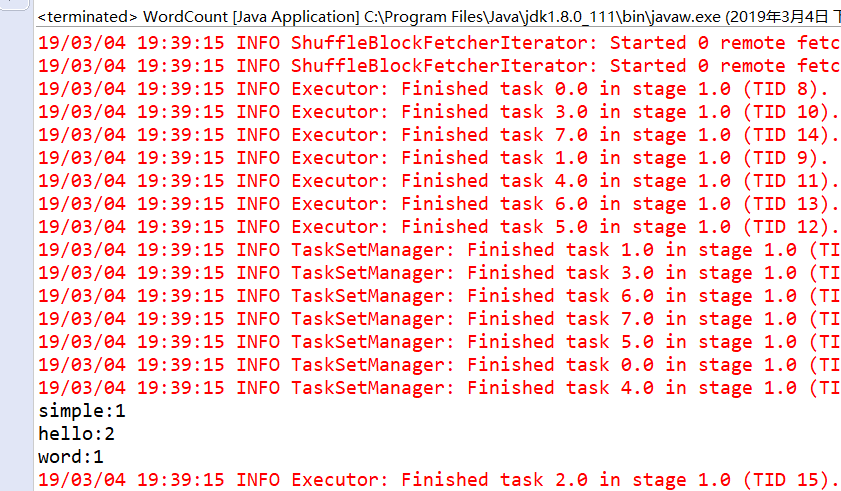
}计算结果:
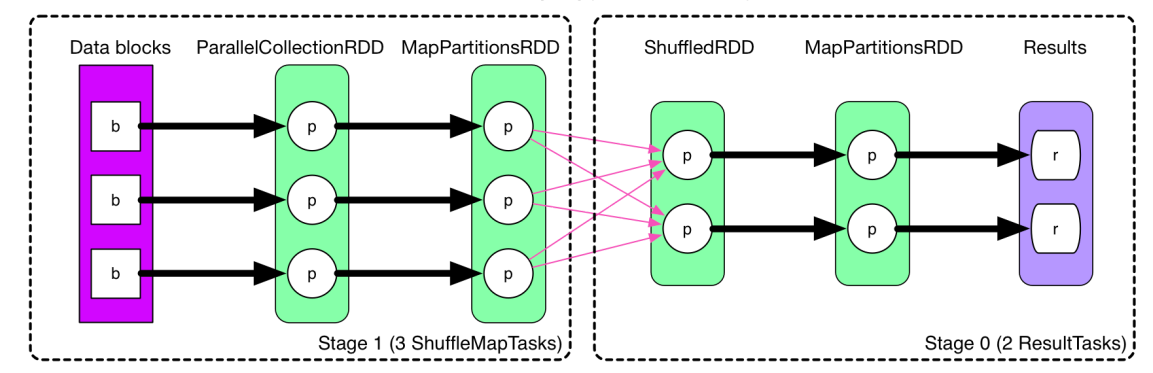
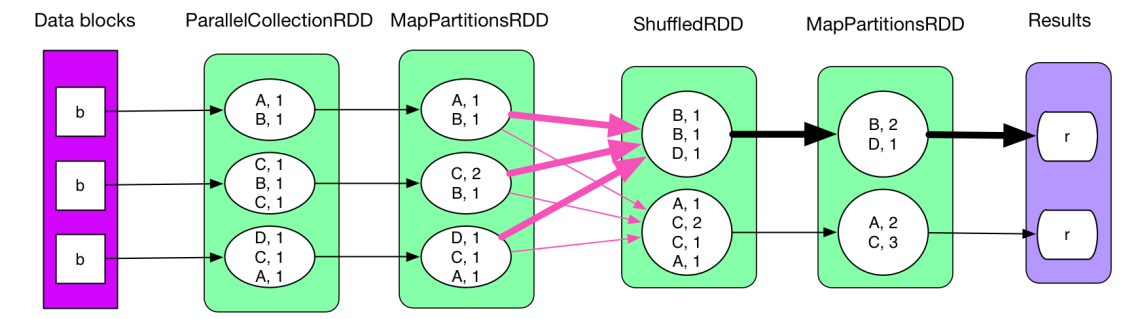
二、reduceByKey的原理如下图

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









