










一 前言:
目的: 熟悉一下Hadoop 集群搭建的过程, 哪怕 2 台机器也来趟一遍。通过学习集群的 log,熟悉集群的流程。为以后有条件搭建和维护上百台的集群环境(我想应该是没这个可能的),迈出一小步。
二 先来熟悉一下 单节点伪模式(standalone)搭建步骤:
1) 安装ssh和 rsync
sudo yum install openssh
sudo yum install rsync
2) 进入~目录,创建ssh免密
mkdir .ssh
chmod 700 -R .ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
ssh localhost
ssh 0.0.0.0
3)安装JDK
下载 jdk8u-server-release-1708 并解压到 ~/.local/bin
4) 下载并编译 Hadoop
下载:wget http://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/hadoop-2.7.1.tar.gz
编译:如果不需要支持snappy,可以去掉。网上可以搜索支持snappy的编译方法,这里不做介绍。
sudo /home/xxx/.local/bin/apache-maven-3.0.5/bin/mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/lib64
5) 创建相关的目录和设置相关的环境变量(如果有多个磁盘,添加多份)
mkdir -p ~/data
mkdir ~/data/hdfs
mkdir ~/data/hdfs/namenode
mkdir ~/data/hdfs/datanode
添加下面环境变量到 .bashrc
export MY_LOCAL_BIN=${HOME}/.local/bin
#JAVA
export JAVA_HOME=${MY_LOCAL_BIN}/jdk8u-server-release-1708
export M2_HOME=~/.local/bin/apache-maven-3.0.5/
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP
export HADOOP_HOME=$MY_LOCAL_BIN/Hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
#不需要spark的,这部分可省略
export SPARK_HOME=$MY_LOCAL_BIN/Spark
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export SPARK_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
#Scala
export SCALA_HOME=${MY_LOCAL_BIN}/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin
#HiBench
export HIBENCH_HOME=$MY_LOCAL_BIN/HiBench
6)需要在HiBench上跑Hadoop的可以直接安装HiBench或者编译HiBench来安装
启动Hadoop 后可以看到如下进程:
$ jps
2581 DataNode
3592 JobHistoryServer
2859 SecondaryNameNode
3307 NodeManager
3149 ResourceManager
3933 Jps
2398 NameNode
三 集群(2 节点,其中一台机器既做master又做slave)搭建步骤:
集群规划
主机名 ip 安装的软件 进程
master(master机器) 10.64.16.27 jdk、hadoop NameNode ResourceManager JobHistoryServer
slave1(master机器) 10.64.16.27 jdk、hadoop DataNode NodeManager
slave2(slave机器) 10.64.16.28 jdk、hadoop DataNode NodeManager SecondaryNameNode
为了便于理解,配一张集群(YARN)原理图:

HDFS集群原理图:

1) ssh 集群 免密
在master 节点上运行 ssh-copy-id slave2(10.64.16.28)
ssh slave2确认是否成功。
2) Hadoop 集群的配置文件
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
hdfs-site.xml
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
3) 在 Hadoop/etc/hadoop/ 目录下创建 masters 和 slaves 文件
3.1) master机器
masters 文件
master
slaves 文件
master
slave2
3.2) slave机器
masters 文件
master
slaves 文件
slave2
4) scp 复制 hostname 、环境变量(.bashrc) 及 Hadoop 配置文件 到其他主机
4.1) hostname
4.1.1) hostname DNS解析
/etc/hosts 文件内容如下:
10.64.16.28 slave2
10.64.16.27 master
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
scp /etc/hosts slave2:/etc/
例如:
scp -r /etc/hosts 10.64.16.28:/etc/
4.1.2)hostname永久生效(重启生效)
修改/etc/sysconfig/network下的HOSTNAME变量 --需要重启生效,永久性修改。
4.1.3)hostname 命令修改立即生效,其对应/proc/sys/kernel/hostname的值
例如:master机器上运行 hostname master;slave 机器上运行 hostname slave2
4.2) scp 复制Hadoop配置文件
scp -r ~/Hadoop/etc/hadoop 10.64.16.28:/home/xxx/Hadoop/etc/
4.3) scp 复制环境变量文件
scp -r ~/.bashrc 10.64.16.28:/home/xxx/.bashrc
5) master及slave2机器的Hadoop 软连接及实际路径一致, 启动时否则报错:
/home/xxx/.local/bin/hadoop-2.7.1-linux4.14.15 与下面不一致
/home/xxx/.local/bin/hadoop-2.7.1-src-arm-compiled/
报错如下:10.64.16.28: bash: line 0: cd: /home/xxx/.local/bin/hadoop-2.7.1-linux4.14.15: No such file or directory
6)修改~/HiBench/conf/hadoop.conf 和 ~/HiBench/conf/hibench.conf
6.1)修改 HiBench/conf/hadoop.conf
# The root HDFS path to store HiBench data
hibench.hdfs.master hdfs://master:9000
6.2) 修改 HiBench/conf/hibench.conf
hibench.masters.hostnames master
hibench.slaves.hostnames slave2
6.3) scp 复制 HiBench 配置文件到 slave2 机器
#HiBench
scp -r ~/HiBench/conf 10.64.16.28:/home/xxx/HiBench/
7)修改~/HiBench/conf/spark.conf
spark.eventLog.dir hdfs://master:9000/sparklogs
四 集群(2节点)测试:
1) 启动 Hadoop,
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
2) Master机器上可以看到如下进程:
$jps
10800 NameNode
10977 DataNode
11412 ResourceManager
27288 Jps
11561 NodeManager
11836 JobHistoryServer
3) Slave2 机器上可以看到如下进程:
$ jps
8759 SecondaryNameNode
8602 DataNode
8875 NodeManager
26299 Jps
4)查看dfs, http://10.64.16.27:50070/dfshealth.html#tab-overview
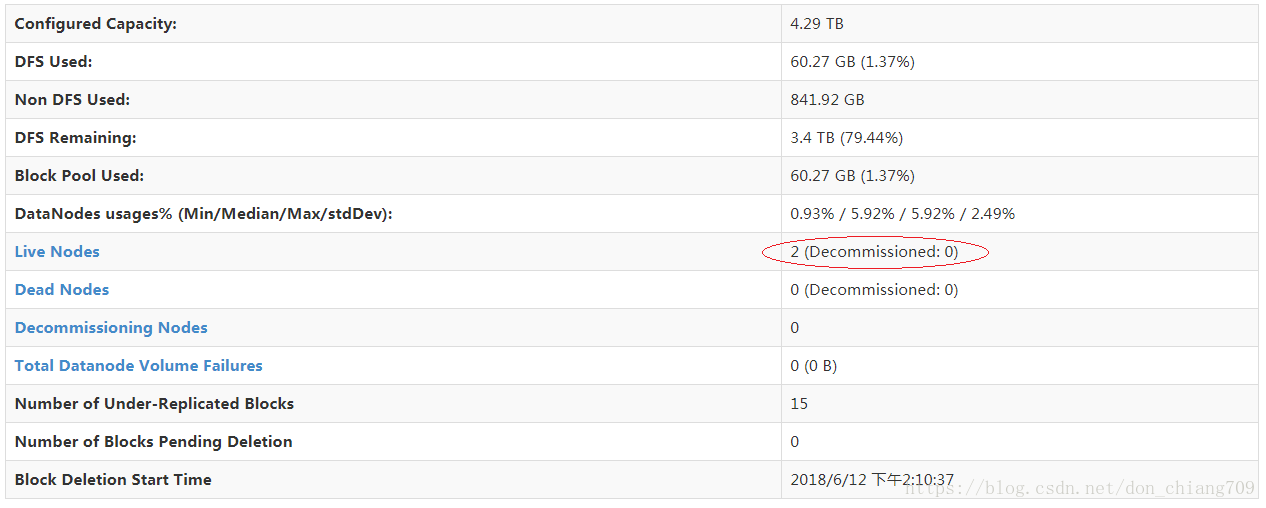
五 集群(5 节点)搭建步骤:
集群规划
| 主机名 | ip | 安装的软件 | 进程 |
| master(master机器) | 10.64.16.27 | jdk、hadoop | NameNode SecondaryNameNode ResourceManager JobHistoryServer |
| slave1 | 10.64.16.38 | jdk、hadoop | NameNode NodeManager |
| slave2 | 10.64.16.39 | jdk、hadoop | NameNode NodeManager |
| slave3 | 10.64.16.40 | jdk、hadoop | NameNode NodeManager |
| slave4 | 10.64.16.41 | jdk、hadoop | NameNode NodeManager |
由于这次是重新安装Cent OS的,并且这次的master不再兼职slave,相比集群(2节点)需要做如下系统设置:
1)关掉防火墙:sudo systemctl stop firewalld.service && sudo systemctl disable firewalld.service
如果没有关掉防火墙出现会如下错误:
java.net.NoRouteToHostException: No route to host
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DFSOutputStream.createSocketForPipeline(DFSOutputStream.java:1508)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1284)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1237)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:449)
centos从7开始默认用的是firewalld,这个是基于iptables的,虽然有iptables的核心,但是iptables的服务是没安装的。所以你只要停止firewalld服务即可
2)系统的limitation,用ulimit -a 命令查看。进程数和文件打开数通常是障碍。报错如下:
WARN org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch: Failed to launch container.
java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:522)
at org.apache.hadoop.util.Shell.run(Shell.java:456)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:722)
临时设置:
ulimit -n 65536
ulimit -u 65536
永久生效,更改下面两个文件:/etc/security/limits.d/20-nproc.conf 和 /etc/security/limits.conf
/etc/security/limits.d/20-nproc.conf:5:* soft nproc 65536
/etc/security/limits.d/20-nproc.conf:6:* hard nproc 65536
/etc/security/limits.conf:63: * hard nofile 65536
/etc/security/limits.conf:64: * soft nofile 65536
3)GC使用效率低下 ,解决这种问题两种方法是,增加参数,-XX:-UseGCOverheadLimit,关闭这个特性,或者 增加(map/reduce)heap大小
INFO mapreduce.Job: Task Id : attempt_1530262438481_0003_r_000155_1, Status : FAILED
Error: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: Error while doing final merge
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:160)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:376)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.OutOfMemoryError: GC overhead limit exceeded
at org.apache.hadoop.mapreduce.task.reduce.InMemoryReader.<init>(InMemoryReader.java:40)
at org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl.createInMemorySegments(MergeManagerImpl.java:625)
at org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl.finalMerge(MergeManagerImpl.java:794)
at org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl.close(MergeManagerImpl.java:370)
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:158)
... 6 more
4) Master 和 Slave 文件如下 :
masters:
master.serversolution.sh.com
jps进程:
43937 NameNode
44516 ResourceManager
44229 SecondaryNameNode
44934 Jps
44846 JobHistoryServer
slaves:
cluster1.serversolution.sh.com
cluster2.serversolution.sh.com
cluster3.serversolution.sh.com
cluster4.serversolution.sh.com
jps进程:
2454 NodeManager
2807 Jps
2269 DataNode
5) Hibench 相关配置hibench.conf如下 :
hibench.masters.hostnames masters.serversolution.sh.com
hibench.slaves.hostnames cluster1.serversolution.sh.com cluster2.serversolution.sh.com cluster3.serversolution.sh.com cluster4.serversolution.sh.com
如果 hibench.slaves.hostnames 配置的slave不完整,hibench的 monitor 页面显示的memory等信息将小于整个集群的资源。
hadoop.conf如下
hibench.hdfs.master hdfs://master.serversolution.sh.com:9000
六 总结:
1)先熟悉单节点模式搭建,然后再搭建集群。如果搭建集群出问题,请到Hadoop/logs/下查看相应log文件。注意: 如果使用HiBench, 需要HiBench的配置文件也要同步。
另外为什么有上面的配置,可参考Hadoop的启动脚本介绍(https://blog.youkuaiyun.com/g11d111/article/details/52837828)。
其中 namenode 和 secondarynamenodes 是通过 hdfs getconf -namenodes 和 hdfs getconf -secondarynamenodes 获取 hostname,然后ssh 登录启动的。 resourcemanager 由 yarn-daemon.sh 调用启动$YARN_MASTE。
datanode 和 nodemanager 最终都是通过 脚本 slaves.sh 遍历 Hadoop/etc/hadoop/slaves文件获取 hostname,然后ssh 登录启动的。nodemanager 由 yarn-daemons.sh 中间调用启动 slaves.sh。
2)iowait性能优化方面:
a. 读写性能好的磁盘可以设置多个目录(比如:core-site.xml的 hadoop.tmp.dir 和 hdfs-site.xml的 dfs.datanode.data.dir配置)
b. blocksize 和 splitsize 可以设置大一些(默认是128m, 设置成384m)
c. 默认设置,磁盘使用率达到90%,该nodemanager 会被标志为 Unhealthy Nodes。
3)cpu 使用率优化方面:
a. 减少map (mapreduce.map.memory.mb)/reduce (mapreduce.reduce.memory.mb)的 memory 力度,增加并发性。
b. 适当增加 hibench.default.map.parallelism 和 hibench.default.shuffle.parallelism 值
4)memory 使用率优化方面:
减少map及reduce阶段的spill。
七 参考:
http://Hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
https://www.edureka.co/blog/setting-up-a-multi-node-cluster-in-hadoop-2.X


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









