






分析 RFC6937 和 tcp_cwnd_reduction 函数,再看我的 数据包守恒和拥塞控制,做对一道中学几何题就理解 PRR 算法了。
按照兑换比分析,用几何描述下面的算法:
DeliveredData = change_in(snd.una) + change_in(SACKd)
prr_delivered += DeliveredData
pipe = (RFC 6675 pipe algorithm)
if (pipe > ssthresh) {
// Proportional Rate Reduction
sndcnt = CEIL(prr_delivered * ssthresh / RecoverFS) - prr_out // 公式 1
} else {
// Two versions of the Reduction Bound
if (conservative) {
// PRR-CRB
limit = prr_delivered - prr_out
} else {
// PRR-SSRB
limit = MAX(prr_delivered - prr_out, DeliveredData) + MSS
}
// Attempt to catch up, as permitted by limit
sndcnt = MIN(ssthresh - pipe, limit)
}
公式 1 变换为:
sndcnt + prr_out = CEIL(prr_delivered * ssthresh / RecoverFS)
意味着兑换比就是 β = ssthresh / RecoverFS,收到 1 个单位数据,发送 β 单位数据。trace 几何图示如下:
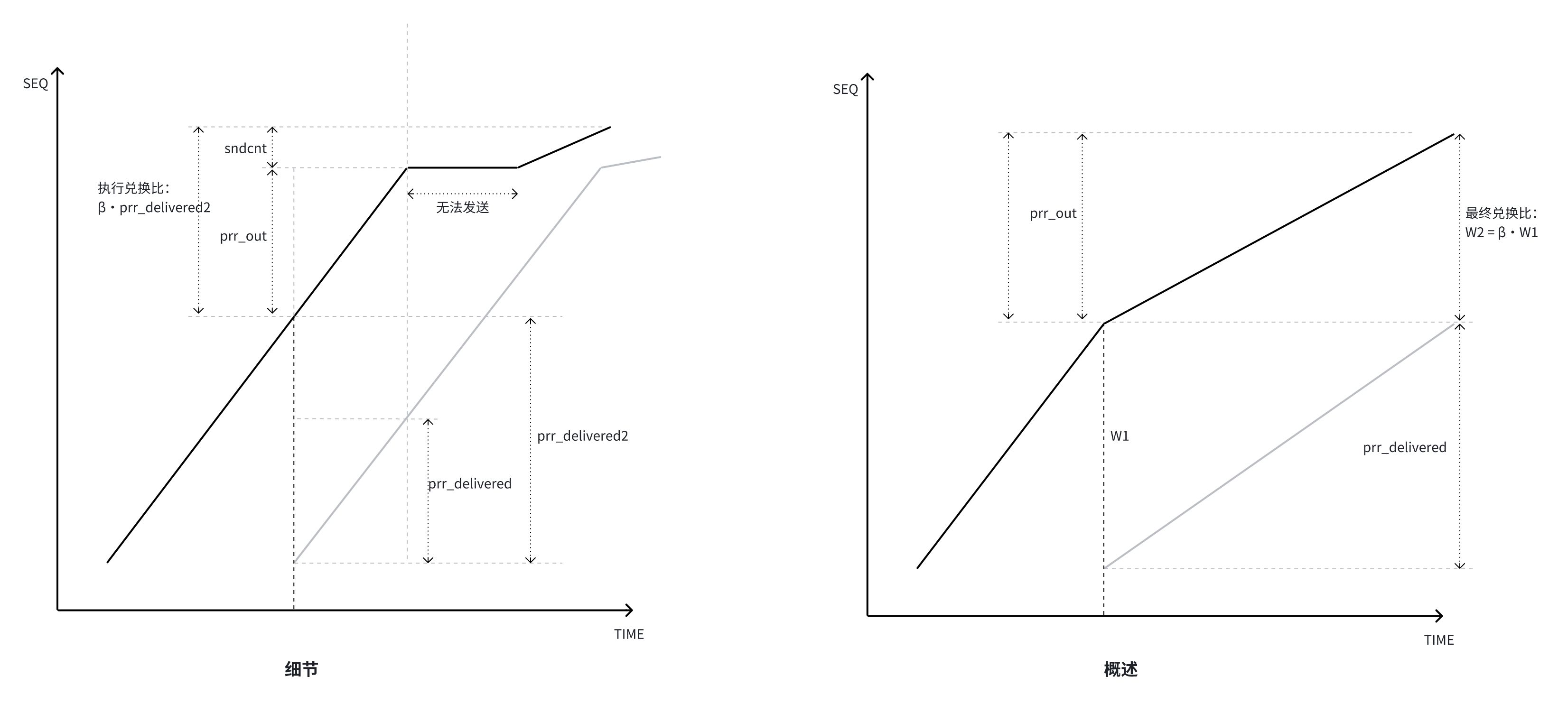
最终直到 cwnd = β·cwnd_prior 停止。但魔鬼在细节,最重要的并不是这个兑换比,而是 inflight 的变化:
static inline unsigned int tcp_left_out(const struct tcp_sock *tp)
{
return tp->sacked_out + tp->lost_out;
}
/* This determines how many packets are "in the network" to the best
* of our knowledge. In many cases it is conservative, but where
* detailed information is available from the receiver (via SACK
* blocks etc.) we can make more aggressive calculations.
*
* Use this for decisions involving congestion control, use just
* tp->packets_out to determine if the send queue is empty or not.
*
* Read this equation as:
*
* "Packets sent once on transmission queue" MINUS
* "Packets left network, but not honestly ACKed yet" PLUS
* "Packets fast retransmitted"
*/
static inline unsigned int tcp_packets_in_flight(const struct tcp_sock *tp)
{
return tp->packets_out - tcp_left_out(tp) + tp->retrans_out;
}
inflight 本就抛除了 lost_out,如果 lost_out 太多,比如无线场景,或 DCN 大象流遭遇 incast 场景, tcp_packets_in_flight 会一下子降到 ssthresh 以下。显然在这个时候,硬要把 cwnd 提到 ssthresh 会继续丢包。这种场景下,算法重要的是后半部:
else {
// Two versions of the Reduction Bound
if (conservative) {
// PRR-CRB
limit = prr_delivered - prr_out
} else {
// PRR-SSRB
limit = MAX(prr_delivered - prr_out, DeliveredData) + MSS
}
// Attempt to catch up, as permitted by limit
sndcnt = MIN(ssthresh - pipe, limit)
}
这里可以看到一个强版本的数据包守恒,这是一个一比一的兑换,DeliveredData 作为可以新发送的数据量,它表示如此多的数据量在本轮被确认而离开网络了。
这就是我在昨天提到的那个问题 PRR 的 Linux 实现问题。RFC6937 并没有规定 PRR 结束之后如何做,Linux 直接将 cwnd = ssthresh 显然是不合适的。
如果管道收缩 1000 倍,cwnd 本是 5000,正常应该收缩到 cwnd = 5,然而按照 AIMD 标准算法,经历一次丢包后,cwnd 收缩到 β·cwnd,以 Reno 为例,即 cwnd = 2500,这显然还会继续丢包,幸运的是,PRR 可以一次性将 cwnd 收缩到 5,遗憾的是,Linux 将 cwnd = 5 又拉回了 cwnd = 2500。
AIMD 应对丢包无条件执行相同逻辑,它无法区分拥塞丢包还是链路随机丢包,对于拥塞丢包,固定比例降窗无疑是合适的,但对于链路随机丢包,特别是丢包率波动变化很大的情况,固定比例降窗显然不合适,drain to target 才合适,而 PRR 可以做到,with PRR,sending rate is bounded to be near delivery rate。
浙江温州皮鞋湿,下雨进水不会胖。

















 2490
2490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









