




 本文记录了一次Python爬虫过程中遇到的页面电话号码加密问题,详细描述了解密过程,包括发现CSS字体加密、解析Base64字体信息、建立字符对应关系字典,最终成功解密出联系电话。
本文记录了一次Python爬虫过程中遇到的页面电话号码加密问题,详细描述了解密过程,包括发现CSS字体加密、解析Base64字体信息、建立字符对应关系字典,最终成功解密出联系电话。
一、爬取页面后电话号码加密了
![]()
二、检查页面元素发现也看不到,使用的是css字体加密

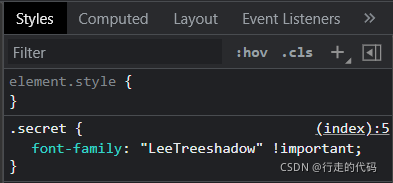
三、继续查看,发现是用base64加密的字体信息

四、网上查资料先要解密字体的对应关系
#正则查找base64加密后的数据
ba64str = re.findall('charset=utf-8;base64,(.*?)"\)', text)[0]
#用base64解密
b = base64.b64decode(ba64str)
print(b)
#使用字体工具处理成字典
font = TTFont(BytesIO(b))
bestcmap = font['cmap'].getBestCmap()
print(bestcmap)
五、查找对应关系,组成正确的对应关系字典
六、网页数据找到加密后的数据,替换成16进制,并转换成10进制,使用10进制的key匹配对应的值,就是正确的数字,不换行输出就是正确的联系电话了
num_
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









