




一、DBSACAN与K-means:
我们刚入门时,大部分学的都是k-means聚类。当我们进行实例操作时,会发现k-means聚类方法有很大的局限性,它无法分离任意形状的数据集如下图。
该数据集对于k-means方法来说,有点过于强人所难了,但对DBSCAN来说,却是小菜一碟。下面我将向大家介绍DBSCAN算法的原理,以及代码是实现。
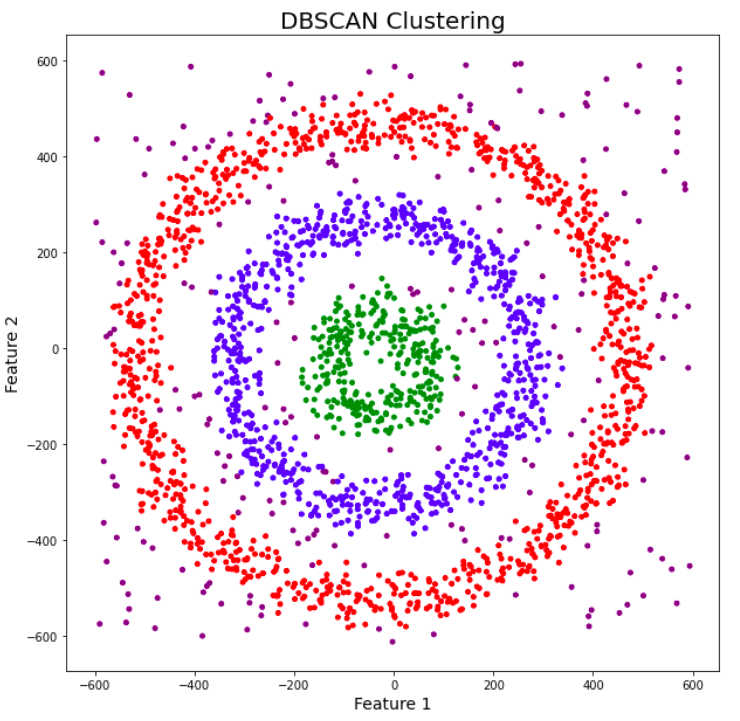
应用场景:适用于非凸形状聚类(如验证码识别、3D点云分割),解决k-means无法处理的复杂分布问题。
二、核心思想:
想象你在校园里发问卷:
-
ε-邻域:以你为中心,半径 ε 内的同学就是你的“直接朋友圈”。
-
核心点:如果你的直接朋友圈人数 ≥
min_samples,你就是“核心人物”,有资格成立社团。 -
边界点:你恰好在别人的朋友圈里,但自己朋友圈人数不够,只能算“编外成员”。
-
噪声点:既没资格成立社团,也不属于任何朋友圈,就是“独行侠”。
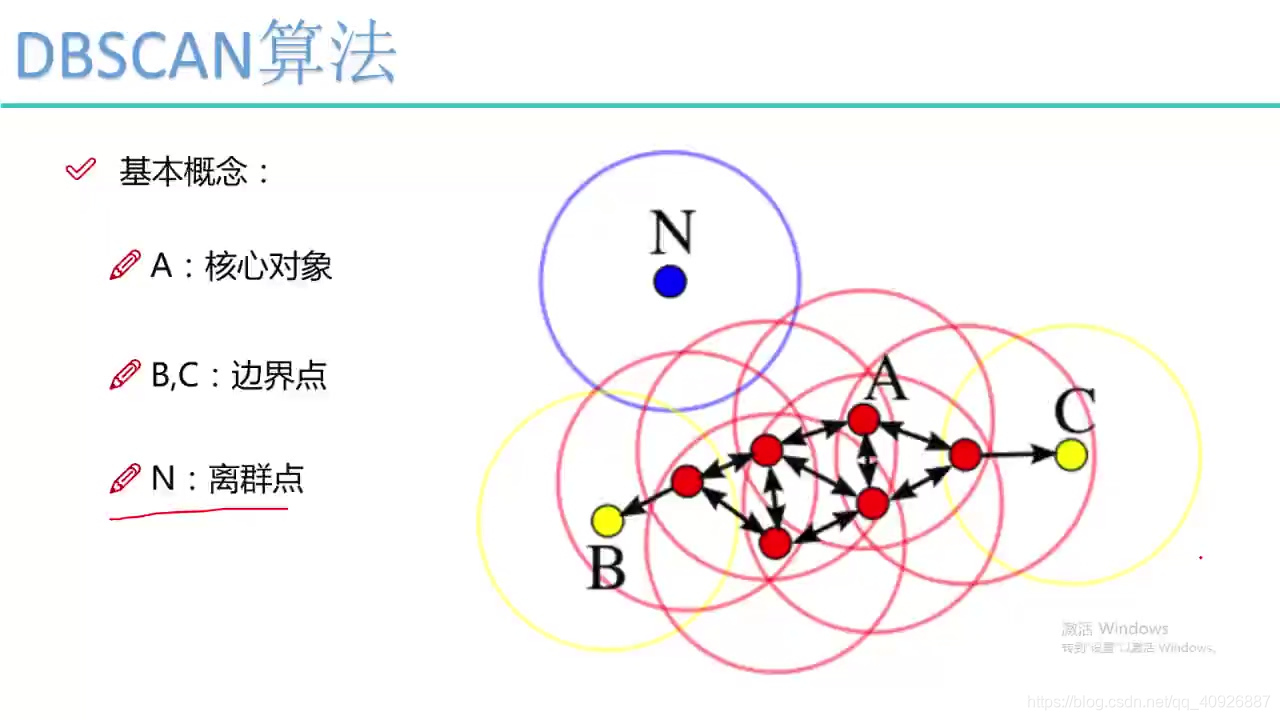
从图中可以看出:
A是核心对象:它可以感染3个点,半径就是ε阈值,
红色的点都可以独立感染3个点都可以叫做核心点
B、C:由于不能独立感染,有其他
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2947
2947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









