




 本文探讨了索引在查询中的应用,包括数据量对索引使用的影响、等值查询与非等值查询的索引选择差异,以及如何根据查询条件顺序优化复合索引。重点讲解了最左匹配原则和索引利用效率,以及在实际场景中的最佳索引构建策略。
本文探讨了索引在查询中的应用,包括数据量对索引使用的影响、等值查询与非等值查询的索引选择差异,以及如何根据查询条件顺序优化复合索引。重点讲解了最左匹配原则和索引利用效率,以及在实际场景中的最佳索引构建策略。
是否走索引 和 数据量有关系
索引是(a,b)
查询是 select * from my_table where a=x; 可能数据量小的时候不走索引,等数据量增大了,就走索引了。
where 条件里面的字段顺序和是否走索引没有关系
上面说的主要是等值查询 例如 where field_a=1 and filed_b=2 和 where filed_b=2 and field_a=1 的索引情况是一样的
那如果是非等值索引呢?
where a=x and b>y and c=z 和 where a=x and c=z and b>y
上面两个sql 运行后的数据集肯定是一样的。那走的索引是不是一样的呢?或者换句话说 都是用and链接的条件,在包含非等值查询的时候,条件的顺序还有用么?
答案是条件的顺序无所谓。
上面那个case,最优的建立索引的顺序是 (a,c,b)
有索引(a,b,c,d)的时候
单独查询 a,(a,b) (a,b,c) (a,b,c,d) 都可以走索引;但是根据最左匹配,直接查询b,或者b,c and d,d都不能走索引。
索引查到不等值就会停下来。例如 where a=x and b>y and c=z 就只能使用ab索引
组合索引的选择率
选择率应该是最大的例如userid 之后的元素要保证 凡是等值查询的都放在前面 非等值查询的(大于小于 in)放到后面
索引是(a,b),查询条件也是 a=x and b=y 此时如果select * 就有可能不走索引。(因为回表)
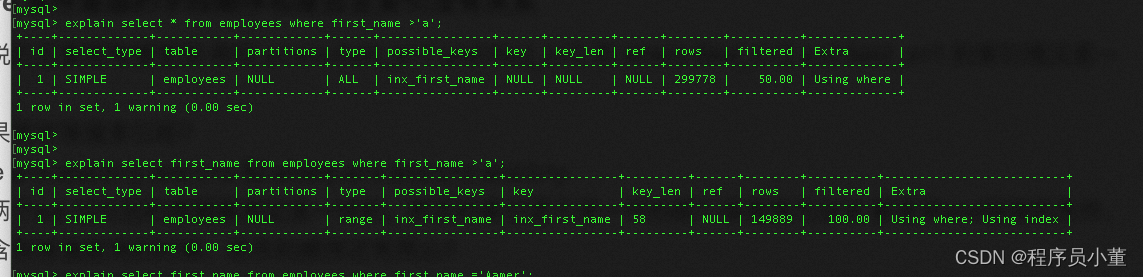
例如上面
explain select * from employees where first_name >'a';
explain select first_name from employees where first_name >'a';
两个sql一个走索引一个不走索引,区别在哪?区别就在最终返回的结果一个只查first_name,一个需要回表查询所有字段
那有回表就一定不走索引么?
怎么可能!!
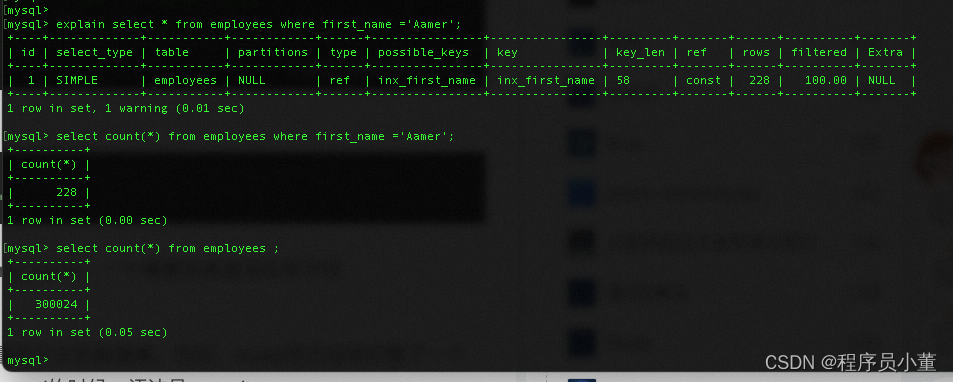
另外因为上面说了是否走索引 和 数据量有关系,所以大家以后测试的时候,就尽量找个大的数据集。恰好,mysql官方给我们整了一个雇员系统的db。 具体怎么用:https://zhuanlan.zhihu.com/p/293983110 记住导入mysql的时候,语法是
mysql -uxxx -pxxx < you_file_path/employees.sql
如果已经登录了,可以使用如下命令导入sql脚本
mysql> source /path/to/file.sql;
或
mysql> \. /path/to/file.sql
参考资料
https://heapdump.cn/article/3965201

















 2850
2850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









