




 本文详细介绍了Python中的re模块,包括正则表达式的定义、应用场景和特点,以及re模块的使用流程。通过实例展示了元字符如.|, ^, $, *, +, {n}, {m,n}等的用法,还涵盖了匹配单词边界、正则表达式的转义以及捕获组的概念。此外,列举了re模块常用方法如findall(), split(), sub()和subn()的功能及使用方法。"
105797220,9194005,SPH液体模拟:Parsec.FluidAnimate基准解析,"['高性能计算', '数值模拟', '计算机图形学', '流体力学', '基准测试']
本文详细介绍了Python中的re模块,包括正则表达式的定义、应用场景和特点,以及re模块的使用流程。通过实例展示了元字符如.|, ^, $, *, +, {n}, {m,n}等的用法,还涵盖了匹配单词边界、正则表达式的转义以及捕获组的概念。此外,列举了re模块常用方法如findall(), split(), sub()和subn()的功能及使用方法。"
105797220,9194005,SPH液体模拟:Parsec.FluidAnimate基准解析,"['高性能计算', '数值模拟', '计算机图形学', '流体力学', '基准测试']
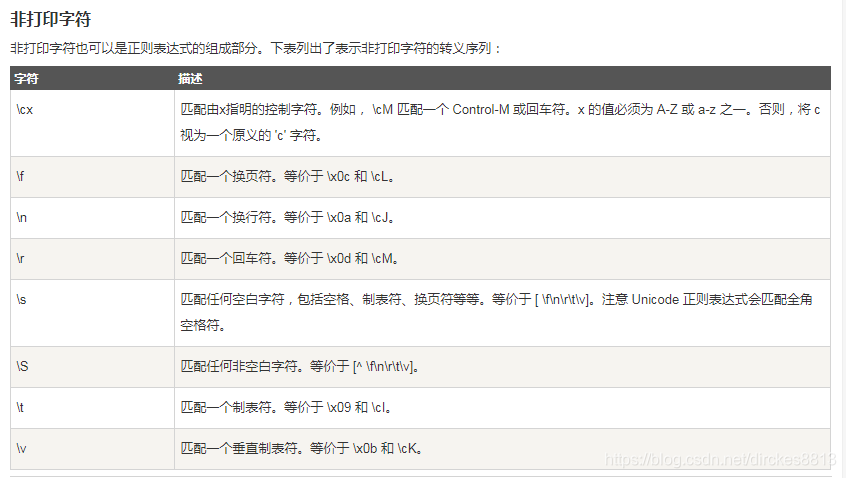
1.re字符 AM
2.re的使用 PM
3.正则表达式 AM
4.正则符号表,以及在线测试生成正则网站
AM
1、正则表达式
- 1、应用场景
- 1、在1个文件/字符串中,找到qq邮箱地址
"3094333@qq.com aaa@126.com 555555@qq.com" - 2、在nginx访问日志中,提取出所有的IP地址
- 3、从超级长字符串中提取想要的数据(内涵段子)
- 1、在1个文件/字符串中,找到qq邮箱地址
- 2、定义
- 用一些具有特殊含义的符号组合到一起,来描述字符/字符串的方法
- 3、应用范围
- 1、对文本内容(字符串)的定位、提取、替换
- 2、Web后端框架Django路由
- 3、Python爬虫文本匹配
- 4、… …
- 4、正则特点
- 1、方便处理文本
- 2、支持语言众多
- 3、使用灵活多样
2、re模块使用流程
- 1、导入模块
- import re
- 2、re模块的findall()方法匹配字符串
- rList = re.findall(‘正则表达式’,‘匹配的字符串’)
- 3、示例代码
s = ‘hello 13811111111 I am 13999999999,He is 119 hello 119’
3、元字符的使用
-
1、普通元字符 :a b c f
- 1、匹配规则 :每个字符匹配对应的自身字符
- 2、示例
In [2]: re.findall(‘He’,‘Hello Tom Hello Jim’)
Out[2]: [‘He’, ‘He’]
In [3]: re.findall(‘小姐姐’,‘小姐姐小姐姐,我是Python小哥哥’)
Out[3]: [‘小姐姐’, ‘小姐姐’]
-
2、或 元字符 :|
-
1、规则 :匹配 | 两边的任意1个正则表达式
-
2、示例
In [4]: re.findall(‘AB|CD’,‘ABCDEFGAB’)
Out[4]: [‘AB’, ‘CD’, ‘AB’]In [5]: re.findall(‘AB|BC’,‘ABCDEFG’)
Out[5]: [‘AB’] # 不会重复匹配BC
**3、匹配任意1个字符 : **.
- 1、规则 :匹配任意1个字符(不包括换行符\n)
- 2、示例 :t.m -> tom tem tam
In [11]: re.findall(‘t.m’,‘tomt\nm’)
Out[11]: [‘tom’] # .不能匹配\n
-
4、匹配字符串的开始位置 ^:
- 1、规则 :匹配目标字符串的开始位置
- 2、示例 :
- 3、练习
- 1、把/etc/passwd复制到你自己的目录下
sudo cp /etc/passwd 自己路径 - 2、写py文件,把passwd中所有行首的tarena输出
- 1、把/etc/passwd复制到你自己的目录下
5、匹配字符串的结尾位置 :$
- 1、规则 :字符串结束位置
- 2、示例 :
re.findall(‘小姐姐$’,‘Hi,小姐姐’) - 3、练习
查找passwd文件中登录权限为/bin/false用户有几个
6、匹配重复
- 1、* :前面的1个字符出现0次或多次
abc* -> ab abc abcc abccc - 2、+ :前面的1个字符出现1次或多次
abc+ -> abc abcc abccc - 3、{n} :前面的1个字符出现n次
ab{3}c -> abbbc
\d{11} - 4、{m,n} :前面的1个字符出现m-n次
ab{1,3}c -> abc abbc abbbc
PM
1、匹配单词边界
- \b :单词边界
- \B :非单词边界
- re.findall(’\bis\b’,‘This is a rabbit’)
- []
- re.findall(’\bis\b’,‘This is a rabbit’)
- [‘is’]
- re.findall(r’\bis\b’,‘This is a rabbit’)
- [‘is’]
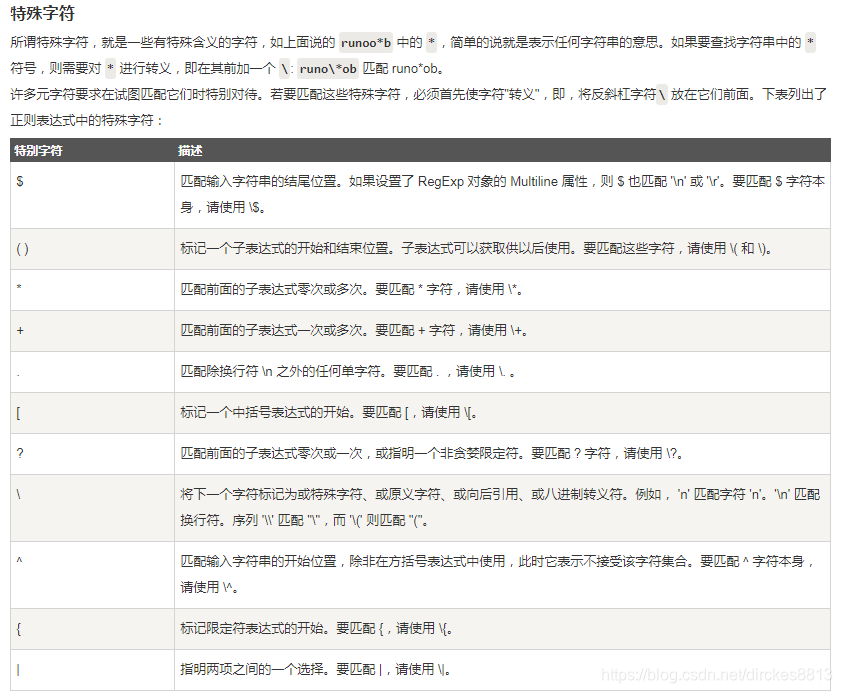
2、正则表达式转义
- 1、正则中特殊符号 :. * ? ^ $ [] () \ {}
- 2、正则表达式匹配特殊符号 :\特殊符号 (. $)
- 3、正则表达式写时请加 :r (re.findall(r’$’,’’)
- 4、示例
- 你写的正则表达式本身就是1个Python字符串
- 第1步 :Python先进行字符串解析
- 第2步 :把Python解析完字符串再传给findall()函数进行正则解析匹配
In [17]: re.findall('\$\d+',"$88")
Out[17]: ['$88']
In [18]: re.findall('\\$\\d+',"$88")
Out[18]: ['$88']
In [19]: re.findall(r'\$\d+','$88')
Out[19]: ['$88']
python字符串 正则表达式 目标字符串
'\\$\\d+' '\$\d+' $88
r'\$\d+' '\$\d+' $88
3、捕获组(有名字)和非捕获组(没有名字)
- 1、捕获组格式 :’(?P\w+)\s+\w+’
- 2、示例
- re.search(’(?P\w+)\s+(?P\w+)’,‘A B C D’).group(“lion”)
- ‘B’
4、re模块常用方法
- 1、regex = re.compile(pattern,flags = 0)
- 功能 :生成正则表达式对象
- 参数 :pattern 正则表达式
- flags 功能标志位(re.I re.S) - 返回值 :对象
- 2、regex对象属性
- 1、pattern :正则表达式
- 2、flags :标志位常量(32)
- 3、groups :组的数量
- 4、groupindex:生成捕获组名和第几组的键值对
- 3、findall(‘正则表达式’,‘目标字符串’)
- 1、返回值为列表,如果有分组只获取子组的内容
- 2、re调用和regex对象调用
- 1、re.findall()
- 2、regex = re.compile(’\w+:\d+’)
- regex.findall(s,pos,endpos)
- pos : 目标字符串起始位置
- endpos : 目标字符串终止位置
- 4、spilt(pattern,string)
- 1、功能 :使用正则表达式匹配部分切割字符串
- 2、regex = re.compile(’\s+’)
- rSplit = regex.split(‘hello world hello tarena’)
- print(rSplit)
- [‘hello’, ‘world’, ‘hello’, ‘tarena’]
- 5、sub(pattern,replaceStr,string,max)
- 1、功能 :使用新字符串替换正则匹配内容
- 2、参数 :replaceStr 新的字符串
- string 目标字符串- max 最多替换几处
- 3、返回值 :字符串
- regex = re.compile(r’\s+’)
- rSub = regex.sub(’###’,‘hello world hello’,1)
- # hello###world hello
- 6、subn(pattern,replaceStr,string,max)
- 1、返回值 :元组(字符串,替换了几次)
- regex = re.compile(r’\s+’)
- rSub = regex.subn(’###’,‘hello world hello’)
- (‘hello###world###hello’, 2)
- 1、返回值 :元组(字符串,替换了几次)
- 7、finditer(pattern,string)
- 1、同findall()
- 2、返回值 :迭代器,迭代器中拿出来match对象
- 3、示例代码
- rIter = re.finditer(r’\d+’,‘2019来了,2018啥也没干’)
- # finditer()结果为迭代器,遍历出来的是match对象
- # 利用match对象的group()方法来获取内容
- for r in rIter:
- print(r.group())
- 8、返回值为match对象的方法
- 1、match(pattern,string)
- 2、功能 :匹配目标字符串的起始位置
- 3、返回值 :match对象



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









