






应用需注明原创!
深度学习在2015年中左右基本已经占据了计算机视觉领域中大部分分支,如图像分类、物体检测等等,但迟迟没有视觉跟踪工作公布,2015年底便出现了一篇叫MDNet的论文,致力于用神经网络解决视觉跟踪,它同时也是2015年VOT的冠军。
先图再理论:
离线学习
frame1
frame2
在线学习:
frame by K+1 fine turn
策略:
1、第一帧训练。
2、打分
在上一帧目标区域附近采样大量的样本,然后用这个分类器打分(当我们找到最像目标的样本时,我们便认为这一帧的目标就是这个样本)
3、在线更新MDnet:消除跟踪过程的累计误差
在跟踪了一段时间之后,当前的分类器便不再那么有效了。
此时可能会发现所有的样本都不再“像”。所以我们不得不需要在跟踪中动态的更新这个分类器,即在线更新MDNet。
4、更新策略:
a):MDNet采取了短期及长期的在线更新策略。在跟踪的过程中,文中算法会保存历史跟踪到的目标作为正样本。长期特征对应历史中最近的100个样本,然后固定时间间隔做一次网络的更新,比如程序中设置为每8帧更新一次;
b):短期特征对应最近的20个样本。这里正样本和负样本都是根据当前分类器的打分得出的,比如分数较高的认为是正样本,分数偏低的认为是负样本。
随着长期和短期的网络更新,MDNet便实时的根据视频的内容自动适应跟踪目标的特征,最终生成了稳定的跟踪结果。
卷积神经网络(CNN)有一些基本的问题:
1 数据量的问题
CNN在图像分类上取得巨大成功,一个必要的条件是拥有了数以百万计的已标注训练数据集ImageNet. 而对于视觉跟踪而言,却一直缺乏类似数据量的数据集。如果只使用视频中第一帧给定的Ground Truth做训练数据,毫无疑问会非常容易产生过拟合。
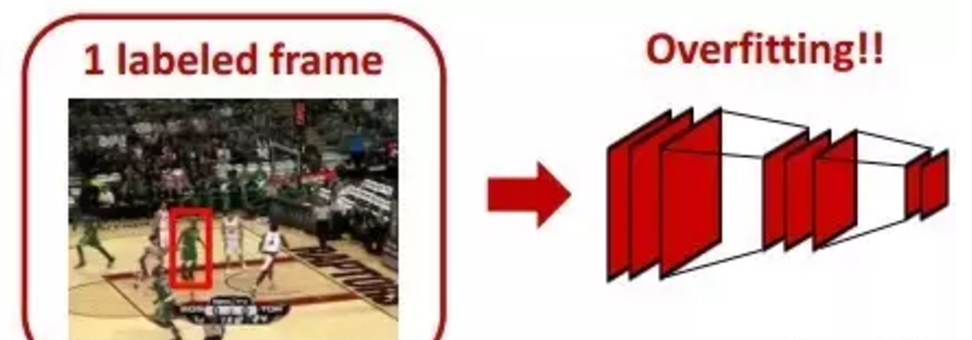
(图像摘自棒子论文)
作者指出与图像分类任务有区别另外一个比较容易想到的方案是利用现有已训练好的图像分类的网络和视觉跟踪数据做Fine-tune。这个方案并不合理,因为图像分类和视觉跟踪在问题本身设置上就有本质不同。所以,性能也一直不好。
2 图像歧义问题
对于不同场景的视频数据,它们的前背景可能又有着冲突或歧义(如视频A中的跟踪对象反而是视频B中的背景),所以直接用有限的视频数据集(如VOT)来训练一个统一的CNN一直非常困难。

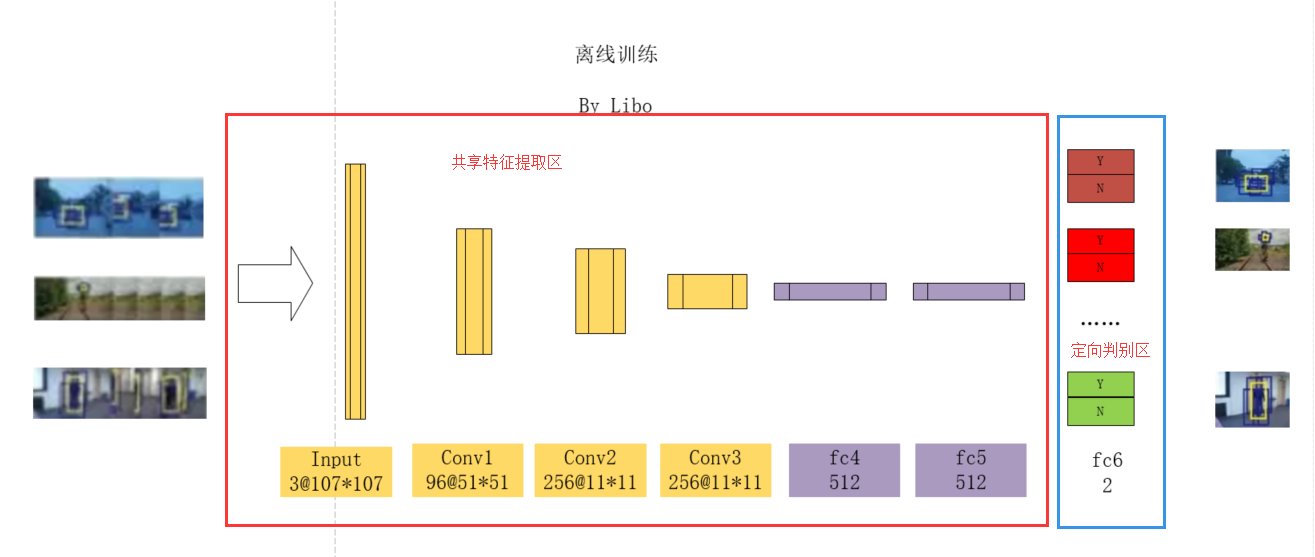
MDNet的网络结构及离线训练
1 网络结构
MDNet把视觉跟踪的特征分析为两个部分,一个是所有视频的共性(Shared Features),另一个是不同视频的个性(Domain-specific Features)。而MDNet就是需要联合地训练一个网络,从而使得这个网络拥有着提取共性和个性特征的能力。为了这个目标,MDNet的结构设计如下:
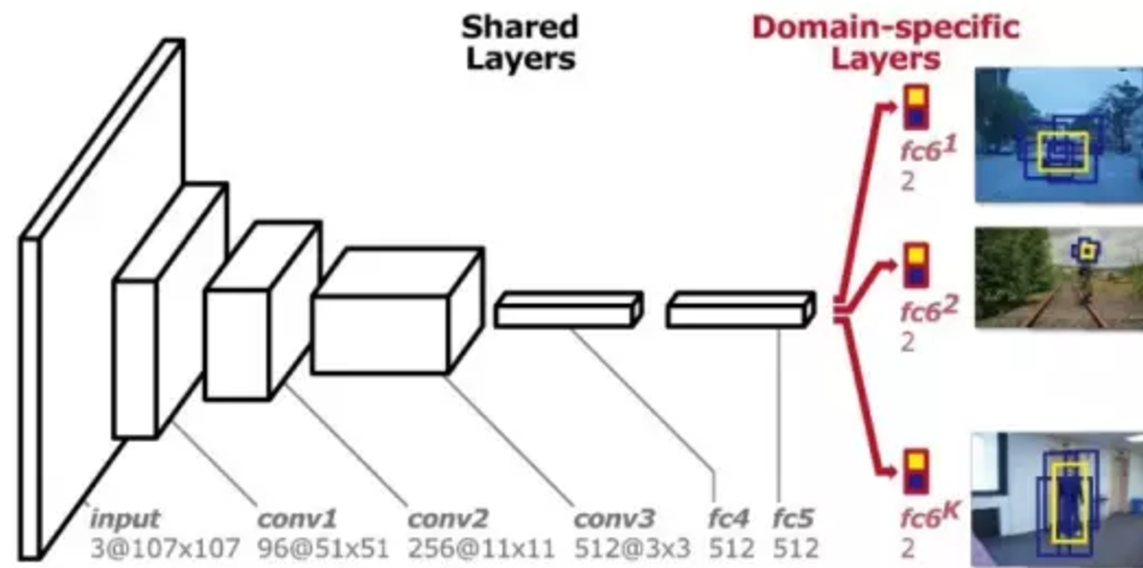
它主要分为共享的和特定的层:
共享层,用于提取公共特性。
在网络层前的MDNet共享设计,在帧图像数据中作为数据,然后经过三层卷积(conv1 ~ 3)两个全连接层(fc4 ~ 5),一个512维特征向量的输出。这部分的卷积层与vggm - m网络中的卷积层相同,只有特征图的大小进行了调整。
用于提取单个视频个性特征的特定层(Domain-specific Layers)
共享层的输出接着会连接K个分支,每个分支都连接一个全连接层fc6. 这里K为训练数据集中视频的个数,所以每一个分支对应了一个特定的视频场景。MDNet的作者希望通过这些特定层,可以提取出单个视频的个性特征,而避免图像歧义的影响。
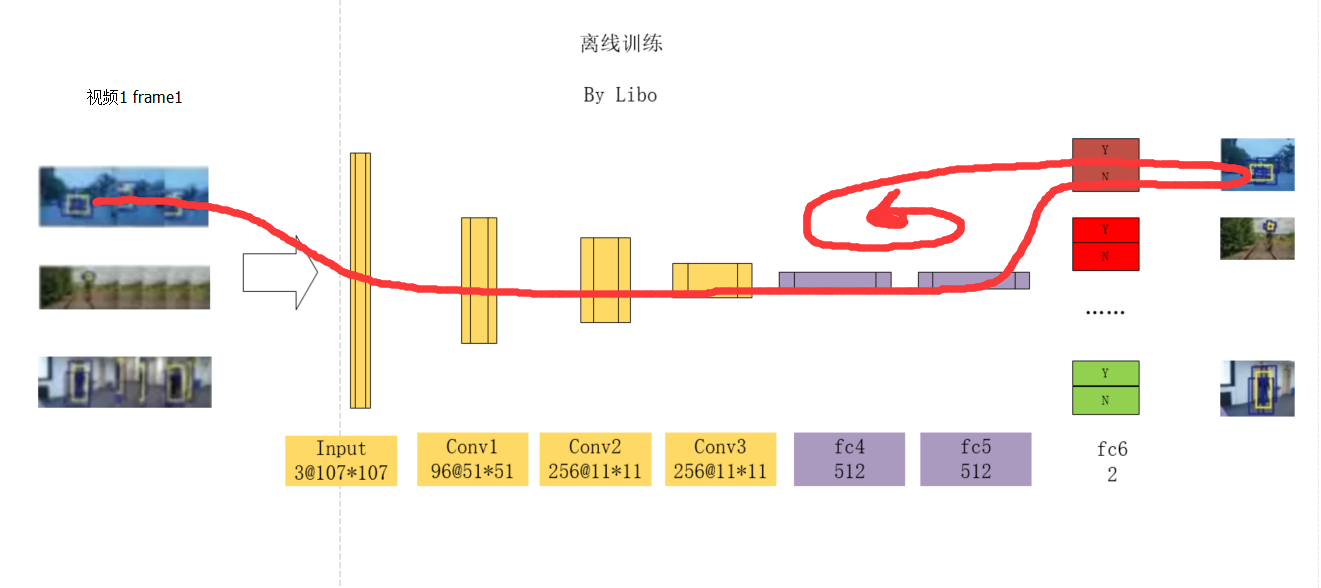
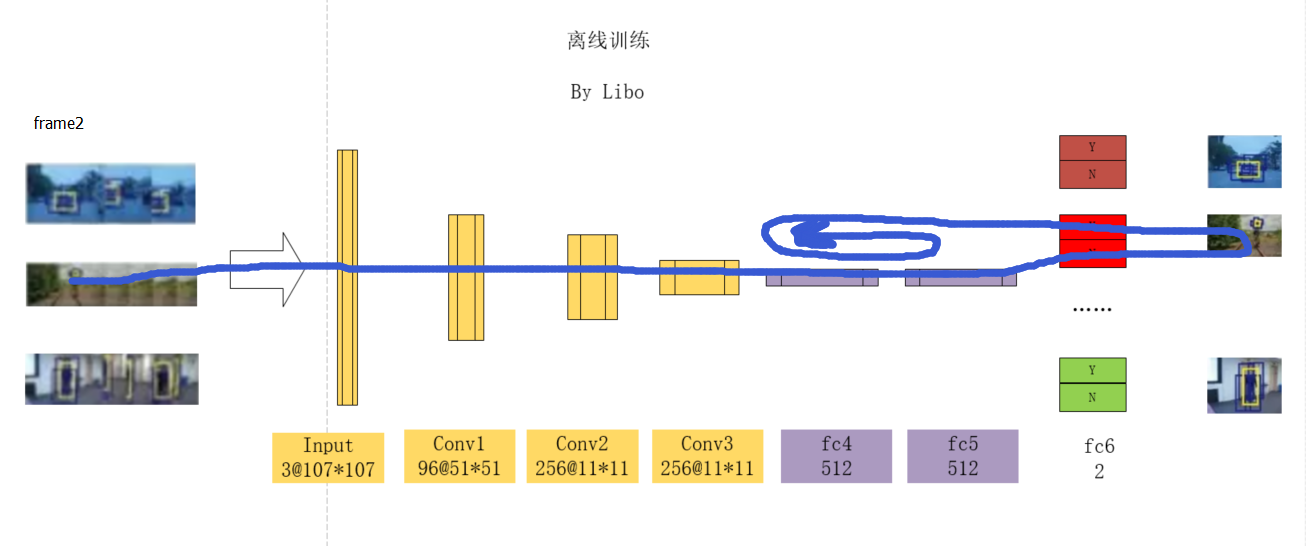
2 离线训练
在构建了这样一种网络结构之后,作者便可以开始训练了。对于K个视频,作者每次只输入其中一个视频的图像帧,以训练其对应的某一个分支。在经过大量的迭代之后,由于每次训练共享层都在反复更新,而特定层只有在对应的视频数据被加载时才被更新,可以想象最终共享层便可以提取所有视频中的共性而把个性部分留在了特定层中.
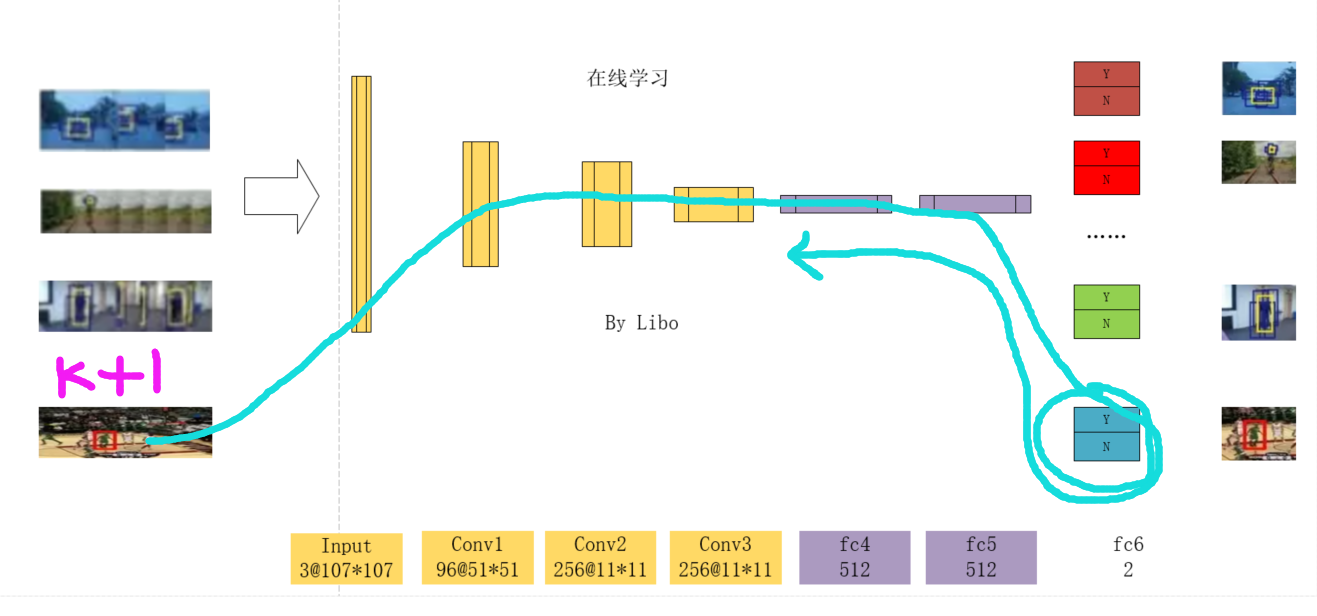
MDNet的在线跟踪
在离线训练好MDNet之后,还不能直接运用在新的视频上,因为它并不具备新视频任何个性的特征信息。实际上,它在面对新的视频时会做一系列的自适应措施。
根据第一帧的Ground Truth做fine-tune
视觉跟踪任务中,第一帧会提供被跟踪对象的位置信息。而MDNet便会利用第一帧的目标信息进一步训练现有的网络。它首先会初始化一个全新的fc6层,然后一并更新fc4~6的权重数值,而保持 conv1~3的权重不变。
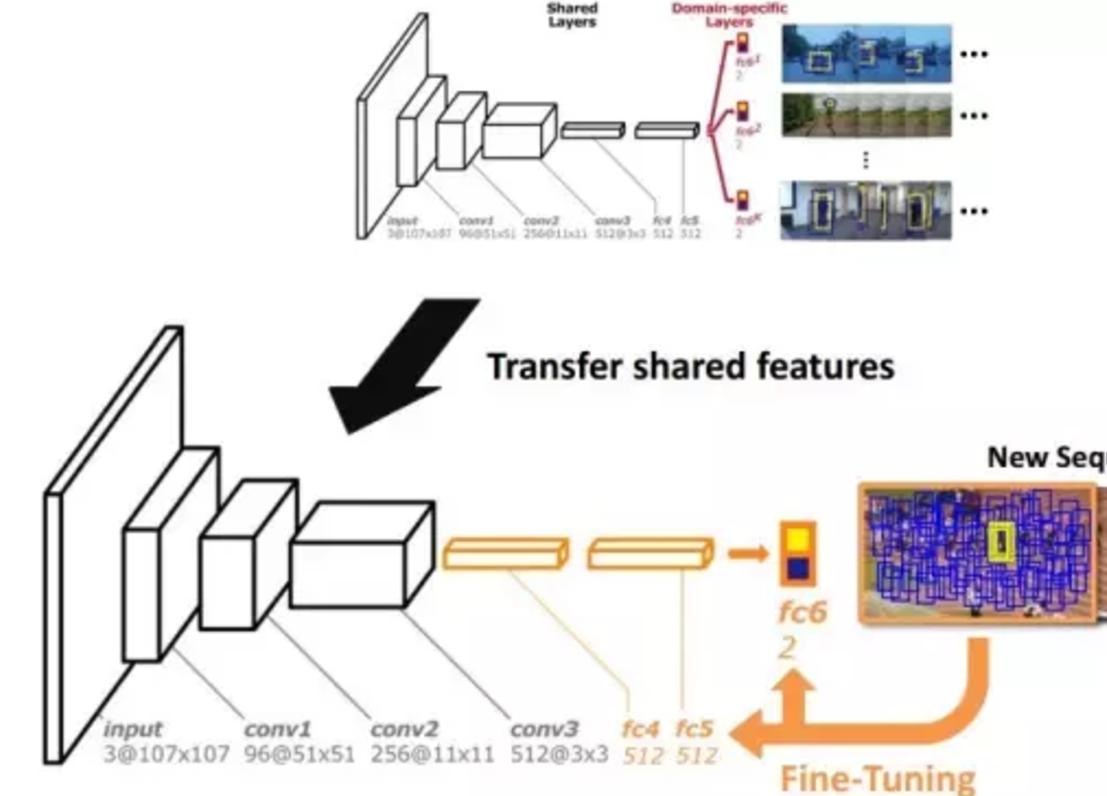
短期及长期的在线更新
第一帧训练好的网络便可以作为分类器做接下来的跟踪了。这个过程会比较简单,即在上一帧目标区域附近采样大量的样本,然后用这个分类器打分。当我们找到最像目标的样本时,我们便认为这一帧的目标就是这个样本。
然而,这样一个简单的思路在每一帧跟踪的过程中,无可避免的会引入累计误差。这样一来,在跟踪了一段时间之后,当前的分类器便不再那么有效了。此时可能会发现所有的样本都不再“像”。所以我们不得不需要在跟踪中动态的更新这个分类器,即在线更新MDNet。
MDNet采取了短期及长期的在线更新策略。在跟踪的过程中,文中算法会保存历史跟踪到的目标作为正样本。长期特征对应历史中最近的100个样本,然后固定时间间隔做一次网络的更新,比如程序中设置为每8帧更新一次;短期特征对应最近的20个样本。这里正样本和负样本都是根据当前分类器的打分得出的,比如分数较高的认为是正样本,分数偏低的认为是负样本。
随着长期和短期的网络更新,MDNet便实时的根据视频的内容自动适应跟踪目标的特征,最终生成了稳定的跟踪结果。
MDNet的跟踪结果评估与结论
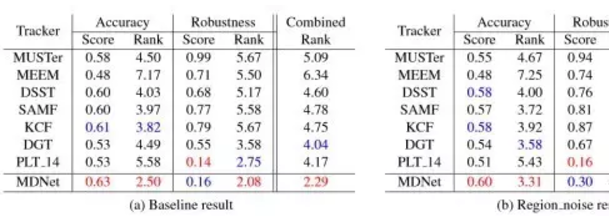
至于MDNet的结果,原论文中给出了比较详细的比较,在OTB和VOT2014数据集上统统秒杀之前的方法。如下的曲线无一证明了这一点:
OBT result:
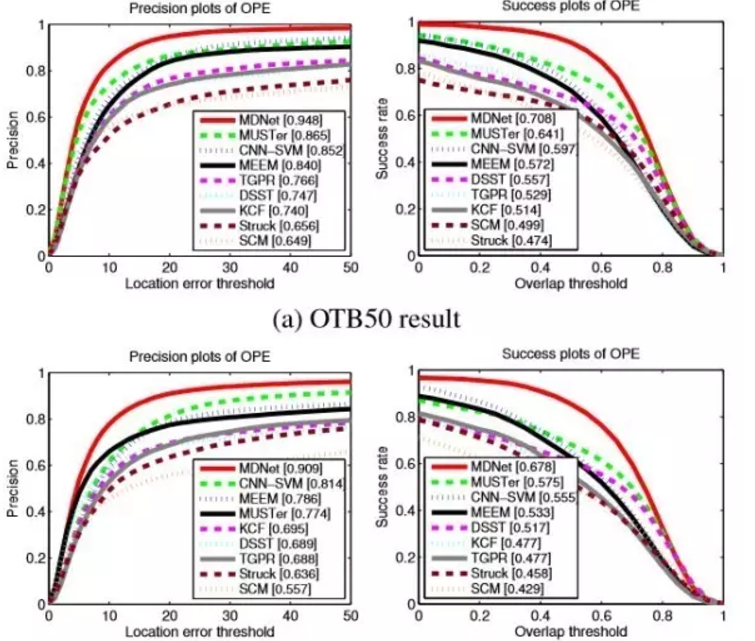
VOT2014 dataset:
总结:
-
巧妙的利用了CNN特征,把它分为共性特征和个性特征,对应地设计出的神经网络也反映了跟踪任务的特点;
-
在线更新模型,使得累积误差不会太大,可以适应场景变化;
-
另外一些小的trick的使用,虽然本文没有详细介绍,但对最终结果也有了比较好的作用,如难负样本挖掘(Hard Negative Mining)和外框拟合(Bounding Box Regression)。
代码:
net:
# conv1
with tf.variable_scope('conv1') as scope:
kernel = _variable_init_from_constant(
'weights',
shape=[7, 7, 3, 96],
val=conv1,
wd=5e-5,
)
# VALID means no padding
conv = tf.nn.conv2d(images, kernel, [1, 2, 2, 1], padding='VALID')
biases = _variable_on_cpu('biases', [96], tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(pre_activation, name=scope.name)
_activation_summary(conv1)
norm1 = tf.nn.lrn(conv1, 5, bias=2, alpha=1e-4, beta=0.75, name='norm1')
pool1 = tf.nn.max_pool(norm1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='VALID', name='pool1')
# conv2
with tf.variable_scope('conv2') as scope:
kernel = _variable_init_from_constant(
'weights',
shape=[5, 5, 96, 256],
val=conv2,
wd=5e-5,
)
conv = tf.nn.conv2d(pool1, kernel, [1, 2, 2, 1], padding='VALID')
biases = _variable_on_cpu('biases', [256], tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(pre_activation, name=scope.name)
_activation_summary(conv2)
norm2 = tf.nn.lrn(conv2, 5, bias=2, alpha=1e-4, beta=0.75, name='norm2')
pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='VALID', name='pool2')
# conv3
with tf.variable_scope('conv3') as scope:
kernel = _variable_init_from_constant(
'weights',
shape=[3, 3, 256, 512],
val=conv3,
wd=5e-5,
)
conv = tf.nn.conv2d(pool2, kernel, strides=[1, 1, 1, 1], padding='VALID')
biases = _variable_on_cpu('biases', [512], tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(pre_activation, name=scope.name)
_activation_summary(conv3)
# fc4
with tf.variable_scope('fc4') as scope:
# reshape dim: 3 * 3 * 512 = 4608
reshape = tf.reshape(conv3, [-1, 4608])
dim = reshape.get_shape()[1].value
weights = _variable_with_weight_decay('weights',
shape=[dim, 512],
stddev=1e-2,
wd=5e-4)
biases = _variable_on_cpu('biases', [512], tf.constant_initializer(0.0))
fc4 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name)
_activation_summary(fc4)
drop4 = tf.nn.dropout(fc4, 0.5, name='drop4')
# fc5
with tf.variable_scope('fc5') as scope:
weights = _variable_with_weight_decay('weights',
shape=[512, 512],
stddev=1e-2,
wd=5e-4)
biases = _variable_on_cpu('biases', [512], tf.constant_initializer(0.1))
fc5 = tf.nn.relu(tf.matmul(drop4, weights) + biases, name=scope.name)
_activation_summary(fc5)
drop5 = tf.nn.dropout(fc5, 0.5, name='drop5')
# fc6
with tf.variable_scope('fc6') as scope:
if K is None:
# only one branches for online tracking
K = 1
k = 0
weights = _variable_with_weight_decay('weights',
shape=[512, 2 * K],
stddev=1e-2,
wd=5e-4)
# K branches for training
biases = _variable_on_cpu('biases', [2 * K], tf.constant_initializer(0))
branch_weight = tf.slice(weights, [0, 2 * k], [512, 2])
branch_biases = tf.slice(biases, [2 * k], [2])
fc6 = tf.nn.bias_add(tf.matmul(drop5, branch_weight), branch_biases, name=scope.name)
#logits = tf.nn.softmax(fc6, name='logits')
_activation_summary(fc6)
return fc6
def loss(logits, labels):
"""Add l2loss to all the traninalbe varibles"""
labels = tf.cast(labels, tf.int64)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=labels, logits=logits, name='cross_entropy_per_example'
)
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
return tf.add_n(tf.get_collection('losses'), name='total_loss')
online fc4,fc5,fc6:
# Add new fully connected layers for online training
def init_networks(sess):
"""Load the pre-trained networks, then replace the fc6"""
fc4_weight, fc4_biase, fc5_weight, fc5_biase = load_model(sess)
conv3_feature = tf.get_default_graph().get_tensor_by_name('conv3/conv3:0')
image_tensor = tf.get_default_graph().get_tensor_by_name('images:0')
# Add new fully connected layers for online training
with tf.variable_scope('input'):
conv3_input = tf.placeholder(
tf.float32, shape=[None, 3, 3, 512], name='conv3_input'
)
label_input = tf.placeholder(tf.int32, name='label')
with tf.variable_scope('online_fc4'):
reshaped = tf.reshape(conv3_input, [-1, 4608])
weights = networks._variable_init_from_constant('weights',
shape=[4608, 512],
val=fc4_weight,
wd=5e-4)
biases = networks._variable_on_cpu('biases', shape=[512], initializer=tf.constant_initializer(fc4_biase))
online_fc4 = tf.nn.relu(tf.matmul(reshaped, weights) + biases)
drop4 = tf.nn.dropout(online_fc4, 0.5)
with tf.variable_scope('online_fc5'):
weights = networks._variable_init_from_constant('weights',
shape=[512, 512],
val=fc5_weight,
wd=5e-4)
biases = networks._variable_on_cpu('biases', shape=[512], initializer=tf.constant_initializer(fc5_biase))
online_fc5 = tf.nn.relu(tf.matmul(drop4, weights) + biases)
drop5 = tf.nn.dropout(online_fc5, 0.5)
with tf.variable_scope('online_fc6'):
weights = networks._variable_with_weight_decay('weights',
shape=[512, 2],
stddev=1e-2,
wd=5e-4)
biases = networks._variable_on_cpu('biases', shape=[2], initializer=tf.constant_initializer(0))
online_fc6 = tf.nn.relu(tf.matmul(drop5, weights) + biases)
logits = tf.nn.softmax(online_fc6, name='online_logits')
with tf.variable_scope('online_cross_entropy'):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=label_input, logits=logits
)
with tf.name_scope('total'):
cross_entropy_mean = tf.reduce_mean(cross_entropy)
with tf.variable_scope('train'):
opt = tf.train.AdamOptimizer(0.0001)
grads = opt.compute_gradients(cross_entropy_mean)
for i in range(len(grads)):
grad, var = grads[i]
if var.name.find('online_fc6') != -1:
grads[i] = (grad * 10, var)
apply_grad_op = opt.apply_gradients(grads)
return image_tensor, conv3_feature, conv3_input, label_input, logits, apply_grad_op, cross_entropy_mean

















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









