



一、问题现象
现网遇到了一个慢sql,类似如下:
其中a表查询出的数据实际大约是5w条,b表总数据量大约是2k条,执行了大约12秒,且a.id是主键,b.user_id建有索引
select count(1)
from t_user a left join t_user_info b on a.id = b.user_id
where a.age > 18
二、定位过程
1. 使用explain 查看执行计划:
explain select count(1)
from t_user a left join t_user_info b on a.id = b.user_id
where a.age > 10

发现b表未能执行索引(虽然possible_keys = index_user_id, 但key实际为空)
2. 又查看了下建表语句,确认t_user_info的字段user_id确实是存在有索引的
show create table t_user;
show create table t_user_info;
CREATE TABLE `t_user` (
`id` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '主键id',
`name` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_age` (`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `t_user_info` (
`id` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`address` varchar(256) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`user_id` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
KEY `index_user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
3. 使用强制索引 force index(index_user_id) ,但仍然未能走索引
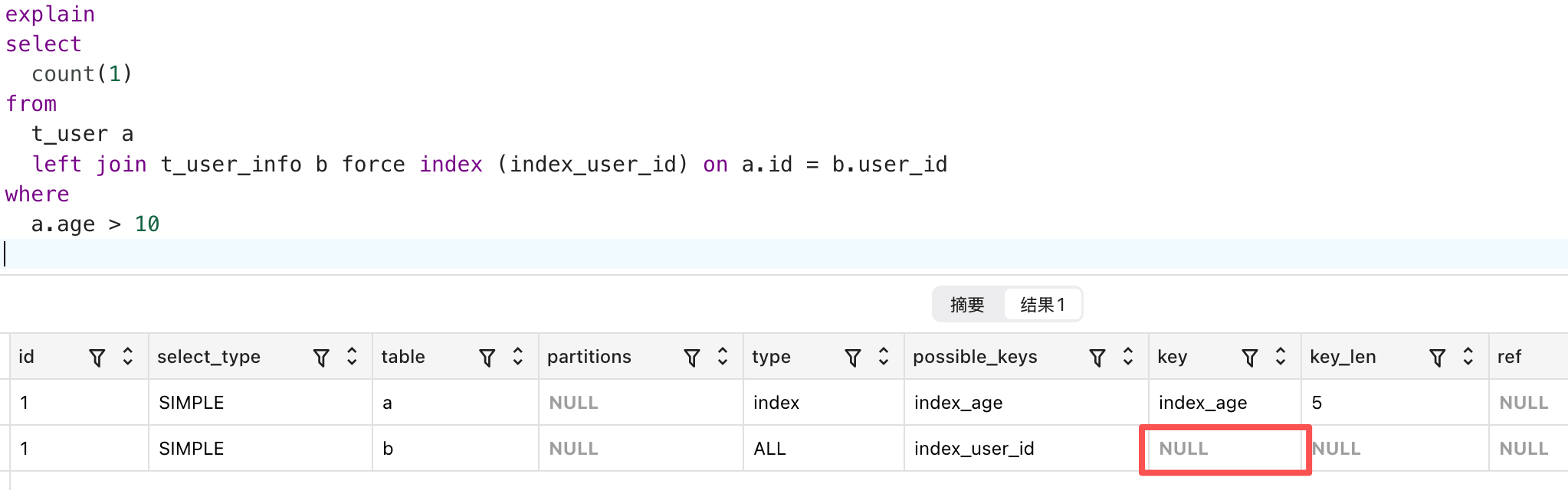
4. 最后在网上查看了资料,发现a表id的排序规则是utf8mb4_bin, b表user_id的排序规则是utf8mb4_general_ci,于是将b表的排序规则重新修改了下:
ALTER TABLE `t_user_info`
MODIFY COLUMN `user_id` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL;
5. 再次查看执行计划
b表终于走上了索引,性能问题迎刃而解。

四、总结
4.1 字符集、排序规则的基本概念
-
字符集(Character Set)定义了字符串的编码方式,即如何将字符映射为二进制数据(字节序列)。例如:
utf8:支持基本 Unicode 字符(3 字节编码,不支持 emoji)。utf8mb4:utf8的超集(4 字节编码,支持 emoji 和更多罕见字符,推荐使用)。latin1:单字节编码,支持英文等西欧字符。
-
排序规则(Collation)定义了字符串的比较和排序规则,依赖于字符集(一个字符集可对应多个排序规则)。例如
utf8mb4的常见排序规则:utf8mb4_general_ci:通用排序,不区分大小写(A和a视为相等),性能较好。utf8mb4_unicode_ci:基于 Unicode 标准排序,更准确但性能略低。utf8mb4_bin:二进制比较,区分大小写和字符编码(A和a视为不同)。
4.2 MySQL 中的字符集 / 排序规则层级
MySQL 从服务器级到字段级有多层设置,优先级从低到高为:服务器级 → 数据库级 → 表级 → 字段级(低层级未指定时,会继承高层级的默认值)。
4.3 查看当前设置
-
查看服务器级默认值
SHOW VARIABLES LIKE 'character_set_server'; -- 服务器默认字符集 SHOW VARIABLES LIKE 'collation_server'; -- 服务器默认排序规则 -
查看数据库级设置
SELECT schema_name, default_character_set_name, default_collation_name FROM information_schema.schemata WHERE schema_name = '数据库名'; -
查看表级设置
SHOW TABLE STATUS LIKE '表名'; -- 结果中 Collation 字段为表的默认排序规则 -
查看字段级设置
-
SELECT column_name, -- 字段名 character_set_name, -- 字符集 collation_name -- 排序规则 FROM INFORMATION_SCHEMA.COLUMNS WHERE table_schema = '数据库名' -- 替换为实际数据库名 AND table_name = '表名'; -- 替换为实际表名
4.4 设置字符集和排序规则
1. 创建数据库时指定
CREATE DATABASE 数据库名
CHARACTER SET utf8mb4
COLLATE utf8mb4_general_ci;
2. 创建表时指定(表级)
CREATE TABLE 表名 (
id INT,
name VARCHAR(50)
) ENGINE=InnoDB
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
3. 为字段单独指定(字段级)
CREATE TABLE 表名 (
id INT,
name VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin, -- 字段级设置
email VARCHAR(100) -- 继承表级设置
);
4. 修改已有对象的设置
- 修改数据库:
ALTER DATABASE 数据库名 CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; - 修改表(仅影响新字段,已有字段需单独修改):
ALTER TABLE 表名 CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; - 修改字段:
ALTER TABLE 表名 MODIFY 字段名 VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
4.5 最佳实践
- 优先使用
utf8mb4:避免utf8不支持 emoji 和特殊字符的问题。 - 统一字符集:整个数据库尽量使用同一字符集(如全库
utf8mb4),减少兼容问题。 - 排序规则选择:
- 一般场景用
utf8mb4_general_ci(性能好)。 - 需精确排序(如多语言)用
utf8mb4_unicode_ci。 - 区分大小写时用
utf8mb4_bin。
- 一般场景用
- 创建时显式指定:不依赖默认值,避免环境差异导致的问题。
4.6 常见问题
- 插入 emoji 失败:表或字段字符集不是
utf8mb4导致,需修改为utf8mb4。 - 排序结果不符合预期:检查排序规则是否正确(如区分大小写需用
_bin)。 - 字符集转换乱码:转换时确保原数据与目标字符集兼容,建议先备份数据。

















 8934
8934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









