




 本文围绕数据结构中的串和树展开。串部分介绍了字符串特性、操作及匹配算法,如朴素匹配和KMP算法。树部分阐述了树的存储结构、二叉树特性与遍历,还涉及树、森林、二叉树的相互转化,以及哈夫曼树和堆的相关知识,堆可高效解决Top - k问题。
本文围绕数据结构中的串和树展开。串部分介绍了字符串特性、操作及匹配算法,如朴素匹配和KMP算法。树部分阐述了树的存储结构、二叉树特性与遍历,还涉及树、森林、二叉树的相互转化,以及哈夫曼树和堆的相关知识,堆可高效解决Top - k问题。
串
串概述
| 串的基本概念 | |
| 定义 | 由零个或者多个字符组成的有限序列又叫字符串。 |
| 串长 | 字符串中字符个数。空格串只含有空格,空串不含有任何字符。 |
| 串比较 | 串的比较是比较对应位置上字符大小。 |
| 存储 | 顺序存储(数组)。链式存储:链式线性表。 |
字符串特性及操作
字符串常量:字符串字面量始终要追加空字符('\0'、L'\0'、char16_t() 等):因此,字符串字面量 "Hello" 是 const char[6],并保有字符 'H'、'e'、'l'、'l'、'o' 及 '\0'。
字符串字面量拥有静态存储期,从而在程序生存期间存在于内存中。字符串字面量可用与初始化字符数组。若数组初始化类似 char str[] = "foo";,则 str 将含有字符串 "foo" 的副本。允许但不要求编译器将相等或重叠的字符串字面量的存储合并起来。这意味着以指针比较时,相同的字符串字面量比较时可能或可能不相等。编译器有可能会把两个相同的字符串字面量优化为存到同一个地方,但不一定会这样做
#include <iostream>
char array1[] = "Foo" "bar";
// 同
char array2[] = { 'F', 'o', 'o', 'b', 'a', 'r', '\0' };
const char* s1 = R"foo(
Hello
World //原始字符串字面量的定义为:R “xxx(raw string)xxx”.其中原始字符串必须用括号()括起来
//括号的前后所加的字符串会被忽略,且必须在括号两边同时出现。
)foo";
// 同
const char* s2 = "\nHello\nWorld\n";
int main()
{
std::cout << array1 << '\n';
std::cout << array2 << '\n';
std::cout << s1;
std::cout << s2;
}
//结果
Foobar
Foobar
Hello
World
Hello
World
字符串间的赋值:
std::string str1;
std::string str2 { "al" };
// (1) operator=( const basic_string& );
str1 = str2;
std::cout << std::quoted(str1) << ' ' // "al"
<< std::quoted(str2) << '\n'; // "al"
// (2) operator=( basic_string&& );
str1 = std::move(str2);
std::cout << std::quoted(str1) << ' ' // "al"
<< std::quoted(str2) << '\n'; // "" 或 "al" (未指定)
// (3) operator=( const CharT* );
str1 = "beta";
std::cout << std::quoted(str1) << '\n'; // "beta"
// (4) operator=( CharT );
str1 = '!';
std::cout << std::quoted(str1) << '\n'; // "!"
// (5) operator=( std::initializer_list<CharT> );
str1 = {'g','a','m','m','a'};
std::cout << std::quoted(str1) << '\n'; // "gamma"
// (6) operator=( const T& );
str1 = 35U; // equivalent to str1 = static_cast<char>(35U);
std::cout << std::quoted(str1) << '\n'; // "#" (ASCII = 35)
字符串的初始化:
{
{
// string::string()
std::string s="hello";
// string::string(size_type count, charT ch)
std::string s1(4, '=');
std::cout << s1 << '\n'; // "===="
std::string const other("Exemplary");
// string::string(string const& other, size_type pos, size_type count)
std::string s2(other, 0, other.length()-1);
std::cout << s2 << '\n'; // "Exemplar"
// string::string(charT const* s, size_type count)
std::string s3("C-style string", 7);
std::cout << s3 << '\n'; // "C-style"
// string::string(charT const* s)
std::string s4("C-style\0string");
std::cout << s4 << '\n'; // "C-style"
char mutable_c_str[] = "another C-style string";
// string::string(InputIt first, InputIt last)
std::string s5(std::begin(mutable_c_str)+8, std::end(mutable_c_str)-1);
std::cout << s5 << '\n'; // "C-style string"
std::string const other1("Exemplar");
std::string s6(other1);
std::cout << s6 << '\n'; // "Exemplar"
// string::string(string&& str)
std::string s7(std::string("C++ by ") + std::string("example"));
std::cout << s7 << '\n'; // "C++ by example"
// string(std::initializer_list<charT> ilist)
std::string s8({ 'C', '-', 's', 't', 'y', 'l', 'e' });
std::cout << s8 << '\n'; // "C-style"
// 重载决议选择 string(InputIt first, InputIt last) [with InputIt = int]
// 这表现为如同调用 string(size_type count, charT ch)
std::string s9(3, std::toupper('a'));
std::cout << s9 << '\n'; // "AAA"
}
字符串元素访问:
| 基本信息 | 示例 | |
| at: 访问指定字符,有边界检查,非法时抛出std::out_of_range |
参数:pos - 要返回的字符位置 返回值:到请求的字符的引用。 异常:若pos>= size() 抛出std::out_of_range 复杂度:常数。
| |
| operator[]:返回到位于指定位置 pos 的字符的引用。不进行边界检查。若 pos > size() ,则行为未定义 |
参数:pos - 要返回的字符位置 返回值:到请求的字符的引用。复杂度:常数。
| |
| front(): 返回到 string 中首字符的引用。若 empty() == true 则行为未定义 |
参数:pos - 要返回的字符位置 返回值:到首字符的引用,等价于 operator[](0) 复杂度:常数。
| |
| back(): 返回字符串中的末字符。若 empty() == true 则行为未定义。 | 参数:pos - 要返回的字符位置
返回值:到首字符的引用,等价于等价于 operator[](size() - 1) 复杂度:常数。
| |
迭代器与容量:
|
begin() 返回可变或常迭代器,取决于 *this 的常性。 cbegin() 始终返回常迭代器。它等价于 const_cast<const basic_string&>(*this).begin() 。 | 返回值:指向首字符的迭代器,复杂度:常数,参数:无
| |
|
end()/cend():返回指向后随字符串末字符的字符的迭代器。此字符表现为占位符,试图访问它导致未定义行为。 |
参数:(无);返回值:指向后随尾字符的字符的迭代器 ;复杂度:常数
| |
| empty(): 检查 string 是否无字符,即是否 begin() == end() 。 |
返回值:若 string 为空则为 true ,否则为 false 。复杂度:常数; 无参
| |
| siez()/length(): 返回 string 中的 CharT 元素数,即 std::distance(begin(), end()) |
返回值:string 中的 CharT 元素数。
| |
| mas_size(): 返回 string 由于保有系统或库实现限制所能保有的最大元素数。 |
返回值: 最大字符数; 复杂度: 常数; 无参
| |
| capacity():返回当前已为字符串分配空间的字符数 |
返回值: 当前分配的存储容量。复杂度: 常数。
| |
基本操作:
| clear():如同通过执行 erase(begin(), end()) 从 string 移除所有字符。 |
参数:(无);返回值:无; 复杂度: 与 string 大小成线性
| |
| insert: 插入字符到 string 中。 |
参数:index - 插入内容到的位置 ;pos - 将插入字符到其前的迭代器 ch - 要插入的字符; count - 要插入的字符数;s - 指向要插入的字符串的指针;str - 要插入的 string;first, last - 要插入字符的范围; index_str - string str 中要插入的首字符位置;
| |
| erase: 从 string 移除指定的字符。 |
参数:index - 要移除的首个字符;count - 要移除的字符数;
| |
|
push_back:后附给定字符 pop_back: 从字符串移除末字符。 等价于 erase(end() - 1, 1) 。若字符串为空则行为未定义。 |
参数: ch - 要后附的字符;返回值: (无);复杂度: 均摊常数。 若操作将导致 size() > max_size() ,则抛出 std::length_error 。pop_back:不抛出异常;
| |
| appen:后附额外字符到字符串。
返回值: *this | 参数:count - 要后附的字符数;pos - 要后附的首个字符下标; ch - 要后附的字符值;first, last - 要后附的字符范围; str - 要后附的 string;s - 指向要后附的字符串的指针; ilist - 拥有要后附的字符的 initializer_listt - 可转换为带要后附的字符的 std::basic_string_view 的对象;
异常: 若因任何原因抛出异常,则此函数无效果(强异常保证)。 (C++11 起)若操作会导致 size() > max_size() ,则抛出 std::length_error 。 | |
| operator+=: 后附额外字符到字符串
返回值: *this |
参数: str - 要后附的 string;ch - 要后附的字符值; 异常: 若因任何原因抛出异常,则此函数无效果(强异常保证)若操作会导致 size() > max_size() ,则抛出 std::length_error 。
| |
| compare: 比较二个字符序列;
返回值: 若 *this 在字典序中先/后出现于参数所指定的字符序列,则为正值/负值。(等价则为零) |
参数: str - 要比较的另一 string;s - 指向要比较的字符串的指针;
异常:接收名为 pos1 或 pos2 的参数的重载若参数在范围外则抛出 std::out_of_range | |
|
starts_with: 检查 string 是否始于给定前缀。 ends_with: 检查 string 是否终于给定后缀 //C++20 新增函数 |
参数: sv - string_view ,可为从另一 std::basic_string 隐式转换的结果 ends: with 参数一致,返回值: string 终于给定后缀则为 true ,否则为 false
| |
| replace:以新字符串替换 [pos, pos + count) 或 [first, last) 所指示的部分; |
参数:pos - 将被替换的子串起始位置;count - 将被替换的子串长度;
| |
| substr: 返回子串 [pos, pos+count) 。若请求的子串越过 string 的结尾,或若 count == npos ,则返回的子串为 [pos, size()); |
参数: pos - 要包含的首个字符的位置;count - 子串的长度; 注解: 如同以 basic_string(data()+pos, count) 构造返回的 string ,这隐含将会默认构造返回的 string 的分配器——新分配器将不是 this->get_allocator() 的副本。 | |
copy: 复制子串 [pos, pos+count) 到 dest 所指向的字符串 |
参数: count - 子串长度;dest - 指向目标字符串的指针;
返回值: 复制的字符数; | |
| swap: 交换内容 |
参数:other - 要与之交换内容的 string
| |
| find: 查找寻找首个等于给定字符序列的子串。搜索始于 pos ,即找到的子串必须不始于 pos 之前的位置 |
参数: str - 要搜索的 string;pos - 开始搜索的位置;count - 要搜索的子串长度;
//若找不到内容则字符串搜索函数返回npos,这是特殊值,等于size_type类型可表示的最大值。准确含义依赖于语境,但通常期待string下标的函数以之为字符串尾指示器,返回string下标的函数以之为错误指示器。 | |
字符串匹配:
朴素匹配
朴素模式匹配从目标字符串初始位置开始,依次分别与Pattern的各个位置的字符比较,如相同,比较下一个位置的字符直至完全匹配;如果不同则跳到目标字符串下一位置继续如此与Pattern比较,直至找到匹配字符串并返回其位置。时间复杂度最坏为O(mn),效率很低。
public class stringoper {
public static void main(String[] args) {
String s="abcdefg";
String str="bc5d";
System.out.println(Index(s, str));
}
public static int Index(String s, String pattern)
{
int index = -1;
boolean match = true;
for (int i = 0, len = s.length() - pattern.length(); i <= len; i++) {
match = true;
for (int j = 0; j < pattern.length(); j++) {
if (s.charAt(i + j) != pattern.charAt(j)) {
match = false;
break;
}
}
if (match) {
index = i;
break;
}
}
return index;
}
}
KMP算法:
KMP算法是一种改进的字符串匹配算法,关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。在BF算法的基础上使用next函数来找出下一次目标函数与Pattern比较的位置,因为BF算法每次移动一位的比较是冗余的,KMP利用Pattern字符重复的特性来排除不必要的比较,从而可以每次移动n位来排除冗余。对于Next函数近似接近O(m),KMP算法的时间复杂度为O(n),所以整个算法的时间复杂度为O(n+m)。
public class stringoper {
public static void main(String[] args) {
stringoper.getNext("abcdef");
System.out.println(stringoper.indexKMP("abcadef", "abc",0));
}
public static int[] getNext(String T){
int[] next = new int[T.length()];
int i = 0;
int j = -1;
next[i] = j;
while(i<T.length()-1){
if(j==-1 || T.charAt(i)==T.charAt(j)){
i++;
j++;
next[i] = j;
}else {
j = next[j];//若字符不相等,则j值进行回溯。
}
}
for (int k = 0; k < next.length; k++) {
System.out.print(next[k]);
}
System.out.println();
return next;
}
public static int indexKMP(String S,String T,int pos){
int i = pos;//表示从主串中第几个字符串开始匹配
int j = 0;//表示从模式串中第几个字符串开始
int[] next = getNext(T);
while(i<S.length()&&j<T.length()){
if (j == -1 || S.charAt(i) == T.charAt(j)) {
i++;
j++;
}
else {//重新开始匹配
j = next[j];//j退回到合适的位置,i值不变
}
}
if (j>=T.length()) {
return i-T.length();
}else {
return 0;
}
}
}
树
树定义及特性
| 定义 | 描述 |
|---|---|
| 树 | n(n=>0)个节点的有限集;N=0时成为空树;有且仅有一个称为根的节点当n>0时,其余节点可分为m(m>0)个互不相交的有限集T1、T2、T3、Tm,其中每个节点又是一棵树,并且称为根的子树。 |
| 节点 | 树的基本单元,每个节点包含值、左子节点指针和右子节点指针。 |
| 节点的度 | 节点拥有的的子树数;树的度是树内个节点的度的最大值 |
| 叶节点 | 度为0的称为终端节点或者叶节点;度不为0的称为非终端节点或者分支节点 |
| 节点关系 | 节点的子树的根称为该节点的孩子, 该节点称为孩子的双亲。同一个双亲的孩子之间称为兄弟。如果将树种节点的各子树看成是从左到右是有次序的,不能互换的,则称该树为有序树,否则称为无序树。 |
| 结点的层次 | 从根开始起根为第一层,根的孩子为第二层,树中结点最大层次成为树的深度或高度。如果树中结点的各子树看做是有序的不能互换的则称该树为有序树否则为无序树。森林是m(m>=0)颗互不相交的树的集合。 |
| 线性结构和树结构对比:线性节点的第一个元素无前驱,树结构的根节点无双亲,且唯一。线性表最后一个元素无后继, 树叶节点无后继,但可以有多个。中间元素一个前驱一个后继, 树节点一个双亲多个孩子。 | |
树的存储结构
双亲表示法:
以一组连续空间存储树的结点,同时每个结点中附设一个指示器指示其双亲结点在数组中的位置。找根容易O(1)找孩子难。
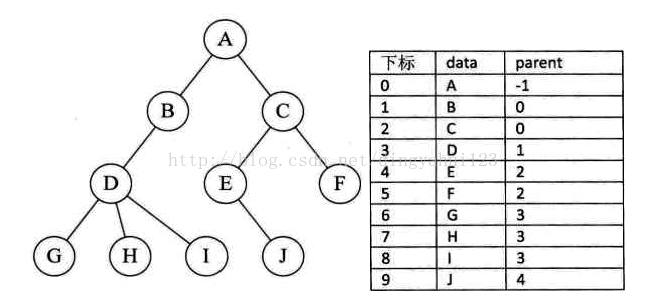
孩子表示法:
把每个节点的孩子节点排列起来,以单链表做存储结构,则n个节点有n个孩子链表,如果是叶子节点则次单链表为空,然后n个头指针又组成一个线性表,采用顺序存储结构,存放进一个一位数组中。

双亲孩子表示法:
是孩子表示法的改进,添加了双亲的存储结构。
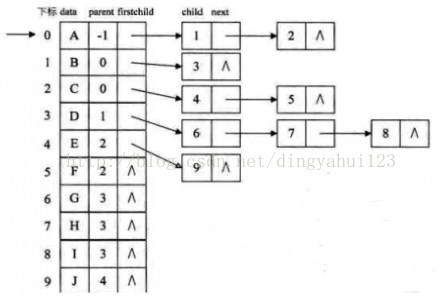
孩子兄弟表示法:
任意一棵树,它的节点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。因此我们设置两个指针分别指向该节点的第一个孩子和此节点的有兄弟。节点结构
| data | firstchild | rightright |
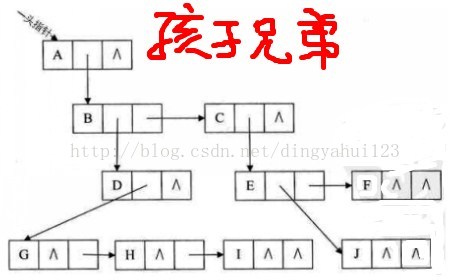
二叉树
二叉树特性
| 定义 | 描述 |
| 二叉树 | n(n>=0)个节点的有限集合;该集合或者为空集(称为空二叉树)或者由一个根节点和两颗互不相交的、分别称为根节点的左子树、右子树的二叉树组成。 |
| 二叉树基本形态 | 空二叉树、只有一个根节点、根节点只有左子树、根节点只有右子树、根节点既有左子树又有右子树。 |
| 满二叉树 | 所有叶节点都在同一层,所以分支节点都有左右子树。 |
| 完全二叉树 | 只有最底层的节点未被填满,且最底层节点尽量靠左填充,可将满二叉树层次编号对比。 |
| 线索二叉树 | 指向前驱或者后继的指针称为线索,加上线索的二叉树链表称为线性链表,相应的二叉树就称为线索二叉树。(n个结点的二叉链表一共2n个指针域,一共n-1条分支数一共2n-(n-1)=n+1个空指针域。) |
| 平衡二叉树 | 任意节点的左子树和右子树的高度之差的绝对值不超过 1 。 |
| 二叉树性质 | 在二叉树的第i层上最多有 |
| 二叉树中如果深度为k,那么最多有 | |
| n0=n2+1 n0表示度数为0的节点 n2表示度数为2的节点 | |
| 在完全二叉树中,具有n个节点的完全二叉树的深度为[ | |
| 若对含 n 个结点的完全二叉树从上到下且从左至右进行 1 至 n 的编号,则对完全二叉树中任意一个编号为 i 的结点:(1) 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点; (2) 若 2i>n,则该结点无左孩子,否则编号为 2i 的结点为其左孩子结点;(3) 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。 |
二叉树的存储
顺序存储结构一般只用于完全二叉树(层次编号对应数组位置);
二叉树的链式存储结构:二叉链表(数据和左右指针域)。
二叉树遍历
| 遍历要求 | 次序、访问、所有结点有且仅有一次被访问遍历次序 |
| 遍历方式 | 前序遍历(根左右)、中序遍历(左根右)、后序遍历(左右根)、层序遍历。 |
| 遍历特性 | 前序和中序、后续与中序(要有中序确定左右)可以确定唯一的一颗二叉树, 前序加后续不可以,因为只确定了根无法确定左右。 |
递归实现
class node {
private int data;
private node leftNode;
private node rightNode;
public node(int data, node leftNode, node rightNode){
this.data = data;
this.leftNode = leftNode;
this.rightNode = rightNode;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public node getLeftNode() {
return leftNode;
}
public void setLeftNode(node leftNode) {
this.leftNode = leftNode;
}
public node getRightNode() {
return rightNode;
}
public void setRightNode(node rightNode) {
this.rightNode = rightNode;
}
}
public class BinaryTree {
/**
* 二叉树的先序、中序、后序遍历(递归方法)
*/
public node init() {//注意必须逆序建立,先建立子节点,再逆序往上建立,
node J = new node(8, null, null);
node H = new node(4, null, null);
node G = new node(2, null, null);
node F = new node(7, null, J);
node E = new node(5, H, null);
node D = new node(1, null, G);
node C = new node(9, F, null);
node B = new node(3, D, E);
node A = new node(6, B, C);
return A; //返回根节点
}
public void printNode(node node){
System.out.print(node.getData());
}
public void theFirstTraver(node root) { //先序遍历
printNode(root);
if (root.getLeftNode() != null) { //使用递归进行遍历左孩子
theFirstTraver(root.getLeftNode());
}
if (root.getRightNode() != null) { //递归遍历右孩子
theFirstTraver(root.getRightNode());
}
}
public void theInOrderTraversal(node root) { //中序遍历
if (root.getLeftNode() != null) {
theInOrderTraversal(root.getLeftNode());
}
printNode(root);
if (root.getRightNode() != null) {
theInOrderTraversal(root.getRightNode());
}
}
public void thePostOrderTraversal(node root) { //后序遍历
if (root.getLeftNode() != null) {
thePostOrderTraversal(root.getLeftNode());
}
if(root.getRightNode() != null) {
thePostOrderTraversal(root.getRightNode());
}
printNode(root);
}
public static void main(String[] args) {
BinaryTree tree = new BinaryTree();
node root = tree.init();
System.out.println("先序遍历");
tree.theFirstTraver(root);
System.out.println("");
System.out.println("中序遍历");
tree.theInOrderTraversal(root);
System.out.println("");
System.out.println("后序遍历");
tree.thePostOrderTraversal(root);
System.out.println("");
}
}
非递归借助栈:
public void theFirstTraversal_Stack(node root) { //先序遍历
Stack<node> stack = new Stack<node>();
node no = root;
while (no != null || stack.size() > 0) { //将所有左孩子压栈
if (no != null) { //压栈之前先访问
printNode(no);
stack.push(no);
no = no.getLeftNode();
} else {
no = stack.pop();
no = no.getRightNode();
}
}
}
public void theInOrderTraversal_Stack(node root) { //中序遍历
Stack<node> stack = new Stack<node>();
node no = root;
while (no != null || stack.size() > 0) {
if (no != null) {
stack.push(no); //直接压栈
no = no.getLeftNode();
} else {
no = stack.pop(); //出栈并访问
printNode(no);
no = no.getRightNode();
}
}
}
public void thePostOrderTraversal_Stack(node root) { //后序遍历
Stack<node> stack = new Stack<node>();
Stack<node> output = new Stack<node>();//构造一个中间栈来存储逆后序遍历的结果
node no = root;
while (no != null || stack.size() > 0) {
if (no != null) {
output.push(no);
stack.push(no);
no = no.getRightNode();
} else {
no = stack.pop();
no = no.getLeftNode();
}
}
while (output.size() > 0) {
printNode(output.pop());
}
}
线索二叉树
在二叉树的结点上加上线索的二叉树称为线索二叉树,对二叉树以某种遍历方式(如先序、中序、后序或层次等)进行遍历,使其变为线索二叉树的过程称为对二叉树进行线索化
树、森林、二叉树的相互转化
树转换成二叉树
步骤是:
(1)加线。就是在所有兄弟结点之间加一条连线;
(2)抹线。就是对树中的每个结点,只保留他与第一个孩子结点之间的连线,删除它与其它孩子结点之间的连线;
(3)旋转。就是以树的根结点为轴心,将整棵树顺时针旋转一定角度,使之结构层次分明。

森林转换为二叉树
森林是由若干棵树组成,可以将森林中的每棵树的根结点看作是兄弟,由于每棵树都可以转换为二叉树,所以森林也可以转换为二叉树。将森林转换为二叉树的步骤是:
(1)先把每棵树转换为二叉树;
(2)第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树的根结点的右孩子结点,用线连接起来。当所有的二叉树连接起来后得到的二叉树就是由森林转换得到的二叉树。

二叉树转换为树
二叉树转换为树是树转换为二叉树的逆过程,其步骤是:
(1)若某结点的左孩子结点存在,将左孩子结点的右孩子结点、右孩子结点的右孩子结点……都作为该结点的孩子结点,将该结点与这些右孩子结点用线连接起来;
(2)删除原二叉树中所有结点与其右孩子结点的连线;(3)整理(1)和(2)两步得到的树,使之结构层次分明。

二叉树转换为森林
二叉树转换为森林比较简单,其步骤如下:
(1)先把每个结点与右孩子结点的连线删除,得到分离的二叉树;
(2)把分离后的每棵二叉树转换为树;(3)整理第(2)步得到的树,使之规范,这样得到森林。
树与森林的遍历
根据树与二叉树的转换关系以及二叉树的遍历定义可以推知,树的先序遍历与其转换的相应的二叉树的先序遍历的结果序列相同;树的后序遍历与其转换的二叉树的中序遍历的结果序列相同;树的层序遍历与其转换的二叉树的后序遍历的结果序列相同。由森林与二叉树的转换关系以及森林与二叉树的遍历定义可知,森林的先序遍历和中序遍历与所转换得到的二叉树的先序遍历和中序遍历的结果序列相同。
哈夫曼树
| 路径 | 树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。 |
| 路径长度 | 路径上的分枝数目称作路径长度。 |
| 树的路径长度 | 从树根到每一个结点的路径长度之和。 |
| 结点的带权路径长度 | 在一棵树中,如果其结点上附带有一个权值,通常把该结点的路径长度与该结点上的权值之积称为该结点的带权路径长度。 |
| 树的带权路径长度 | 如果树中每个叶子上都带有一个权值,则把树中所有叶子的带权路径长度之和称为树的带权路径长度。其中带权路径长度最小的二叉树就称为哈夫曼树或最优二叉树 |
哈夫曼树的构造:


按照构造哈夫曼树得到的编码成为哈夫曼编码。常用于压缩。
堆
堆是满足特定条件的完全二叉树。分为大根堆和小根堆,大顶堆:任意节点的值 ≥ 其子节点的值;小顶堆:任意节点的值 ≤ 其子节点的值;堆因其特点通常用于实现优先队列,最大或最小元素一定是堆顶。堆因其特性插入和删除元素都是O(logn) 因为有可能要调整堆。
Top-k 是一个经典算法问题,可以使用堆数据结构高效解决,时间复杂度为 𝑂(𝑛log𝑘) ,因为总共执行了n 轮入堆和出堆,堆的最大长度为k ,因此时间复杂度为 𝑂(𝑛log𝑘) 。该方法的效率很高,当 k较小时,时间复杂度趋向 𝑂(𝑛) ;当 k 较大时,时间复杂度不会超过 𝑂(𝑛log𝑛) 。





















 到【灌水乐园】发言
到【灌水乐园】发言







