



 这篇博客详细介绍了如何利用飞桨动态图构建和训练一个卷积神经网络(CNN)进行表情分类任务。首先,介绍了数据准备,包括数据集的来源、结构以及如何将数据划分为训练集和验证集。接着,讲解了CNN网络结构,包括卷积层、池化层的作用和工作原理。然后,展示了模型训练和评估的步骤,包括模型的构建、训练循环、损失计算和精度评估。最后,进行了模型预测并给出了预测示例。
这篇博客详细介绍了如何利用飞桨动态图构建和训练一个卷积神经网络(CNN)进行表情分类任务。首先,介绍了数据准备,包括数据集的来源、结构以及如何将数据划分为训练集和验证集。接着,讲解了CNN网络结构,包括卷积层、池化层的作用和工作原理。然后,展示了模型训练和评估的步骤,包括模型的构建、训练循环、损失计算和精度评估。最后,进行了模型预测并给出了预测示例。
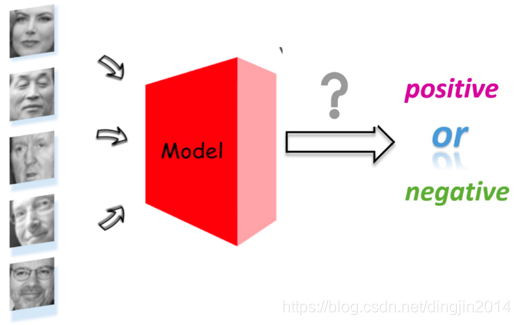
本次案例我们讲解的是如何使用飞桨动态图版本实现一个表情分类任务。在本次案例中,我们可以简单地将人脸表情分类视为一个图像分类任务。也就是说,向模型输入一张表情图像,模型能够对表情的类别进行识别并输出类别结果,如下图所示。
案例中使用的数据均来自互联网公开数据集。该数据集中包含positive和negative两种表情,共7200余张图片,图片尺寸为64*64(大部分为单通道图像,个别图像为3通道)的灰度图像,在实践过程中,我们将数据集按照1:9的比例划分为验证集和训练集。数据图像示例如下。

在本实践中,我们采用的是卷积神经网络(Convolution Neural Network,简称CNN)。卷积神经网络(CNN)是深度学习的一个经典网络模型,它可以看作是深度神经网络(DNN)的一种特殊形式。卷积神经网络主要由卷积层、池化层和全联接层三种网络层构成,在卷积层与全联接层后通常会接激活函数。
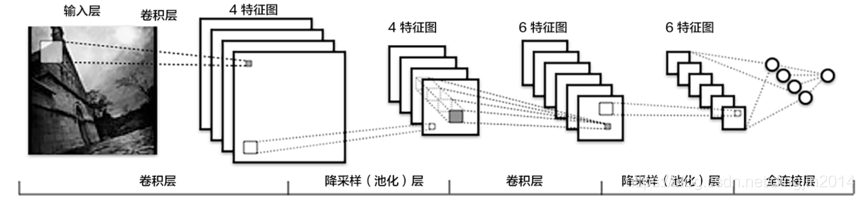
CNN网络结构示例如下图所示。
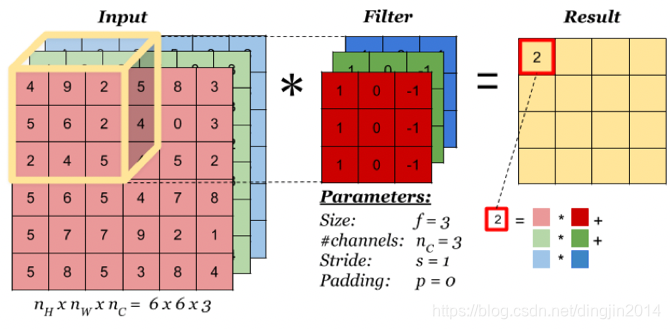
卷积层会对输入的特征图(或原始数据)进行卷积操作,输出卷积后产生的特征图。卷积层是卷积神经网络的核心部分。输入到卷积层的特征图是一个三维数据,不仅有宽、高两个维度,还有通道维度上的数据,因此输入特征图和卷积核可用三维特征图表示。如下图所示,对于一个(3,6,6)的输入特征图,卷积核大小为(3,3,3),输出大小为(1,4,4),当卷积核窗口滑过输入时,卷积核与窗口内的输入元素作乘加运算,并将结果保存到输出相应的位置。
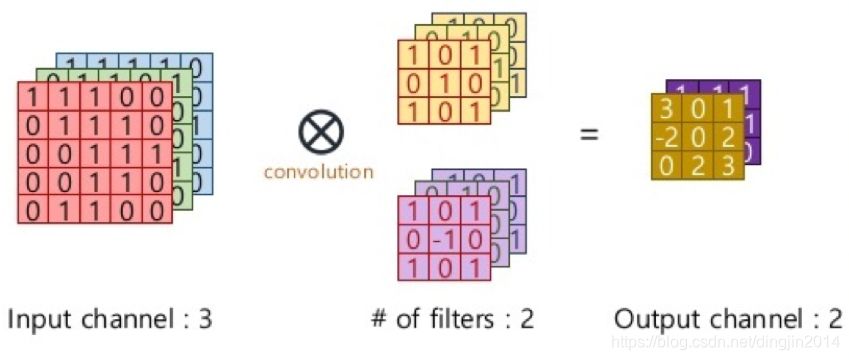
上图中卷积操作输出了一张特征图,即通道数为1的特征图,而一张特征图包含的特征数太少,在大多数计算机视觉任务中是不够的,所以需要构造多张特征图,而输入特征图的通道数又与卷积核通道数相等,一个卷积核只能产生一张特征图,因此需要构造多个卷积核。在RGB彩色图像上使用多个卷积核进行多个不同特征的提取,示意图如下:
池化层
池化层的作用是对网络中的特征进行选择,降低特征数量,从而减少参数数量和计算开销。最常见的池化操作为最大池化或平均池化。如下图所示,采用了最大池化操作,对邻域内特征点取最大值作为最后的特征值。
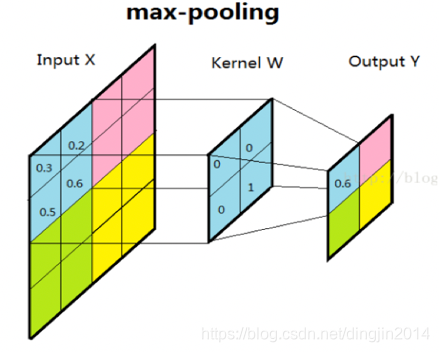
最常见的池化层使用大小为2×2,步长为2的滑窗操作,有时窗口尺寸为3,更大的窗口尺寸比较罕见,因为过大的滑窗会急剧减少特征的数量,造成过多的信息损失。
了解了CNN的网络结构后,接下来我们将在AI Studio平台上利用飞桨动态图搭建一个简单的CNN网络模型,实现表情分类任务。
步骤1:导入所需的包和参数配置
##导入所需的包
import os
import zipfile
import random
import json
import cv2
import numpy as np
from PIL import Image
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import Linear
from paddle.fluid.dygraph import Pool2D,Conv2D
import matplotlib.pyplot as plt
'''
参数配置
'''
train_parameters = {
"input_size": [1, 32, 32], #输入图片的shape
"class_dim": -1, #分类数
"src_path":"data/data33766/face_data.zip", #原始数据集路径
"target_path":"/home/aistudio/data/dataset", #要解压的路径
"train_list_path": "./train_data.txt", #train_data.txt路径
"eval_list_path": "./val_data.txt", #eval_data.txt路径
"label_dict":{}, #标签字典
"readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"num_epochs": 100, #训练轮数
"train_batch_size": 32, #训练时每个批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.001 #超参数学习率
}
}
步骤2:数据准备
在AI Studio项目中,数据集是以压缩包的形式挂载在data/data33766目录下的,我们定义unzip_data()函数对数据进行解压缩,代码如下:
def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至data/dataset目录下
'''
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
else:
print("文件已解压")
其中参数src_path为压缩包路径,target_path为解压的后的数据存储路径。当然,大家也可以用Linux命令unzip 进行解压。
除此之外,我们需要将数据分为训练数据和验证数据,分别用于模型的训练和评估。因此,在这里我们定义了get_data_list()函数,代码如下。
def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
#存放所有类别的信息
class_detail = []
#获取所有类别保存的文件夹名称
data_list_path=target_path
class_dirs = os.listdir(data_list_path)
if '__MACOSX'in class_dirs:
class_dirs.remove('__MACOSX')
if '.ipynb_checkpoints' in class_dirs:
class_dirs.remove('.ipynb_checkpoints')
# #总的图像数量
all_class_images = 0
# #存放类别标签
class_label=0
# #存放类别数目
class_dim = 0
# #存储要写进val.txt和train.txt中的内容
trainer_list=[]
eval_list=[]
# #读取每个类别,['positive', 'negative']
for class_dir in class_dirs:
if class_dir != ".DS_Store":
class_dim += 1
#每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
#统计每个类别有多少张图片
class_sum = 0
#获取类别路径
path = os.path.join(data_list_path,class_dir)
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths: # 遍历文件夹下的每个图片
if img_path =='.DS_Store':
continue
name_path = os.path.join(path,img_path) # 每张图片的路径
if class_sum % 10 == 0: # 每10张图片取一个做验证数据
eval_sum += 1 # test_sum为测试数据的数目
eval_list.append(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
trainer_list.append(name_path + "\t%d" % class_label + "\n")
class_sum += 1 #每类图片的数目
all_class_images += 1 #所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir #类别名称
class_detail_list['class_label'] = class_label #类别标签
class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
class_detail.append(class_detail_list)
#初始化标签列表
train_parameters['label_dict'][str(class_label)] = class_dir
class_label += 1
#初始化分类数
train_parameters['class_dim'] = class_dim
print(train_parameters)
#乱序
random.shuffle(eval_list)
with open(eval_list_path, 'a') as f:
for eval_image in eval_list:
f.write(eval_image)
random.shuffle(trainer_list)
with open(train_list_path, 'a') as f2:
for train_image in trainer_list:
f2.write(train_image)
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = data_list_path #文件父目录
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(train_parameters['readme_path'],'w') as f:
f.write(jsons)
print ('生成数据列表完成!')
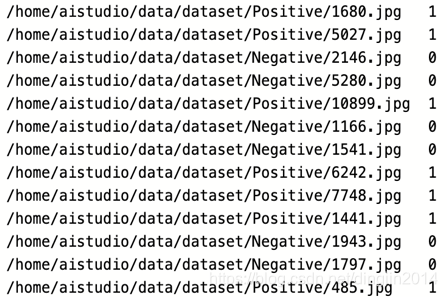
get_data_list()函数的主要功能是遍历图像数据,并按照10:1的比例生成数据列表,同时统计数据集中的类别数、各类别数据数量、标签等信息,存储在readme.json文件中。train_data.txt、val_data.txt中存储的是分别用于训练和验证的数据路径和对应的标签。train_data.txt的数据格式如下图所示,val_data.txt格式与此类似。
接下来,我们定义一个用于获取图片数据的数据提供器data_reader(),它的作用是根据数据列表读取图片并对图像进行尺寸变化和归一化处理,最终返回处理后的图片数据和图片标签(即0、1)。代码如下所示。
def data_reader(file_list):
def reader():
with open(file_list, 'r') as f:
lines = [line.strip() for line in f]
for line in lines:
img_path, lab = line.strip().split('\t')
img = Image.open(img_path)
img = img.resize((32, 32), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img/255.0
yield img, int(lab)
return reader
定义好了数据准备阶段所需的函数之后,我们对参数进行初始化,调用定义好的函数,完成数据解压、数据列表生成,并利用data_reader()简洁地得到用于训练和测试的数据提供提供器train_reader()和test_reader(),具体代码如下所示。
'''
参数初始化
'''
src_path=train_parameters['src_path']
target_path=train_parameters['target_path']
train_list_path=train_parameters['train_list_path']
eval_list_path=train_parameters['eval_list_path']
batch_size=train_parameters['train_batch_size']
'''
解压原始数据到指定路径
'''
unzip_data(src_path,target_path)
'''
划分训练集与验证集,乱序,生成数据列表
'''
#每次生成数据列表前,首先清空train.txt和eval.txt
with open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表
get_data_list(target_path,train_list_path,eval_list_path)
'''
构造数据提供器
'''
train_reader = paddle.batch(data_reader(train_list_path),
batch_size=batch_size,
drop_last=True)
eval_reader = paddle.batch(data_reader(eval_list_path),
batch_size=batch_size,
drop_last=True)
步骤2:网络配置
数据准备工作完成之后,我们开始根据前面已经介绍过的CNN网络构建我们自己的网络结构,在这里我们定义为MyCNN。首先,在__init__方法中对每层网络进行定义,然后在forward方法中对网络的执行进行定义。代码示例如下(大家可自行更改和调优):
#定义网络
class MyCNN(fluid.dygraph.Layer):
def __init__(self):
super(MyCNN,self).__init__()
self.hidden1 = Conv2D(1,32,3,1)
self.hidden2 = Conv2D(32,64,3,1)
self.hidden3 = Pool2D(pool_size=2,pool_type='max',pool_stride=2)
self.hidden4 = Conv2D(64,128,3,1)
self.hidden5 = Linear(128*12*12,2,act='softmax')
def forward(self,input):
x = self.hidden1(input)
x = self.hidden2(x)
x = self.hidden3(x)
x = self.hidden4(x)
x = fluid.layers.reshape(x, shape=[-1, 128*12*12])
y = self.hidden5(x)
return y
步骤3:模型训练
定义好CNN网络模型之后,接下来,我们用飞桨的DyGraph模式来对模型进行训练。
我们首先需要实例化模型,并且使用train()方法切换至训练模型(默认也是训练模式)。因为训练模式下,DyGraph在运行前向网络的时候会自动求导并添加反向网络,而使用eval()方法可切换至评估模式,在评估模式下, DyGraph只需要执行前向的预测网络,不需要进行自动求导并执行反向网络。除此之外,还需要定义要使用的优化方法和学习率、迭代次数、以及训练轮数。
#用动态图进行训练
with fluid.dygraph.guard():
model = MyCNN()
model.train() #训练模式
opt=fluid.optimizer.SGDOptimizer(learning_rate=train_parameters['learning_strategy']['lr'], parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
epochs_num = train_parameters['num_epochs'] #迭代次数
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(1,32,32) for x in data], np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%20==0:
Batch = Batch+20
Batchs.append(Batch)
all_train_loss.append(avg_loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),'MyCNN')#保存模型
我们需要注意的是,与静态图不同,在训练循环中我们需要调用avg_loss.backward()方法来执行反向传播。训练结束后,调用fluid.save_dygraph(model.state_dict(),'MyCNN')保存模型。
步骤4:模型评估
训练完成后,我们就可以用保存好的模型在验证集上进行预测,通过在验证集上的预测结果来评估模型训练效果。在这里,我们使用fluid.load_dygraph()获取保存好的模型参数,用model.load_dict()对模型参数进行加载。因为是对模型训练效果的评估,所以需要调用eval()方法切换至评估模式。
#模型评估
with fluid.dygraph.guard():
accs = []
model_dict, _ = fluid.load_dygraph('MyCNN')
model = MyCNN()
model.load_dict(model_dict) #加载模型参数
model.eval() #评估模式
for batch_id,data in enumerate(eval_reader()):#测试集
images=np.array([x[0].reshape(1,32,32) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)
acc=fluid.layers.accuracy(predict,label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)
步骤5:模型预测
当我们对模型效果比较满意时,我们就可以用模型进行真实预测了。
在开始预测之前,我们需要对一张真实的表情图片进行预处理,使其格式与训练图像的格式(通道数、尺寸)保持一致。在这里我们定义load_image()函数实现对图片的预处理。
#读取预测图像,进行预处理
def load_image(path):
img = cv2.imread(path)
gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray_image = cv2.resize(gray_image,(32,32))
gray_image = gray_image.reshape(1,32,32)
gray_image = np.array(gray_image).astype('float32')
gray_image = gray_image/255.0
return gray_image
定义load_image()函数后,我们可以使用与之前相同的方法实例化模型、加载模型参数以及切换评估模式,然后利用load_image()逐一读取分割后的图片并图片数据喂入模型进行预测,最后按顺序将预测结果输出即可得到表情分类的结果。
#构建预测动态图过程
with fluid.dygraph.guard():
LABEL = train_parameters['label_dict']
print(train_parameters['label_dict'])
infer_path = 'face_img.png'
model=MyCNN()#模型实例化
model_dict,_=fluid.load_dygraph('MyCNN')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
infer_img = load_image(infer_path)
infer_img=np.array(infer_img).astype('float32')
infer_img=infer_img[np.newaxis, :]
infer_img = fluid.dygraph.to_variable(infer_img)
result=model(infer_img)
print(result.numpy())
display(Image.open('face_img.png'))
print(LABEL[str(np.argmax(result.numpy()))])
运行结果如下:

至此,恭喜您!已经成功使用飞桨动态图搭建了一个简单的卷积神经网络。本实践代码、视频及配套文档已发布在AI Studio课程里面,请扫描下方二维码或点击链接,进入学习:
https://aistudio.baidu.com/aistudio/course/introduce/1436
扫码进入课程学习~


















 3226
3226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









