




 本文详细解释了准确率、精确率、召回率及F-measure等评估指标的概念及其计算方式,并针对目标检测场景给出了具体的应用说明。
本文详细解释了准确率、精确率、召回率及F-measure等评估指标的概念及其计算方式,并针对目标检测场景给出了具体的应用说明。
准确率、精确率、召回率和 F 值是在鱼龙混杂的环境中,选出目标的重要评价指标。不妨看看这些指标的定义先:
TP-将正类预测为正类
FN-将正类预测为负类
FP-将负类预测为正类
TN-将负类预测为负类
准确率(Accuracy):
准确度:正例和负例中预测正确数量占总数量的比例,用公式表示:

精确率(precision):

也叫作查准率。即正确预测为正的占全部预测为正的比例。个人理解:真正正确的占所有预测为正的比例,就是你以为的正样本,到底猜对了多少.。
召回率 (recall):

也叫作查全率。即正确预测为正的占全部实际为正的比例。个人理解:真正正确的占所有实际为正的比例,就是真正的正样本,到底找出了多少.。
F-Measure是Precision和Recall加权调和平均:

当  的时候 , 则称为 F1。
的时候 , 则称为 F1。
F1值为算数平均数除以几何平均数,且越大越好,将Precision和Recall的上述公式带入会发现,当F1值小时,True Positive相对增加,而false相对减少,即Precision和Recall都相对增加,即F1对Precision和Recall都进行了加权。

在目标检测算法中,当一个检测结果(detection)被认为是True Positive时,需要同时满足下面三个条件:
1,Confidence Score > Confidence Threshold
2,预测类别匹配(match)真实值(Ground truth)的类别
3,预测边界框(Bounding box)的IoU大于设定阈值,如0.5
不满足条件2或条件3,则认为是False Positive。
TP (True Positive):一个正确的检测,检测的IOU ≥ threshold。即预测的边界框(bounding box)中分类正确且边界框坐标正确的数量。
FP (False Positive):一个错误的检测,检测的IOU < threshold。即预测的边界框中分类错误或者边界框坐标不达标的数量,即预测出的所有边界框中除去预测正确的边界框,剩下的边界框的数量。
FN (False Negative):一个没有被检测出来的ground truth。所有没有预测到的边界框的数量,即正确的边界框(ground truth)中除去被预测正确的边界框,剩下的边界框的数量。
Precision (准确率 / 精确率/ 查准率):准确率是模型只找到相关目标的能力,等于TP/(TP+FP)。即模型给出的所有预测结果中命中真实目标的比例。
Recall (召回率、查全率):,召回率是模型找到所有相关目标的能力,等于TP/(TP+FN)。即模型给出的预测结果最多能覆盖多少真实目标。
Precision 分子:目标检测预测出来正确的框,分母:目标检测预测出所有的框
Recall 分子:目标检测预测出来正确的框,分母就是真实目标的框
Map(Mean Average Precision,平均准确率)
在目标检测任务中,AP(Average Precision,平均精度)是一个重要的评估指标,它综合了Precision(精确率)和Recall(召回率),用于评估模型在不同置信度阈值下的性能。AP值的计算过程如下:
1. 准备数据
- 预测结果:模型对测试集中的每个图像进行预测,输出每个检测框的类别、置信度分数和边界框坐标。
- 真实标签:每个图像的真实标注,包括每个物体的类别和边界框坐标。
2. 计算IoU
- IoU(Intersection over Union,交并比):用于评估预测框和真实框的重合程度。计算公式为:

- 设定IoU阈值:通常设定一个IoU阈值(如0.5),如果预测框与真实框的IoU大于或等于这个阈值,则认为该预测是正确的(True Positive,TP),否则是错误的(False Positive,FP)。
3. 排序预测结果
- 按置信度排序:将所有预测结果按照置信度分数从高到低排序。
4. 计算Precision和Recall
- 初始化计数器:TP(真正例数)、FP(假正例数)和FN(假反例数)。
- 遍历排序后的预测结果:
- 对于每个预测结果,检查其是否为TP或FP。
- 更新TP和FP计数器。
- 计算当前的Precision和Recall,如上图所示
-
- 将每个置信度阈值下的Precision和Recall记录下来。
5. 绘制PR曲线
- PR曲线:以Recall为横轴,Precision为纵轴,绘制PR曲线。
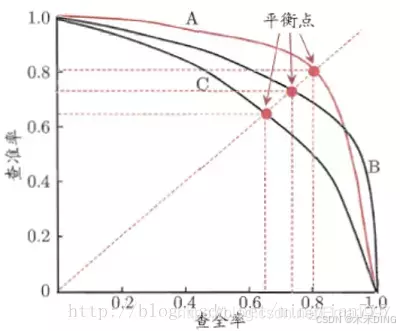
6. 计算AP
- AP的计算方法:AP值是PR曲线下的面积。常见的计算方法有两种:
- 11点插值法:在Recall为0, 0.1, 0.2, ..., 1.0的11个点上,计算每个点对应的最高Precision值,然后取这些值的平均。
-

所有点插值法:在所有Recall值上,计算每个点对应的最高Precision值,然后对这些值进行积分。

其中 是是Recall的值,
是是Recall的值, 是是在Recall为
是是在Recall为 时的Precision值。
时的Precision值。
7. 计算mAP
- mAP(Mean Average Precision):对于多类别目标检测任务,计算每个类别的AP值,然后取所有类别的平均值。
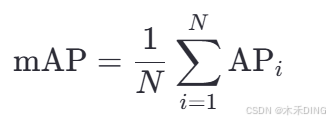
- 其中,N 是类别的总数,
是第 i 个类别的AP值。
总结
AP值通过综合Precision和Recall,提供了对模型在不同置信度阈值下性能的全面评估。mAP则是多类别目标检测任务中常用的综合评估指标,能够反映模型在各个类别上的整体性能。
【参考文献】
准确率、精确率、召回率、F1值、ROC/AUC整理笔记_京局京段蓝白猪的博客-优快云博客_精确度和召回率
准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F值(F-Measure)、AUC、ROC的理解_千寻~的博客-优快云博客_准确率
https://www.jianshu.com/p/fd9b1e89f983

















 5833
5833



 到【灌水乐园】发言
到【灌水乐园】发言








