




 本文介绍了人脸检测算法MTCNN,重点讨论了最小人脸尺寸参数的作用和图像金字塔的应用。通过理解P-Net的相对偏移计算以及训练与推理阶段的不同处理方式,解析了MTCNN如何高效地进行人脸检测。
本文介绍了人脸检测算法MTCNN,重点讨论了最小人脸尺寸参数的作用和图像金字塔的应用。通过理解P-Net的相对偏移计算以及训练与推理阶段的不同处理方式,解析了MTCNN如何高效地进行人脸检测。
最近在一次交流活动中,再次听别人讲人脸检测算法mtcnn,虽然以前也断断续续听过两次,对于一些技术细节仍不清楚,为了解决自己的困惑,笔者又重拾起这一算法,在认真研读论文和思考后有了新的理解,于是记录下来。下文主要解释mtcnn中min_face_size这个参数是怎么起作用的、如何使用图像金字塔等,希望能对大家有所帮助。
1 相关知识点
1.1 “network in network”
作为新加坡国立大学在2013年发表在CVPR上的一篇文章,它首次提出了“Global Average Pooling”,也即将feature map转换为score map。
1.2 OverFeat
该文章的全名为“OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks”。该方法是ILSVRC2013检测任务的冠军算法,这里重点介绍“how a multiscale and sliding window approach can be efficiently implemented within a ConvNet”。对于非全卷积网络,如果设置滑动窗口尺寸为 m × n m\times n m×n,那么对于更大的输入图像,必须对每一个滑动窗口,分别使用前向推理,这样比较耗时。全卷积网络中用 “Global Average Pooling”代替 “Fully Connected Layer”,所以网络的输入图像的尺寸可以任意。
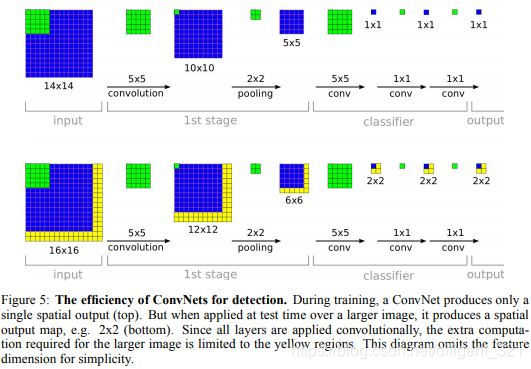
由图可见,输出feature map的每一个空间位置,对应了输入图像的一个窗(感受野),并且,前向推理是对整个的feature map做卷积,所以所有滑动窗共享了计算量。
2 mtcnn
mtcnn,全称为“Multi-task Cascaded Convolutional Networks”,作为一种人脸检测和关键点(5个点)算法,它以速度快、精度高而广为人知。尽管后面有更好的人脸检测算法,比如FaceBoxes算法,但是mtcnn的精度已经能够满足通常的人脸检测要求,所以用的最广泛。
2.1 最小人脸尺寸
在解释最小人脸尺寸之前,先贴原文中的一幅网络结构图,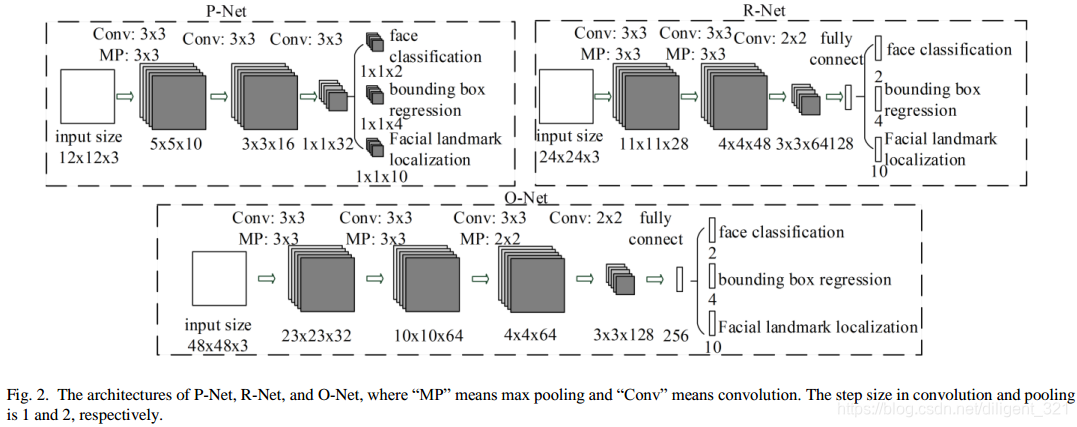
显然,P-Net是全卷积网络,且最小输入尺寸为 12 × 12 12\times 12 12×12。假设在推理阶段的输入图像尺寸为 100 × 100 100\times 100 100×100,构造图像金字塔,使得图像最小尺寸为 20 × 20 20\times 20 20×20,将不同尺寸的图像按照等比例缩放,原文中设置缩放因子为0.6,缩放后的图作为网络的输入,那么,最小尺寸的图像缩放后尺寸为 12 × 12 12\times 12 12×12,输出的特征图尺寸为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2432
2432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









