




 本文介绍了滴滴如何大规模使用Kafka,并探讨了Kafka的设计理念和演进历程,从0.7到2.8.0版本的重大改进。Kafka从消息引擎逐渐转变为分布式流处理平台,提供了Kafka Streams等功能。文章还讨论了版本选择的建议,以及Confluent如何基于Kafka提供增值服务。最后,提到了国内开源项目LogI-KafkaManager在Kafka管理和优化上的贡献。
本文介绍了滴滴如何大规模使用Kafka,并探讨了Kafka的设计理念和演进历程,从0.7到2.8.0版本的重大改进。Kafka从消息引擎逐渐转变为分布式流处理平台,提供了Kafka Streams等功能。文章还讨论了版本选择的建议,以及Confluent如何基于Kafka提供增值服务。最后,提到了国内开源项目LogI-KafkaManager在Kafka管理和优化上的贡献。
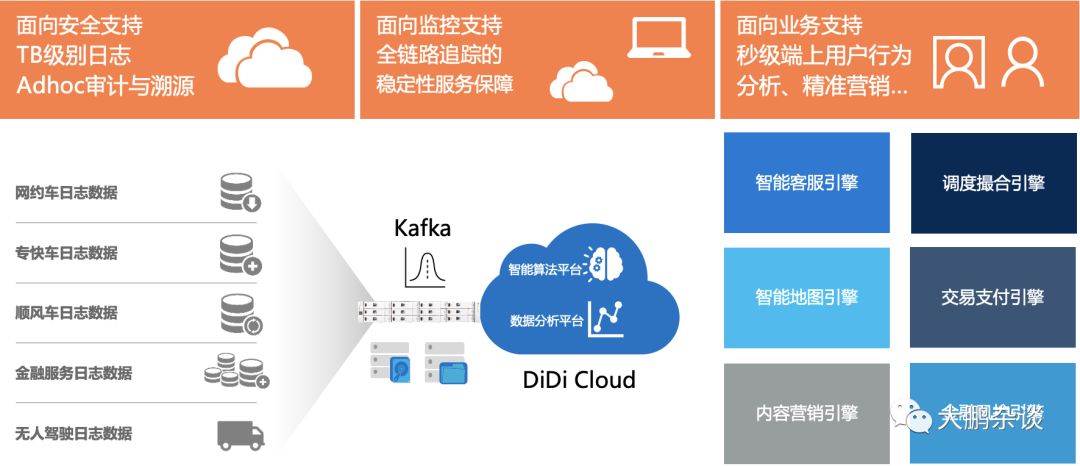
滴滴Kafka的使用规模应该算是在国内互联网领域里数一数二的企业,Kafka承载日增2PB的日志的流转和缓存,其下游要经受住100W + Producer同时写入数据,自身集群峰值可达 2000W/s,集群流量可达 30GB/s,集群中有2W+ topic、20+ cluster、单集群 370+ Broker,上游要对接3W+Consumer,最大数据消费可达600MB/s,面对这么大规模数据流转和分发虽然也会遇到因为Kafka磁盘IO热点导致的集群生产消费雪崩;或者因为Topic资源隔离差,流量突增、回溯消费,影响集群稳定性等问题,但终归还是满足了内部数据传输和交换的需求,助力企业过去9年业务高速发展,足以可见Kafka性能之强悍。
一、Kafka设计理念和演进思路
Kafka之所以在消息引擎方面性能如此出色,不得不说与其设计理念息息相关,Kafka在设计之初就旨在提供三个方面的特性:提供一套API实现生产者和消费者、降低网络传输和磁盘存储开销、实现高伸缩性架构,但Kafka并未止步于消息引擎,按照官方的说法现在Kafka即是消息引擎系统,也是一个分布式流处理平台(Apache Kafka is an open-source distributed event streaming platform)。
从2012年Kafka开源以来,短短3年间Kafka被越来越多的公司应用到他们企业内部的数据管道中,特别是在大数据工程领域,Kafka在承接上下游、串联数据流管道方面发挥了重要的作用:所有的数据几乎都要从一个系统流入Kafka然后再流入另一个系统中(Kafka Connect),这样的使用方式屡见不鲜以至于引发了Kafka社区的思考:与其把数据从一个系统传递到下一个系统中做处理,为何不自己实现一套流处理框架呢?基于这个考量,Kafka社区与0.10.0.0版本正式推出了流处理组件Kafka Streams,也正是从这个版本开始,Kafka正式“变身”为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









