






利用python抓取网页数据(省考数据)
以湖南省省考数据为例,将数据转换为表格
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 发起网页请求
url = 'http://rsks.hunanpea.com/Article/9fb511ff-0591-4164-85a1-ddbd101300ef/InternalArticleDetail.do'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 找到包含数据的表格
table = soup.find('table')
# 提取表格中的数据
data = []
for row in table.find_all('tr'):
row_data = [cell.text for cell in row.find_all('td')]
data.append(row_data)
# 将数据存储到Excel文件
df = pd.DataFrame(data)
file_path = 'C:/Users/rc/Desktop/rc/2023湖南省省考报名情况.xlsx'
df.to_excel(file_path, index=False)
else:
print('Failed to retrieve the webpage.')
运行结果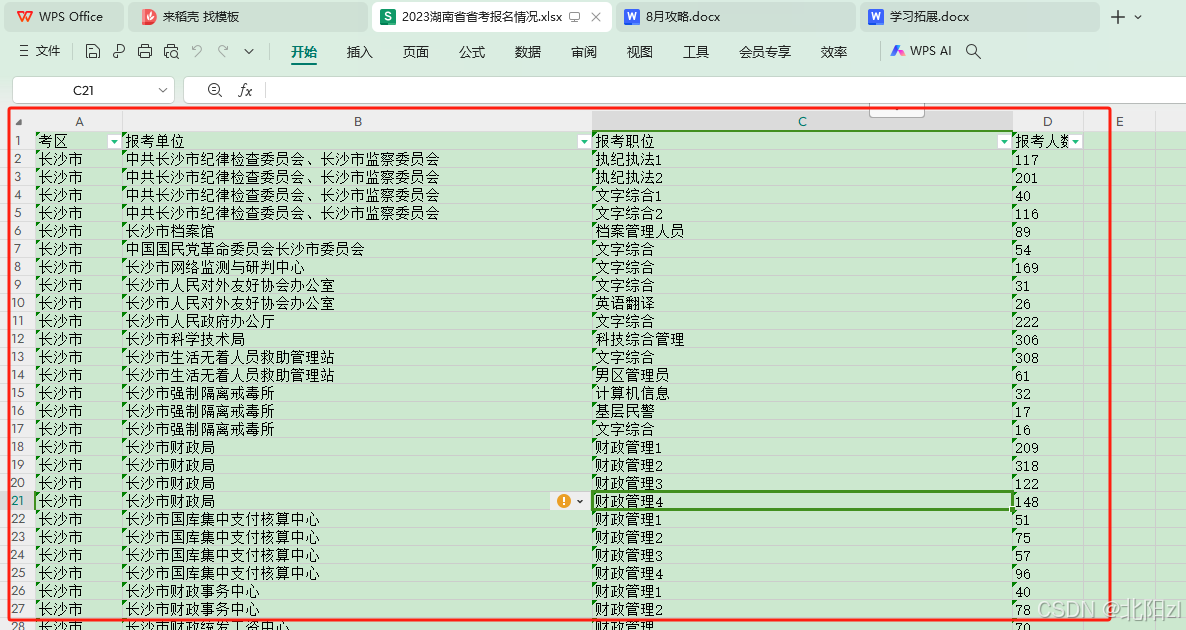

















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









